
クラスタリングについて

データのクラスタリングで「真のクラスターの数」が議論になることが度々あります.その理由として
クラスタリングアルゴリズムの多くは事前にクラスター数を決めておく必要がある
クラスタリングアルゴリズムを実施した結果が分析者の直観と一致しない
などが考えられます.アルゴリズムとしてはベイズ理論を用いた方法など(ある程度、自動的に)クラスタ数を決めてくれるものもありますが、そもそも「クラスター数」とはどのように決まるのか?を考えてみることはデータを分析する上で重要だと思います.
クラスタ数については例えば次の2つの立場を取れるのではないかと考えています.
モデリングとしてのクラスタ数または論理的に導くクラスタ数:データはクラスタをもつある統計モデルから生成されたという立場・考え方.あるいはクラスタ数は論理的に導出されたある指標を最大(あるいは最小)化することで定まるとする考え方.
データ分析/観察としてのクラスタ数:分析内容に応じてクラスタの粒度(サイズ)を定めるという考え方.
上記2つの考え方は決して独立ではなく、実際の分析は双方の知識や考え方を用いて行われますが、この2つの考え方を意識することはデータ分析を行う上で意義があると思います.
まず、モデリング・理論としてのクラスタ数について考えてみます.例えば確率密度関数を用いたクラスタリングの手法として混合正規分布がありますが、混合正規分布を用いる場合クラスタ数$${K}$$は予め定めておく必要があります(※1).
データの次元が低く、実際のデータ分布を直接見れる場合はある程度方針が立ちそうですが高次元データは分布を見ることが難しく、クラスタ数を事前に定めるのは簡単ではありません(もちろん次元圧縮を使って高次元でのデータ分布を観察することは非常に有効な方法です).
(※1)
クラスタ数をデータから定めるアルゴリズムも存在します。ただしこれらのアルゴリズムも何らかの基準(方針)があり、それに基づいてクラスタ数を決めます.したがってこの基準が何であるかを理解することは大事です.またアルゴリズムによってはハイパーパラメータをもっており、このハイパーパラメータによってクラスタ数が変化します(例えば変分ベイズ法).この場合、クラスタ数を直接決定するのではなくそのための基準(方針)を別のパラメータによって定めていると捉えることができます.
また具体的に分布が観察できる場合も例えば次の様な場合クラスタ数はいくつと考えるべきでしょうか.図1と図2は同じデータ分布で図1の左下のクラスタを拡大したものが図2になっています.


図1を見るとデータは2つのクラスタに分かれていると見れそうですが、拡大すると右下のクラスタがさらに2つのクラスタに分かれていると見ることもできそうです.このようにクラスタ数はデータの見方や粒度によって異なると考えることもできます.
より具体的なデータを使ったクラスタリング例を見てみます.表1は1750人の人が83個のアイテムの中で自分が欲しいと思うものにフラグ”1”を立てたアンケートの結果です[1].例えばU6の人はmansionやclothesを欲しいと考えています.

このアンケート結果を似たアイテムを欲しがるグループにクラスタリングした結果が図3です.ここでは混合ベルヌーイ分布と変分ベイズ法を用いています[2].変分ベイズ法では事前分布のハイパーパラメータ(図3のa,b)を調整することでクラスタリングの粒度を変えることができます.図3の上段はハイパーパラメータをなるべく大きなグループを抽出するように設定した場合の結果、下段は小さいクラスタリングまで抽出するように調整した場合です.
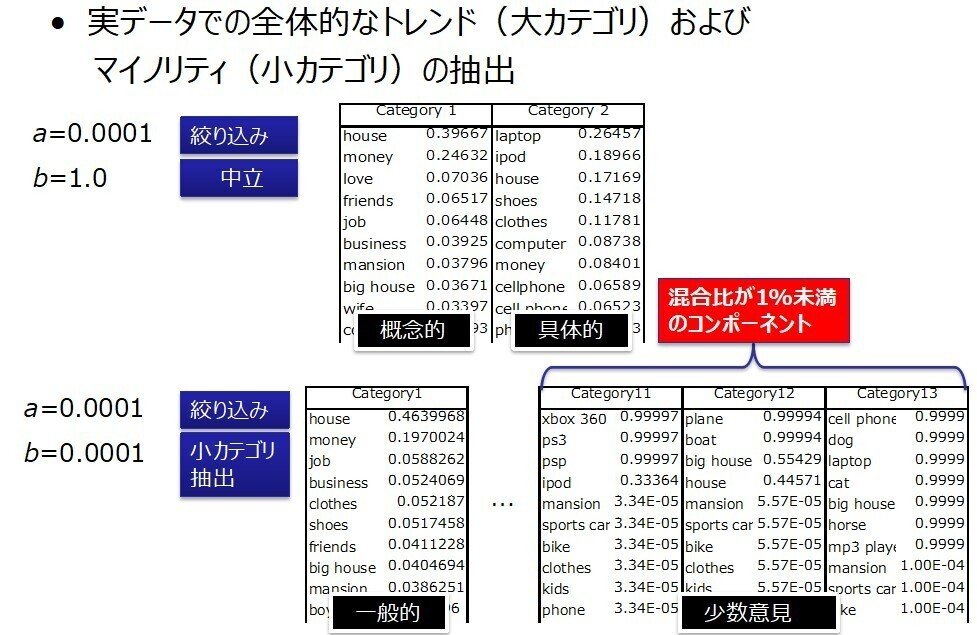
この結果を見るとクラスタリングの粒度によって見えてくるものが異なりそうです.2つの大きなクラスタに分割した上段は1つめのグループがお金、愛、友達といった概念的なものを求めているのに対して、もう1つのグループはラップトップ、ipod、靴、服など具体的なものを求めていて、求めるものに大きく2つの考え方があることが見てとれます.
一方、細かいクラスタまで見ていった場合、家、お金、仕事、服・・・といった一般的なものを求めている最大クラスタ(Category1)だけでなく、少数派で構成されるグループ、例えばxbox、ps3…といったゲーム機を求めるクラスタ(Category11)、飛行機、ボート…大きな家といった高価なものを求めるクラスタ(Category12)など特定の領域に特化したカテゴリを観察することができます.
このように実データを用いたクラスタ解析ではクラスタの粒度を変えることで見えてくる内容も異なり様々な角度からの分析ができるようになります.
そしてこの粒度に応じたクラスタ解析を行うためにモデルや理論を基礎にして培われた多くの手法が活躍します.
[1] Toby Segaran著, 當山 仁健、鴨澤 眞夫訳, 集合知プログラミング, 2008
[2] Daisuke Kaji, Sumio Watanabe, ``Optimal Hyperparameters for Generalized Learning and Knowledge Discovery in Variational Bayes ", International Conference on Neural Information Processing, Bangkok, Thailand, December 1-5, 2009
この記事が気に入ったらサポートをしてみませんか?