UniFormを利用してSnowflakeからDatabricksのDeltaTableを読み込む

本記事は、 Databricks Advent Calendar 2024 シリーズ2の10日目の記事です。UniFormを利用してSnowflakeからクエリするまでの簡単な流れを書いています。
はじめに
noteで機械学習エンジニアをしている漆山です。
noteでは、データ基盤としてSnowflakeを利用しており、Snowflakeを利用してデータ分析をしています。
一方で、データ利活用の一つである機械学習に関しては、プラットフォームとしての利用しやすさやからSnowflakeではなくDatabricksを新たに採用しました。
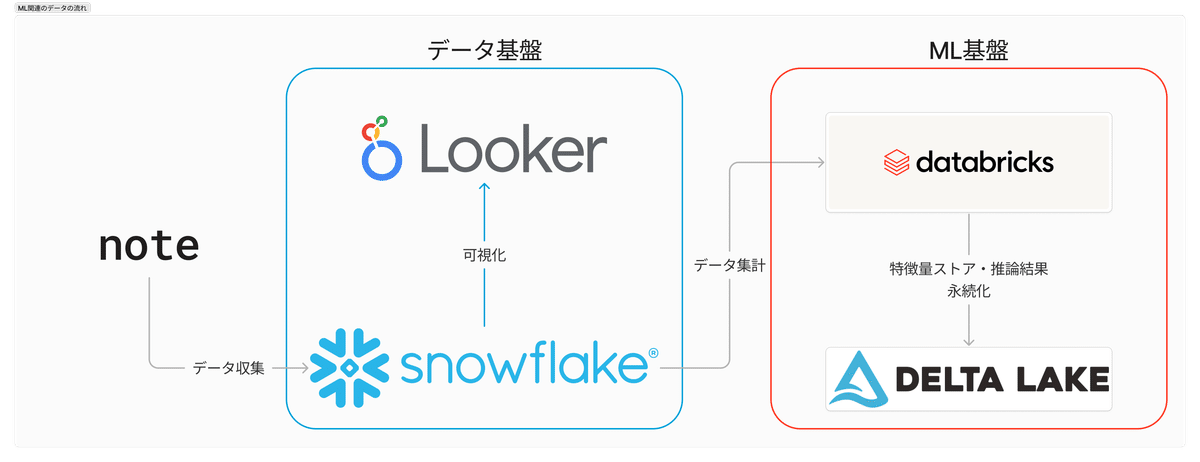
データ利活用の観点から分析のしやすさやガバナンスを考えると、データを一箇所にまとめておく方が望ましいです。そのため、データはSnowflakeに置いておくことが望ましく、Snowflakeのデータを利用する際にはLakehouse Federationを利用しています。現状ではMLエンジニアはSnowflakeとDatabricksの両方の使い方を知っておく必要があり、学習コストが高くなってしまいます。
MLエンジニアの成果物としては、MLを利用した推論結果の作成だったりMLそのもののEndpointであることが多いです。
DatabricksはSnowflakeよりもML Platformで使いやすく、MLエンジニアはDatabricksを使いこなすことで、高速に試行錯誤ができるようになってきています。
理想的には、MLエンジニアが仕事をしやすい状態を作りつつ、他の利用者がMLの推論結果を利用できることが望ましいです。
そこでUniForm形式の出番となります。UniFormはDatabricksが今年のData+AI summitで発表したDelta Tableの新しい形式です。
この形式で保存されたDelta TableであればIceberg Clientから読み込むことができるため、SnowflakeからSQLでクエリすることができます。

準備
UniForm形式で永続化されたテーブルを読み込むためには、いくつかの権限設定などが必要です。ここでは、DatabricksとSnowflakeがAWS上で利用されている想定でどんな準備が必要かを記載します。
SnowflakeのサービスプリンシパルをDatabricksに追加する
Snowflakeにカタログ統合を追加する
Snowflakeで利用するIAMロールを追加する
Snowflake に外部ボリュームを作成する
1. SnowflakeのサービスプリンシパルをDatabricksに追加する
Databricksのアカウント管理画面で、 "ユーザー管理 > サービスプリンシパル"画面に移動して、Service Principalを作成します。
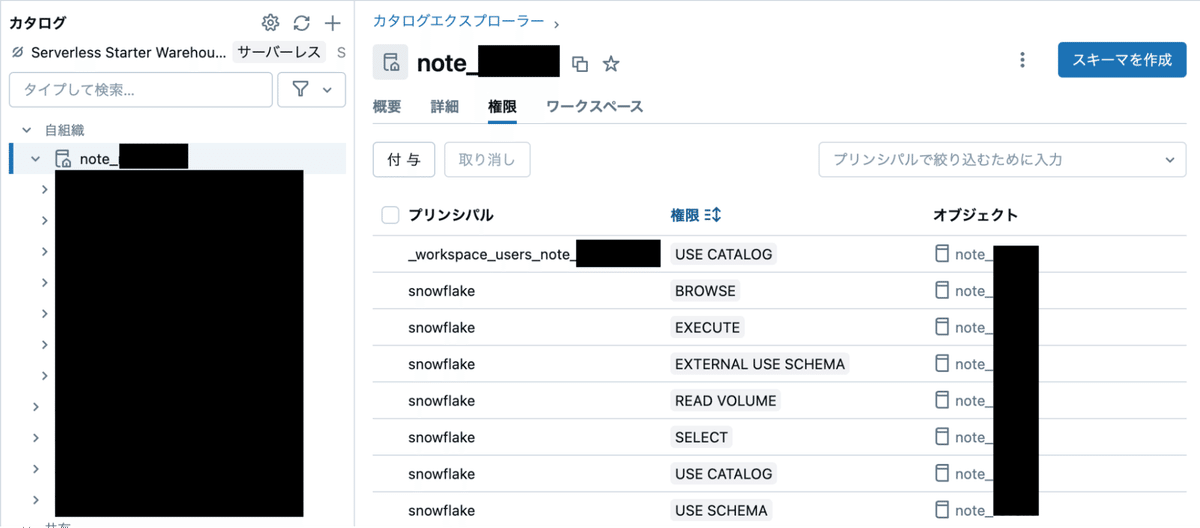
ここではSnowflakeというサービスプリンシパルを作成しています。

サービスプリンシパルを作成したら、Snowflakeから参照したいDelta Tableに参照権限を付与します。 「カタログ > 参照したいカタログ > 権限 > 付与」から権限が付与できます。
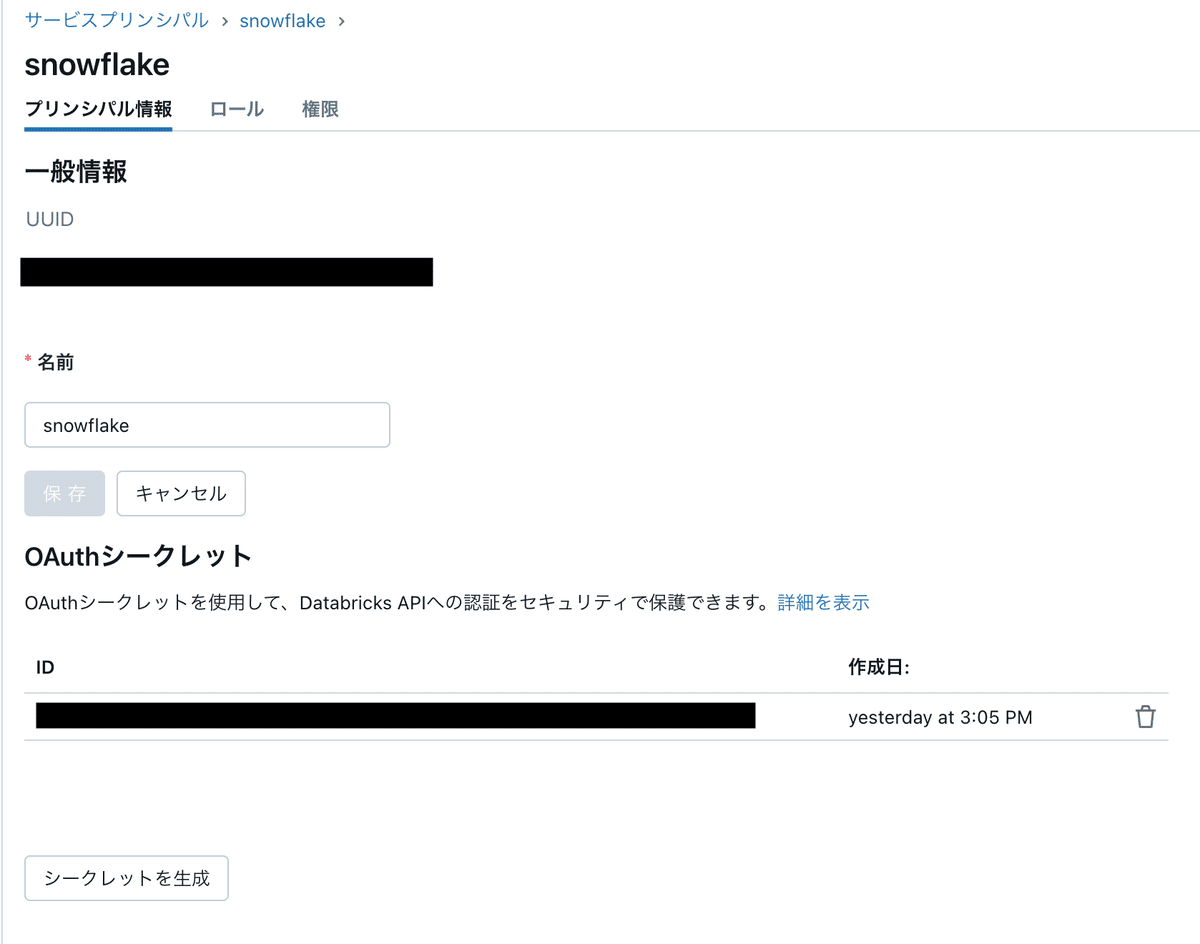
権限が付与できたら、次にDatabricks上にOAuthシークレットを作成します。
サービスプリンシパルの管理画面から、「シークレットを生成」をクリックする。
OAuthシークレットは一度しか表示されないので注意。
Snowflakeにカタログ統合を作成する
UniFormとして保存しているDelta TableはIceberg RESTとして読み取れるようになります。SnowflakeからUniForm形式のDelta Tableを参照するために、カタログ統合を構成します(Snowflakeのアカウント管理者の権限が必要)。
CREATE OR REPLACE CATALOG INTEGRATION <catalog-integration-name>
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'default'
REST_CONFIG = (
CATALOG_URI = '<workspace-url>/api/2.1/unity-catalog/iceberg',
WAREHOUSE = '<catalog-name>'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_TOKEN_URI = '<workspace-url>/oidc/v1/token'
OAUTH_CLIENT_ID = '<client-id>' -- 先ほど作成したOAuth token
OAUTH_CLIENT_SECRET = '<secret>' -- 先ほど作成したOAuth secret
OAUTH_ALLOWED_SCOPES = ('all-apis', 'sql')
)
ENABLED = TRUE;<workspace-url>はDatabricksのワークスペースのURLです。
<catalog-name>はDeltaTableのカタログの名前です。
Snowflakeで利用するIAMロールを作成する
Snowflakeが利用しているIAMロールに、Unity Catalogが利用しているS3バケットのARNを追加します。
S3のバケット名はUnity Catalogの「詳細」に表示されています。
詳細はSnowflakeのセキュアアクセスの構成を参照してください
Snowflakeの外部ボリュームを作成する
Delta Tableの読み込みにはSnowflakeの外部ボリュームが必要です。そのため、外部ボリュームを作成します
(カタログ統合と同様にSnowflakeのアカウント管理権限が必要)
CREATE OR REPLACE EXTERNAL VOLUME <external-volume-name>
STORAGE_LOCATIONS = (
(
NAME = '<ストレージロケーションの名前。識別できればなんでも良い>'
STORAGE_PROVIDER = 'S3'
STORAGE_AWS_ROLE_ARN = '<Snowflakeの IAM Role のARN>'
STORAGE_BASE_URL = '<Unity Catalog 詳細にある「ストレージの場所」>'
STORAGE_AWS_EXTERNAL_ID = '<aws_iam_policy_document.assume_snowflake_storage_integration に書いてある External ID>'
)
);UniForm形式のDelta Tableの作成
ここでは、Databricksからサンプルとして読み込めるニューヨーク市のタクシー移動データを利用します。
大まかな流れとしては以下の通りです。
1. SparkでDataFrameを読み込む
2. UniForm形式としてDeltaTableで書き込む
df = spark.read.table("samples.nyctaxi.trips")
df.write \
.format("delta") \
.option("delta.enableIcebergCompatV2", "true") \
.option("delta.universalFormat.enabledFormats", "iceberg") \
.saveAsTable(table_path)気を付けるポイントとしては、optionを2つ指定することです。
1. option("delta.enableIcebergCompatV2", "true")
2. option("delta.universalFormat.enabledFormats", "iceberg")
2. UniForm形式で保存されたDeltaTableを読み込む
2024/12/04時点で、UniForm形式のDeltaTableの更新をSnowflake側では自動で検知してくれません。そのため、DeltaTableの更新後、テーブルのリフレッシュが必要です。
CREATE OR REPLACE ICEBERG TABLE IF NOT EXISTS nyctaxi_trips
EXTERNAL_VOLUME = '<外部ボリュームの名前>'
CATALOG = '<カタログ統合の名前>'
CATALOG_TABLE_NAME = 'nyctaxi_trips'
CATALOG_NAMESPACE = '<カタログのネームスペース>';
ALTER ICEBERG TABLE nyctaxi_trips REFRESH; -- ICEBERG TABLEの更新上記のクエリではテーブルがなかった場合にはテーブルを作成して、その後テーブルをリフレッシュしています。
Delta Tableを更新した際には ALTER ICEBERG TABLE <table_name> REFRESHを実行してください。
ここまで実行がうまくいけばSnowflakeからUniForm形式のDelta Tableが読み込めるようになります。

終わりに
この記事では、UniForm形式で保存されたDeltaTableをSnowflakeからクエリするまでの手順を書きました。UniFormが発表されたばかりということもあり、この記事が他の人の役に立つことを願っています。
この記事を書くにあたって、さまざまな検証や協力をしてくれたchovさんとデータインフラチームにこの場を借りてお礼申し上げます。