
【企業分析】Confluent(コンフルエント)

CFLT (NYSE)
時価総額: 64億ドル
株価: 22ドル
売上高: 387億ドル
営業利益:▲339億ドル
(2021年)
事業内容: リアルタイムデータの分析・処理のためのPlatformを提供
設立年:2014年、2021年上場
本社: 米国🇺🇸 カリフォルニア州マウンテンビューに
代表者: Jay Kreps (CEO)
従業員数:1,981人
概要
リアルタイム・データの分析・処理のためのプラットフォームを提供する企業。
Confluentは、Linkedinの元社員3人が2014年にスピンオフした。

Confluentは動き続けるデータに焦点を当て、リアルタイム・データの分析・処理のためのプラットフォームを提供する企業です。
2014年に設立された新しい会社でアメリカ、カリフォルニア州に本社を置き2021年にNasdaq市場にIPOを果たしています。
Confluentを利用することで、複数のソースからのデータを組織全体に送り、そのデータを利用してリアルタイムの顧客体験やデータ駆動型のビジネスオペレーションが可能となります。
例えば小売店がリアルタイムデータに基づく地域限定の価格設定やキャンペーンを即座に展開出来たりします。
その他、具体的には旅行サイトのExpediaはConfluentを利用することで様々なケースに対応できるリアルタイムのチャットボットサービスを立ち上げることが出来たそうです。
Confluentを利用することで小売り・エンタメ・金融業界では顧客の満足度を高めたり、製造業関係ではリアルタイムでオペレーションにデータを活かすことが可能となっています。
そのような形でCFLTのプラットフォームは小売り、ヘルスケア、金融、運送、旅行など様々な業界で活用され、2021年の3月には2,500社以上の顧客を抱えています。(21年9月末には3,000社を超えました。)

プロダクト・ビジネスモデル
プロダクト
プロダクト自体は二つあり、Confluent CloudとConfluent Platformになります。Platformはオンプレ(自社運用のサーバーやソフトウェアなど)に対応、Cloudはパブリッククラウド(AWS,Azure,GoogleCloudなど)に対応しています。

どちらもプロダクトの内容自体は同じでリアルタイム・データの分析・処理ができるプラットフォームとなっています。
続いてConfluentのプロダクトが解決する問題について見ていきます。
従来バッチやクエリを経てデータベースからデータを同期してましたがデータの多様化で限界が出て来て、タイムリーにデータを入手することが困難になってきました。さらに近年のデータ社会の拡大でデータを持つ媒体がデータベースだけでなく、APP、クラウドと増え続け、それぞれのデータを接続し、管理するのが困難になりました。


このような問題を解決するためにConfluentが生み出したのが上述のプロダクトで解決策は以下となっています。
クエリに合わせてデータをストリーミングすることにより、 データはリアルタイムで常に利用可能になり、企業は企業内のデータを継続的に処理できるようになります。さらに社内のデータベース、APP、クラウドにConfluentが接続することで、すべてのデータを管理可能になります。


Apache Kafka
Confluent の基盤となっているデータ処理ソフトウェア「Apache Kafka」は、同社の創業者らがリンクトインに勤めていた2011年に開発したプロダクトだ。
Apache Kafka はイベント・ストリーミング・プラットフォームであり、ストリーミングのデータ、つまりはっきりとした始まりや終わりのないデータを収集、処理、保存するために使用されます。
Kafka を活用すれば、1分間で数十億ものストリーミングイベントを処理することも可能。
Confluentは、オープンソースのApache Kafkaと運用ツールをパッケージ化し、Kafka周りのサポート含めて提供しています。RedhatがLinuxを有償で提供するのと同じビジネスモデルです。
Confluentのプラットフォームは、オンプレやパブクラで動作するConfluent Platformと、完全管理型のクラウド・ネイティブなSaaS製品であるConfluent Cloudを提供。
Kafkaの特徴は、ユーザーがデバイスにログインしたり、ボタンを押すたびに、リンクされたアプリやデータベースにその記録がほぼリアルタイムで送信されることだ。莫大なデータを持つ企業にとっては、アプリをより速く反応させたり、より大きなスケールに対応することができる。
顧客にはアウディも
ConfluentのCTOであるNarkhedeによると、自動車業界や金融サービスにおいてもテック企業のように大量のデータをリアルタイムで処理するニーズが高まっているという。Confluentの顧客であるアウディは、車両に搭載したセンサーから取得する膨大な量のデータを処理して予測診断を行っている。
また、銀行は、Confluentをデータストリーミングに使うことで、拒否された決済取引を機械学習モデルが誤ってフラグを立てし、顧客が大切なディナーでクレジットカードが拒否されることを防ぐことができるようになったという。
カナダの通信大手「Rogers Communications」では、メディアアプリでユーザーをトラッキングするのにConfluentを使用している。
課題
・クラウドサービスにどこまで注力できるか
継続的な成長にはConfluent Cloudの収益をどこまで上げられるかにかかっている
・マネージドサービスの導入
マネージドサービスのように顧客が細かいチューニングをすることなく、Confluent Cloudを使えるようにして欲しいところ。
現状は顧客毎にオプションを設定する必要があり、今後スケールさせていくには課題になりそう。
・オープンソース企業としての課題
他のオープンソース企業と同様の課題として、オープンソース・モデルは経営効率の改善が難しい。
①非GAAPベースの営業利益率が低い
②調整後EPSは大幅に低下
③フリーキャッシュフローが低い
このあたりをどう改善させていけるか。
ビジネスモデル
収益モデルは売上の殆ど(9割)はサブスクリプション+従量課金で、 残り1割はコンサル的なサービス収入となっています。
Confluent Platformが期間でのサブスクリプションでConfluent Cloudが従量課金となっています。
データ社会は今後の進化を続けていく見込みで、各々の企業が持つデータは今後も増えるでしょうからネットワーク効果により従量課金制のCloud売上はどんどん伸びることが期待されます。
実際Cloudは18~20年CAGR(年平均成長率)+250%で成長し、21年3Qも前年同期比+245%と猛烈な成長となっています。
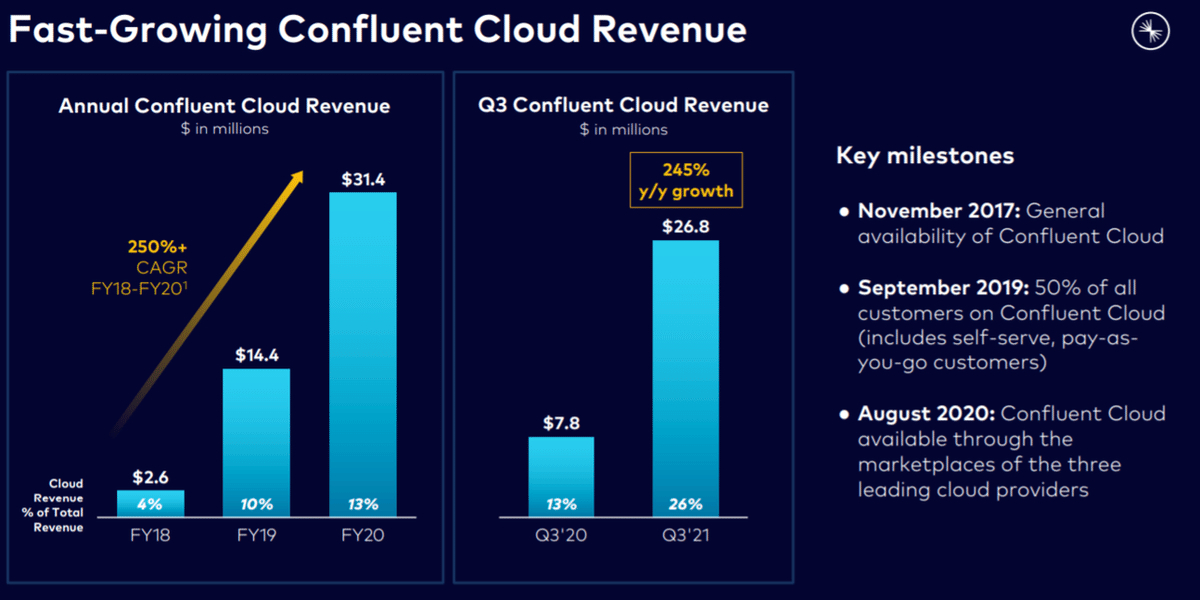
因みにPlatformとCloudの売上比率は64%:26%(サービス10%)です。
DatadogやSnowflake、Cloudflareもサブスク+従量課金ですが、データを扱う会社でサブスク+従量課金は非常にいいビジネスモデルだなと思いました。
NRR(Net Revenue Retention:既存企業の売上継続率) は130%ということでなかなかの高水準となっています。
小売り、ヘルスケア、金融、運送、旅行など様々な業界の顧客を抱え顧客数は3,020社超となっています。(前年比75%増)例えばNetflix、Unity、Paypal、Square、Robinhood、Walmart、Expediaなどアメリカ株投資を行っている方にはなじみ深い企業が顧客として名を連ねています。

海外展開も行っており、アメリカ外からの収入は35%となっています。
市場動向
ストリーミングソリューション市場
世界はますますリアルタイムに変化しており、ツイート、メッセージ、株式、銀行取引、ビデオ、オーディオなど、あらゆるものがストリーミング化しています。Confluentはこの変化を推進する企業です。
Apache Kafkaのようなストリーミングプラットフォームを利用することで、データを受け取ったときに、そのデータに対して操作を行うことができるようになります。
ディスクへの書き込みもないため、遅延なくリアルタイムにデータ処理が行えるのがメリット。
例えば、クレジットカード会社が不正行為を検知する場合、すべてのトランザクションの記録をディスクに保存し週末にバッチ処理を行い、1週間後に顧客に「不正行為がありそうです」と伝えるのと、リアルタイムに不正処理を検知し、即座に顧客に伝えるのとではCSに大きな差がでてきます。
また、ストリーミングソリューションは、リアルタイムでデータを再生できるし、アーカイブからのデータを再生することもできます。
例えば機械学習で、オブジェクトストアに保存されている過去のデータを学習し、その機械学習モデルをリアルタイムのストリーミングで分析を行うことができるため、機械学習市場が伸びればストリーミングソリューション市場も同様に成長が期待できます。
市場規模
IT調査会社のGartnerによるとConfluentのTAMは$50billion、CAGR22%で成長し24年には$91billionとなる見込みです。
ブレイクダウンはアプリケーションインフラストラクチャとミドルウェアで約31billion、データベース管理システムで7billion 、分析およびビジネスインテリジェンスで7billion、データ統合ツールおよびデータ品質ツールで4billionとなっています。

Confluentの売上は21年3Qが103millionで×4して年間の売上としてもTAM50billionの1%以下となっており巨大な市場と言えるでしょう。
競合
Confluent以外にもデータマネジメントのオープンソース技術を普及させようとしている企業はある。競合はKafkaのエコシステムだけでなく、外部にはアマゾンの「Kinesis」や「Apache Spark」などがある。
この市場のシェアではApache Kafkaがトップ。
業績


経営者
Apache Kafkaはストリーミング・プラットフォームを提供する Confluent の共同設立者兼 CEO。

Confluent を設立する以前は、LinkedIn のデータインフラストラクチャのリードアーキテクトを務めていました。Project Voldemort (キーバリューストア)、Apache Kafka (分散ストリーミングプラットフォーム)、Apache Samza (ストリーム処理システム) などのオープンソースプロジェクトの原作者の一人です。
Linkedinに在籍していたJay Krepsは、いくつかのミッションクリティカルな責務を担っていました。Linkedinの検索システム、レコメンデーションエンジン、ソーシャルグラフの技術的なリーダーであった。
Apache Kafkaは、Linkedinのようなリアルタイムのデータフィードを効率的に処理するためのオープンソースソフトウェアで、現在世界中で10万以上の組織で使用されています。
しかし、Kafkaが構築された2008年当時、開発者コミュニティ以外では、この製品を理解している人はほとんどいませんでした。
そのため、Kreps氏が2014年にLinkedInを離れ、「フルマネージドKafkaサービスおよびエンタープライズストリーム処理プラットフォーム」とされるConfluentを構築したとき、その意味を知る人は少なく、ミッションを信じる人はほとんどいませんでした。
クレプスや共同創業者のネーハ・ナルケデとジュン・ラオ(彼もLinkedInを退職し、Kafkaを共同開発した)にとっては、それでもよかったのです。彼は6年前に、世界で最も複雑なシステムやアプリケーションの一部に対して「一種の『中枢神経系』として機能することができる」と予測したイベントストリーミングのニッチ分野で、ゼロ日目からビジネスを成功させることを決意していました。
株価推移

記事をお読みいただきありがとうございます!^ ^もしよろしければご支援いただけると幸いです✨いただいたサポートはクリエイターの活動費に使わせていただきます!🙇♂️