
ノイズデータが結果を破壊する

皆さんこんにちは。
ギャプライズ鎌田(@kamatec)です。
仕事柄様々な業種業界のABテストを年間1,000本以上見ているのですが、ABテストを回していると一番多いのが、
AとBの差がつかなくて勝敗がつけられない
というパターンです。
実際にOptimizely社が3億回以上のABテスト結果を調べたデータを見ても、ABテストにおいて成果が上がるテストは25%であり、約60%は「Inconclusive=未確定」という結果になるというデータが出ています。

またABテストに限らずとも、
・サイトをリニューアルしたらCVRが下がった
・大規模な改修をしたのに期待した程の効果が出なかった
という経験をしたマーケターの方は少なからずいるのではないでしょうか。
当然こういう状態に直面したとき、原因を究明し対策を考えるわけですが、それでも明確な原因にたどり着けないとき、1つの可能性として疑ってほしいのが、
ノイズデータの混ざった状態で分析している
というケースです。
今日はこのテーマについて、
・どのようなデータがノイズなのか?
・どのようにノイズを取り除き対策するのか?
という点について少し書いてみようと思います。
ノイズ=生態系の違う人が混ざっている状態
まず僕が最近感じることの多い、データにおける「ノイズ」というものがどんなものなのか、わかりやすい例として1つご紹介したいと思います。
以下のヒートマップをご覧ください。
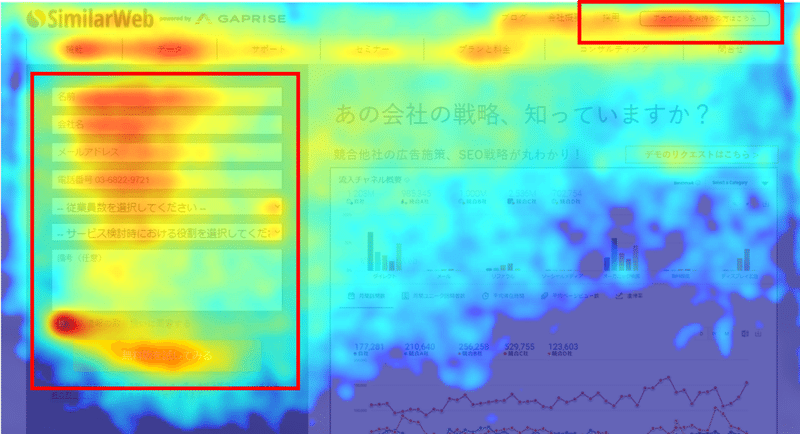
これは僕の会社のあるサービスサイトにおけるヒートマップです。
※ほんとは細かいクリック率とかも全部出るのですがそれはさすがに生々しいので伏せてます。
ざっくり説明すると、向かって左側が新規ユーザー向けの登録フォーム、右上にあるボタンが既存ユーザー向けのログインボタンです。
見ていただくと分かる通り、左のフォームを入力するユーザーとログインに流れるユーザーに2極化しています。
この状況を踏まえ、次にログインに流れたユーザーだけを分母にヒートマップを出してみます。それが以下です。
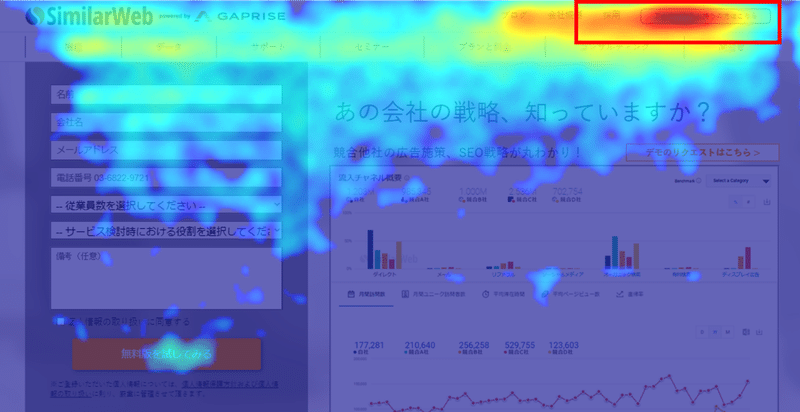
このようにログインユーザーは基本的にログインという行為以外は求めてないので、左側のフォームは一切触らず、上記のように右上に集まるような形になります。
このような状況はよくあるようで、かなり有名なBtoB向けSaaSのサービスサイトでは実に70%近くが既存ユーザーとの話しも聞いたことがあります。
で今日の本題に戻りますが、「ノイズ」というのは
分析したい対象に異なる生態系が混ざっている状態
を指しています。
具体的には、上記サイトを例にあげるのであれば、ログインユーザーが混ざっているサイトにおいて、
「新規獲得」を目的とした分析をしたいのに、「ログインユーザー」を除外せずにデータを見ている
というのがノイズの混ざった状態です。このような状態で分析を進めてしまうと色々な弊害が起こります。
例えば冒頭に上げたABテストの結果もその典型です。
一つ例を上げてみます。ABそれぞれ10,000人に対して「新規リード獲得」を目的としたABテストをTOPページに実施したとします。そのサイトのTOPページ流入において実は60%は既存ユーザーだったと仮定しましょう。
このような環境でコンバージョン数に以下のような差が出たとき、「全ユーザー」を分母とした場合と「新規ユーザー」だけを分母にした場合、以下のような状況になります。
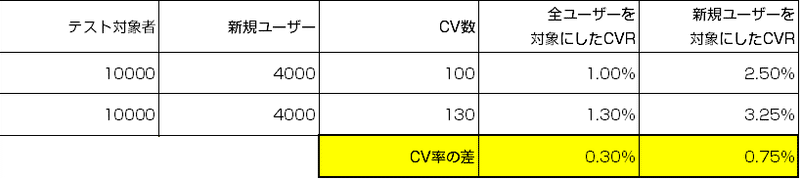
全ユーザーを対象として見ると0.3%の差だったCVRが、新規ユーザーを分母として見ると、実はその2倍以上の差が出ていたという事実に気づきます。
ABテストで一番多い
AとBの差がつかなくて勝敗がつけられない
という状況に対して、実は適切なセグメントをかけて分析すると明確な差が出ていたというケースは少なくありません。
このような形でノイズが混ざった状態のデータを見ていると実態と全く異なる解釈をしてしまったり、結果に到達できるまでのスピードが鈍化してしまう可能性があるのです。
離脱率や直帰率に関しても同様です。
上記のようにログインユーザーが多く、すぐ別ドメインに飛ぶような状態であれば直帰率は当然高くなります。
このような状態にも関わらず、ノイズの混ざったデータを見て「うちのサイトは直帰率が高い!」ということを課題に捉えたところで、その先にインサイトが見つかることなどないわけです。
ここまで読んで「何を当たり前のこと書いてんだ」と思った方もいることでしょう。
そんな方はこのページをそっと閉じていただければと思うのですが、なんでこんなことを書いているかというと、意識してみたら実はノイズが混ざってしまっているというケースは思ったよりも多いからなのです。
ログインユーザーなんかは比較的わかりやすい例ですが、生態系が違うパターンの一例を挙げると
・新規ユーザーとリピート購入ユーザー
・会員ユーザーと非会員ユーザー
・指名検索ユーザーと非指名検索ユーザー
なども生態系が大きく異なるケースがあるため、分けた方がいい可能性が高いです。
さてここまででノイズデータを分けて見ることの重要性を書きましたが、実際にはどのようなことを意識して分けるべきか、また分けた上でどのような施策を打つべきかについてもう少し書いてみようと思います。
限りなくシンプルに分ける
ではどのように実際に異なる生態系のデータを分けていくかというと、まずはともあれ
シンプルに分ける
これに尽きるのではないでしょうか。
具体的には以下@hik0107さんの公開されているスライドとnoteに丁寧に書かれていますので、こちらをご覧いただくのが良いかと思います。
(ちなみにこの記事中に「生態系が違う」という言葉が頻発してるんですが、それも上記スライドからインスパイアされる形で使用させてもらっています。ありがとうございます。)
実は僕自身このセグメントの分け方に関しては、過去複雑にしすぎたが故に何度も失敗しています。
具体例をいくつか上げますと、
・エリア別にわける→最終的にバス停の名前レベルまで分けたいとなり煩雑になりすぎて爆死
・流入キーワード別に分ける→LPが増えすぎてメンテが追いつかず、作業だけが増えて効果が追いつかず爆死
・YahooとGoogle流入で分ける→分けてはみたものの差が見つけられず爆死
※上記セグメントが絶対ダメなわけではないです。商材によっては効果的なケースもあるのであくまで一例。
セグメントについては結構皆さん考えやすいのか、意見を聞くといろんなセグメントのアイデアが出てくるのですが、とにかく最初は
「誰がどう見てもそれは別々に考えたほうがいいでしょ」
というレベルで分けて、それぞれに施策を実施するのが良いと思います。
また実施する施策に関してもまずは複雑に考えず、シンプルな施策を心がけたほうが結果が出やすいです。
例えば以下の記事では、ある保険会社におけるセグメント事例を紹介しているのですが、「新規」と「見積り済み非契約者」という2つの生態系が異なるセグメントにシンプルな施策を実施することで成果を出しています。
最後に
ノイズデータを排除すること、それぞれをセグメントして施策をうつことの重要性について書きましたが、実際の現場ではそもそも「分ける」ことに対する技術的ハードルを越えられない(解析ツールが分けれるように設定されてない、わかる技術者がいないetc)が故に、分けたくても分けて見れないとか、セグメント毎にページの出し分けが出来ないという所で止まってしまっている会社も多い印象です。
このセグメントを分けて対策するための実装方法についてもまた別の機会で書ければいいなと思ってます。
それではまた次回。
ギャプライズ鎌田(@kamatec)がお送りしました。
この記事が気に入ったらサポートをしてみませんか?