
Amazon BedrockとRustでコーディングアシスタントを開発した

※ この記事はnote株式会社 Advent Calendar 2023の24日目の記事です。
(Amazon Bedrock Advent Calendar 2023 25日目の記事でもあります)
はじめに
普段は推薦チームでMLエンジニアとして働いています。普段はPythonを使ってコードを書くことが多いのですが、今回はAdvent CalendarのネタとしてRustとAmazon Bedrockを利用して、Grimoireというコーディングアシスタントを自作しました。
元々はPull Requestのコードレビューに特化させたツールを作る予定でした。
23日目のpr-agentの導入と競合していて、そのままだとつまらないと感じたこと、自分が普段感じているコーディングアシストへのモヤモヤを解消するために自分でもコーディングアシスタントを作成してみるかという気持ちで、ちょっと作ってみることにしました。
これは、個人で始めた小さなプロジェクトであって会社でのオフィシャルなプロジェクトではないことに注意してください
この個人プロジェクトではさまざまな人の協力いただきました。
会社でのAWSリソースを用意してくれているSREチームの皆様方
Bedrockの使い方やワークショップを開いてくれたり一緒にログを追ってくれたAWSの方々
日々生成AIの情報をウォッチして最新情報などを提供してくれているnote AI Creativeの方々
ここで感謝申し上げます。ありがとうございました!
コーディングアシスタントについて思うこと
自分が思うことについて書いているだけなので、興味がなければ飛ばしてください
Copilot…すごい…
エンジニアの方々はもはや手放せなくなっているGithub Copilot。
これの出来が非常に良くて、一部の人は最近の仕事は `tab` キーを連打することという人も一部いるのではないでしょうか。
「コードを書く」ということがかなり短縮されて、何かを作りたいと思っている人たちにとってとても強力なアシスタントだと思います。
特に、よくある典型的なコードなんかはほとんど自動で出力してくれますし、自分がわからないことでも書いてくれますよね。
GoogleやStack overflowで検索して欲しい情報を探すことがかなり減り、コーディングのやり方そのものが大きく変わったのだと思います。
自分が感じたモヤモヤ
Copilotが便利なことには変わりはないのですが、copilotを使ってコーディングするととてもモヤモヤしている自分がいることに気がつきました。そのため、すぐに使うのをやめてしまいました。
このモヤモヤの原因は何なのかなと色々考えていたのですが、以下の二つが自分のモヤモヤポイントでした
モノづくりとか個人開発が好きなのではなく、コードを書くと行為そのものが楽しい
コードを書きながら考えているので、copilotのautocompleteでコンテキストスイッチみたいなのが発生する
1 についてですが、コードを書く行為そのものが好きなのであって、何か動くものを作るとか特定のものを作るとかはそんなに好きではないんですよね。
開発が好きな人でも自分の作ったものが思った通りにいい感じに動いた!とか価値提供できた!というような何かを動くものを作って楽しんでる人が多いのではとか思ったりしてます。そういう人にとってはCopilotはショートカットを提供してくれていてとても楽しいんだろうなと感じたりしています。
自分の場合にはそれがあまりなく、むしろ動いたりすると興味がなくなったりそれが便利かとかにはほぼ興味がないです。動かない方が嬉しかったりします。
動かないものがなんで動かないんだろうなあというのを考えて仮説を立ててコードを書くことで試行錯誤するのが好きなので、Copilotはむしろ楽しみを奪って行ってるような感覚に陥ってモヤモヤを感じたりします。
2.についてですが、自分はコードを書くときにどうやったら動くかというのを考えていてタイピングをしています。そのときにCopilotは答えはこれと言ってコードを提案してくるのですが、どうしてそうなったのかの過程は分かりません。
自分の感覚として、何か入力するたびにPull Requestのコードレビューを都度する必要があり、コンテキストスイッチのようなものが発生している感じがします。
オフィスで集中しようとしていると話しかけられてイマイチ集中できないみたいなそんな感覚がしてモヤモヤすることがあります。
そんなこともあって、copilotは自分には合っていないなあという気持ちがあり、自分にとってのアシスタントとは何なのかを再定義してみることにしました。
noteのAIの考え方を参考に
弊社CXOのnote AIに対する考え方をベースに、AIに面倒な部分を引き受けてもらいつつ楽しいことを自分でやるためのコーディングアシスタントとは何なのかを再定義することにしました。
端的に言ってしまえば、自分の楽しいところというのは、何かを考えて仮説をコードとして表現し学びを得ることです。
なので、アシスタントに求めることは、考えるための情報を集めて整理することです。コードベースや公式ドキュメントにある情報をよしなに検索して整理して提供してくれればよく、別にコードを出してくれなくていいわけです。
Grimoide: 自分が考えるためのコーディングアシスタント
コードを生成するのではなく、人間がコードを書くために必要な情報を整理してくれるコードアシスタントとして、Grimoireという名前のコーディングアシスタントを作りました。
できることは以下の3つだけです。
1. Pull RequestのDescription の生成
2. Pull Requestの要約的なレビュー
3. codebase に関する質問と回答
Pull Requestに関すること
Pull RequestのDescription生成や要約的レビューにはGithub ActionsとAmazon BedrockのClaude v2を使ってコメントの生成をしています.

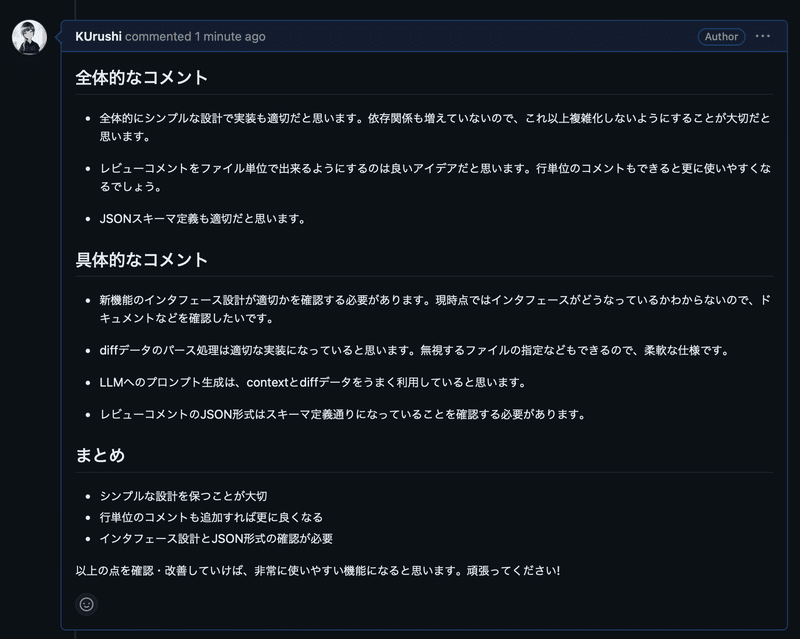
以下は動作確認のために実行してみた例です。
Githubのdiffのファイルごとにレビューするような機能のプロトタイプを作った時のPull Requestに対するDescriptionの作成と全体的なレビューコメントです。
PATを使って、個人のリポジトリで試した時の例なので、自分のコメントとして作成されていますが、全てLLMが自動生成しています。

コードベースの質疑応答
codebaseに関する質問と回答では、Amazon Bedrock, KnowledgeBase for Amazon Bedrock, Agents for Amazon Bedrockを使っています。
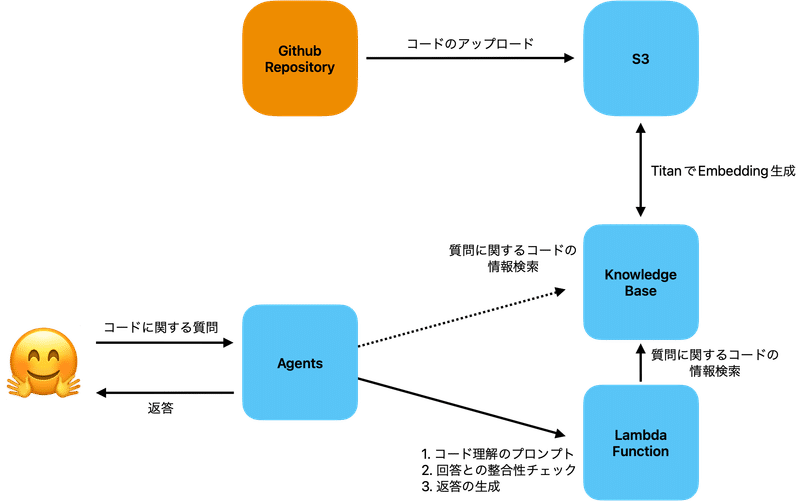
まず、事前準備としてコードをEmbeddingに変換してKnowledge Baseで検索可能にしておきます。手順としては
1. RepositoryをコードをS3にロードする
2. Knowledge BaseのSync機能でS3のコードをEmbeddingにする
です。Embeddingする際には、8Kトークンを処理可能なAmazon Titanを利用しています。ある程度のトークンが処理できるので、ファイル単位でEmbeddingをしています。
質疑応答は、Agents for Amazon Bedrockに質問して、Agentが回答を返すようになっています。
Agents for Amazon BedrockではKnowledge Baseを直接参照してくれるのですが、デフォルトのPromptだとKnowledge Baseのデータをわかる形で返答できないようにプロンプトで制御されています。
プロンプトエンジニアリングでどうにかなる範囲なのですが、 Action Groupを作成してみたいのもあって、Action Groupで制御することにしました
(この方法はWhere Are You Christmas? At Agents for Amazon Bedrock! 世界最速(?) Agent for Amazon Bedrock デモを参考にさせていただきました)
実際に動かすと以下のような感じで返答ができるようになっています。

Agentが回答を生成してくれていますが、実はこれ想定通りに動いていません。
この辺りは、おそらくはAgentの不具合にハマってしまっていて、回答生成のAction を呼べていません。
コードベースの情報は取得できているので、OrchestrationのLLMが最終的に回答を生成していて、Action側で回答を生成するということができていません。
(Action側で回答を生成する合理的な理由は大してないのですが、単純にやってみたかったというので生成するようにしています)
またここでは載せられないのですが、社内の自分が普段開発しているリポジトリの中にあった前処理のアルゴリズムについて尋ねたところ、数ステップの手順でこういうことをしているよという妥当な回答が返ってきました。
Embedding単体でもうまくいっている理由は、自分が触っているリポジトリが比較的小さくまた最近できたものでもあり、構造が複雑ではないことが一番の要因だと思っています。そのため、年月と共に培われたリポジトリやmonorepoなどでは、chunk分けをするとかastとグラフDBと連携するみたいなことが必要なのではと考えています。
Rustでの実装
bedrockの呼び出しやAction GroupとなるAWS Lambdaの実装を含めて、全ての処理はRustで書かれています。
Rustを選んだ理由は以下の3つです。
1. Rustを書きたかった
2. RAGやLLMのアプリケーションの勘所を学びたかったので、llamaindex やlangchainを使わないようにしたかった
3. (特に質疑応答は)普段使っているIDEやターミナルから実行可能にしたかった
1. については自分の興味関心の範囲であり、特になんてことはないです。
2. については、LLMアプリケーションを開発する際にはLangChainを使うことがデファクトスタンダードになりつつありますが、色々やれるようにした結果少し複雑になっているような気もします。LangChainを使わないという選択肢について述べている記事もあったりします。
この手のなんでもできるライブラリは、チュートリアル的な最初の一歩を楽にはしてくれるものの、チュートリアルを超えて何かを始める際には途端に複雑になります。
自分の場合では、LLMアプリケーションの開発の方法や気につけるポイントを学びたいと思っており、開発することを通じて何かの仕組みを学びたいという時には選択肢として適切ではないのかなとも思いました。
3. については、ブラウザ上で動かしているIDEで開発をしている場合を除いて、ターミナルや専用のアプリとして実行可能していると思います。
そのため、スムーズに作業をしていきたい場合にはそのツールを離れることなく実行可能であったほうが都合がいいと思っています。いちいちブラウザに切り替えるのは余計な作業なので、面倒だとも思います。
Rustを使ってCLI(Rust)とVSCode拡張(TS+Wasm)を同時にモノレポでリリースしてみましたというZennの記事を見かけたことや、Rust製SQLフォーマッタをnapi-rsを利用してVSCode拡張機能化という記事を見てRustで作ってWASM化して後でプラグインを作ったりできそうかなと考えたりしました。
また、ratatuiのようなTUIのクレートがあるので、Rustで書いておけばターミナルで使うにしろIDEのプラグインにしろ、やりやすいだろうと考えました。
とはいえ、結局のところここまでやるまでの余裕はありませんでした。
色々述べたんですが、基本的にはRustでやりたいというのが強いモチベーションであり、別にRustを使う合理的理由はないです。そのくらいRustはある意味で魅力的な選択肢であるとも言えます。
学び
Prompt Engineering
最近設立されたNote AI CreativeのメンバーがさまざまなPromptを横展開してくれたり、AWSの方々がAmazon Bedrockを利用してプロトタイピングをするWorkshopの開催をしてくださいました。改めてありがとうございます。
個人的に、今のところPrompt Engineeringで大事なことは以下の2点です。
テクニカルライティングの技術を学び、磨くこと
構造化プロンプトを使って、少しずつ改善する
1.「テクニカルライティングの技術を学び、磨くこと」というのが何気に一番大切なのではと考えています。最新のPrompt Engineeringのテクニックを学ぶことよりも、こっちの方が重要だと思います。
結局のところ、LLMであってもMLのモデルの枠組みの中のものなので、訓練とチューニングされたデータを超えて汎化することもないし、使われたデータと同じようなデータとしてPromptを入力する必要があります。
結局のところ、品質の高いデータはライティングスキルの高い構造化された文章として作成されているので、その文章に近くなるように作ってあげるのがいいのではと思っています。あくまで、素人の考えであることに注意してください。
2.「構造化プロンプトを使って、少しずつ改善する」
構造化プロンプトというのは自分が勝手に作って呼んでいる造語で、構造化ログから取ってきています。要するにテンプレート化されたPromptのことでAnthropicのClaude Prompt Engineering Techniqueで紹介されています。
個人的には、最初にこのプロンプトを全て埋めた後に、一部分ずつ変えていき、それぞれ評価していくのが一番良いと思います。
ハイパーパラメータチューニングと同じで、一度に複数のものを変えてしまうとどこを変えたことでうまくいったのかなどの評価も難しくなります。
単なるMLのハイパーパラメーターチューニングの方法論に落とせるようにしたほうが、試行錯誤しやすくなるのではと思ったりしてます。
LLMアプリケーションの評価とか
個人的にはLLMであってもきちんと開発用のデータとテスト用のデータきちんと用意したほうが良いと考えています。
LLMに解かせたいタスクとして入力されそうなデータを集めて、なるべく定量的に評価できるようにしたほうが良いです。
人間は汎化処理の能力が高すぎるので、一部の入力に最適化されたPromptに向かう可能性があります。そうなっていないかを確かめるには、結局のところデータを用意して定量的に評価できるようにしたほうがいいというのが個人的な結論です。定量的に評価する方法はなんでもいいような気もしており、LLMに評価させても良いと思っています。
一番重要なのは、入力されるだろうさまざまなケースのデータを集めるという点です。
LLMを利用したいケースというのは、データがないケースももちろんあると思うのですが、データが利用・評価可能な形で構造化されて整備されていないケースが多いと思っています。
特に社内で利用したいケースとかだと、個人に属人化されていて他の人ができない・わからない、プロセスとして整備されきっていない、とりあえずWikiのような社内のどこかにデータは溜まっているが、使えるようになっていないケースなどなど、データの利活用をするための環境整備がまだまだ追いついていない状況でなんとかしたいというケースなのではと思ったりしています。
LLMは強力なツールなのですが、ツールを使うための環境整備が追いついていないので、目に映るもの全てをデータと仮定してどう整理するかをみんなで考えていったほうがいいのではと思ったりしています。
Analytics Engineerだけに頼るのはもはや不可能だと思うので、誰でもデータを整備可能になる教育や仕組みを作成していく方向に向かっていくほうが望ましいのではと考えています。
研究して論文でも書いていない限りは、Prompt EngineerやLLMの専門のエンジニアよりもAnalytics Engineerとか業務整理に強いエンジニアを集めたほうが良いです。
Agents for Amazon Bedrockの開発
Agents for Amazon Bedrockに限らず自律的なエージェントシステムは開発の難易度もある程度あると思いますが、比にならないくらい検証も運用も難しいなあというのが触ってみた感覚としてあります。
実行順の制御が決定的にすることができないので、すべてのケースで特定の処理が必ず実行されるとは限らないことを念頭においておく必要があると思います。
少しだけ触った感じの今の理解で気をつけておくポイントは3点です(これも素人の理解です)
e2eの自動テストのようにテストする。
エージェントのthinkingと実行順を出力し、Agentの実行結果が妥当そうに見えても実行順を確認する
1.については決定論的にタスク実行の制御ができないというものについてのテスト方法の一つの解です。
幸いなことに、Agentは自然言語の入力に対して自律的にタスクを実行するものなので、llm使ってさまざまなテストケースを自動生成ができると思います。
重要なことはさまざまなシナリオケースを想定して検証すること、曖昧な入力の時にエージェントがどういう反応をするかを理解しておくことだと思います。
特にテストをするとなると具体的な入力があることを想定してしまうのですが、言語の入力はほとんどの場合で曖昧だと思うので、どう反応するかは確認した方が良いと思います。
2.についてはエージェントをデバッグ可能にして追跡可能にするために必要な要素だと思います。 thinkingでエージェントの意思決定の根拠を出力し、人間が判断できるようにします。Agents for Amazon Bedrockはデフォルトで考える根拠を出力してくれるのですが、Agentsの出力が全て表示されていて若干読みにくいことに注意してください。
また、Action Groupをどのような順序で実行したのかをトレースしておく必要があると思います。Actionを開発する時にはある程度実行順序を想定して開発されると思いますが、Agentがその程度に実行してくれるとは限りません。
想定通りに動いているか、または、どういうケースだと想定通りに動かないかを調べるのに十分な情報を集められるようにしておく必要があります。
Agentは人間が解釈可能な言語を利用してコミュニケーションをしてくれます。しかし、AgentがLLMで出力を生成する以上、それがハルシネーションなのかそうでないのかを確認する必要があり、そのためには実際にエージェントの出力以外に実際にやっていることをチェックする必要があります。
自分が作成した質疑応答のエージェントでは、特定のActionを実行してくれることを想定していましたが、Actionを実行せずにそれっぽい返答を返していました。
もちろん、実行したいタスクによって異なると思うのですが、たとえそれっぽいものが出力されても、Agentが想定通りに動いているとは限らないので実際にAgentが何をしたのかを確認しましょう。
個人的に一番感じでいるのは、このAgentの開発はMLOpsとも異なるスキルセットが必要な気がしています。そのため、本当にちょっとしたことから試していくのが良いと思っています。
アドベントカレンダーなので、エンジニアの方々が読んでると思いますので、Dailyのアジェンダの自動生成くらいから始めていくのがいいのではとか思ったりしました。
多くの人がGitHub issueやらプロジェクト管理ツールを使ってタスク管理をしているので、タスク管理の情報をKnowledge baseに集約して、各メンバーごとに「昨日やったこと」「今日やりたいこと」などをまとめてもらい、アジェンダを生成するみたいなところから始めると、Knowledge baseとAgentsの運用ノウハウが貯まると思います。
自動化したいタスクのうちプロダクションに関係なく、かつAgentの最終結果を人間が利用するようなもので、意思決定が目的ではないものから始めていくと負荷が小さい状態で始められるし生産性の向上にも寄与するのではと思ったりします。
AgentのAction GroupをRustで実行する際のtips
Action GroupのAWS Lambdaを実装する際のtipsです。
AWSのサービスでイベントドリブンなAWS Lambdaを実装する際には、lambda-events crateを利用して実装をするのが一般的というのが私の理解です。
lambda-events-0.13.0からAgents for Amazon BedrockのEventが追加されたので、以下のコードを使わなくてもcrateのものを利用すれば同様のことができます。2023/12/19時点でlambda-eventsはAgents for Amazon bedrockに対応しておらず、自分でイベントフィールドに合致したでシリアライズ可能なstructを作る必要があります。
例えば、以下のようなstructを利用すると、Action GroupでRustを利用可能になります。
use std::collections::HashMap;
use serde::{Deserialize, Serialize};
#[derive(Clone, Debug, Default, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "camelCase")]
pub struct AgentEvent {
pub message_version: String,
pub agent: Agent,
pub input_text: String,
pub session_id: String,
pub action_group: String,
pub api_path: String,
pub http_method: String,
#[serde(skip_serializing_if = "Option::is_none")]
pub parameters: Option<Vec<Parameter>>,
#[serde(skip_serializing_if = "Option::is_none")]
pub request_body: Option<RequestBody>,
pub session_attributes: HashMap<String, String>,
pub prompt_session_attributes: HashMap<String, String>,
}
#[derive(Clone, Debug, Default, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "camelCase")]
pub struct RequestBody {
pub content: HashMap<String, Content>,
}
#[derive(Clone, Debug, Default, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "camelCase")]
pub struct Content {
pub properties: Vec<Property>,
}
#[derive(Clone, Debug, Default, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "camelCase")]
pub struct Property {
pub name: String,
pub r#type: String,
pub value: String,
}
#[derive(Clone, Debug, Default, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "camelCase")]
pub struct Parameter {
pub name: String,
pub r#type: String,
pub value: String,
}
#[derive(Clone, Debug, Default, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "camelCase")]
pub struct Agent {
pub name: String,
pub id: String,
pub alias: String,
pub version: String,
}
/// Lambda functionのハンドラー関数
async fn agent_handler(event: LambdaEvent<AgentEvent>) -> Result<Value> {
todo!("Actionの実装をする");
}agent_handlerの処理は他の言語の処理と変わらないので、Exampleを例に実装すれば良いです。特に難しいことはないと思います。
Claudeについて
AWS Bedrock workshopでPromptのベストプラクティスなどを教えていただき感じたことですが、GPTと比較してClaudeはなかなかユニークな特色を持っていてそれがエンジニア目線で使いやすくなっているのではと感じました。
Anthropic Claude - Prompt Design大全でも紹介されていますが、XMLタグの構造に特に注目されて学習されています。入力の区切りがXMLだけで済むというのはエンジニアにとってわかりやすいのではと感じました。
GPTだとマークダウン記法とか区切りを書くというのは万人にとってわかりやすいとも思いますが、システムで扱うのであればXMLタグの方がパースしやすくて個人的には好きです。
また、stop_sequencesにxmlタグを指定することで、結果をコードでパースして出力の一部を提示するというのがやりやすいです。
Anthropicの公式のPrompt Guideに載っているテクニックの一つでGive Claude room to "think" before respondingで<thinking>タグと<answer>タグを利用して精度を上げる方法が紹介されていますが、<answer>部分だけを抜き出すというのが割と簡単に書けるので好きです。XMLタグを使いこなせばGPT-4と出力とそんなに変わらない感覚がします。
(なお、GPTでもXMLタグを区切り文字として利用できるようですが、注目してくれるかは不明です)
個人的に一番嬉しかったのが、トークン長の長さと安さです。コードを丸ごとプロンプトに埋め込んでトークン長が長くなっても比較的安価でちゃんと処理してくれるという安心感があります。GPTでももちろん処理してくれると思いますが、トークン長の長さを売りにしていることから、信頼度としては若干GPTよりも高めです。
ざっくりとしたタスクの説明を書いて、XMLタグで区切られた長い参照情報を書いて、詳細にやってほしいタスクを書いて<thinking>&<answer>で考えて出力させるという初回Promptを書くときの流れが確立できたのでだいぶ良かったかなという感じがします。
また、claudeに限った話でもないと思いますが、LLMのPrompt EngineeringのベストプラクティスはLLMを提供している会社のものを参照するのが一番良いと思います。
終わりに
簡単ではありますが、Rustでコーディングアシスタントを自作することで色々な学べることがありました。Amazon Bedrockはかなり簡単にLLMを利用することができる良いサービスだなと思います。Claudeはプロンプト中のXMLタグを重要視してくれるという特性上、コードでパースしやすいという利点もあります。出力もXMLタグをうまく使うことで、コード上で扱いやすいなとも感じます。
Agentを使い所は難しいですが、Knowledge base for Amazon Bedrockはかなり簡単にRAGに必要な近傍探索の処理を実装することができます(Opensearch Serverlessを利用するのでそれなりのお金がかかります)。
自分ではML Engineerとして働いているので、もう少し機能をもうちょっと拡張して特徴量を生成するためのSQLやJupyter Notebookの情報を整理して検索できるようにしたいなと思っています。
また、TUIで利用可能になるようにしていきたいなと思ったりしています。
個人の小さなサイドプロジェクトなので、細々と進めていこうと思います。
明日はAdventカレンダー最終日で、note CTO¬e AI Creativeの代表のkonpyuの投稿になります。サンタクロースのプレゼントのようにワクワクする何かが出てくると期待しているので、楽しみに待っていましょう。
▼noteエンジニアアドベントカレンダーはこちら
こっそりと追記
とても素敵な記事を見つけた。
https://sizu.me/naoya/posts/7vxkuwvowo0z
自分にとってもコードを書きながら考えに没頭するという行為は、ある種の救いでありそれらが蝕まれないようにしつつより没頭できるようにしたかったのかもしれない
この記事が気に入ったらサポートをしてみませんか?