
Teamsから社内利用できる、Web検索と独自データ検索付きのGPTボットを作る

はじめに
前回、Teamsから社内利用できるGPTボットを作りましたが、今回はWeb検索と独自データ検索機能もつけていきたいと思います。
独自データ検索は、CSVやPDF、社内ウェブサイト等も利用可能で、テキスト系の情報検索だけでなく、データベース接続もやります。
アーキテクチャ
今回のアーキテクチャは以下です。
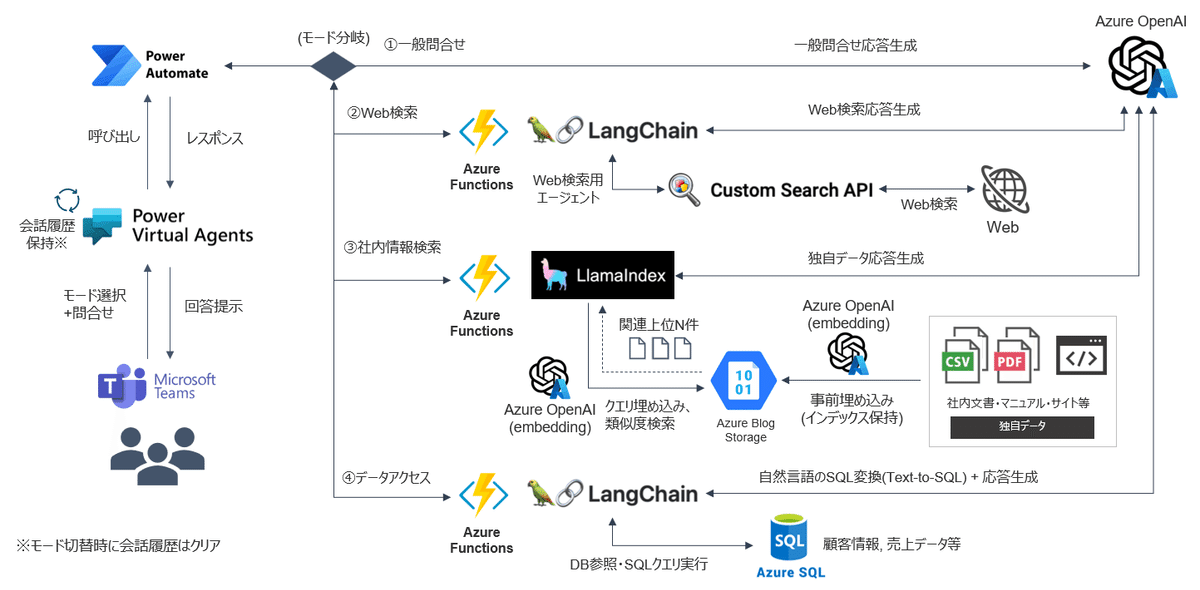
機能としては、「①一般問合せ」「②Web検索」「③社内情報検索」「④データアクセス」の4つを持たせ、ユーザーからのモード選択でそれぞれの処理へ分岐させています。
①一般問合せは、GPTとの直接のやり取りのため、PowerAutomateからそのままAPIをコールさせ、②Web検索は、GoogleのCustom Search APIを利用し、最新情報も取れるようにしています。
③社内情報検索は、テキスト系の社内情報を事前にインデックス化したものをAzure Blob Storageに保持しておき、LlamaIndexで類似文書を検索させます。
サイズの小さいCSV等の場合は上記で良いのですが、一定の量を持つデータの抽出や分析がしたい場合は、途中でチャンクに分割されると困るので、Azure SQL Databaseにデータを格納し、LangChainのText-to-SQLで処理させます(④データアクセス)。
Teamsから利用した実際のデモは以下です。
「①一般問合せ」デモ

こちらは個別の処理を呼ぶ必要がないため、PowerAutomateから直接Azure OpenAI ServiceのAPIを叩いています。PowerVirtualAgents側で会話履歴をメモリに持たせているので、文脈に応じた回答ができます。
「②Web検索」デモ

通常のGPTが持っていない最新情報についても、LangchainのエージェントがGoogleのCustom Search APIで検索した結果をこのように返してくれます。
「③社内情報検索」デモ
今回は、CSV2つとPDF, Webページを事前にベクトル化してインデックスを作成し、任意の問合せを行います。
それぞれ個別にインデックス化するのではなく、まとめてインデックス化した上で問合せを行います。
■CSVデータへの問合せ
今回はこちらの2つのCSVサンプルを利用します。


必要な箇所をそれぞれのCSVから抽出して回答できていますね。
■PDFデータへの問合せ
こちらは、経済産業省のレジ袋有料化に関するFAQのPDFを読み込ませます。全部で5ページほどありますが、そのままインデックス化します。


該当箇所を抽出し、質問の意図に合わせて回答してくれていますね。
■Webページへの問合せ
実際にやる場合は社内のWebページになると思いますが、今回は以下のIPAのDX認定制度のWebページを社内情報と見たててインデックス化し、任意の問合せを実施していきます。

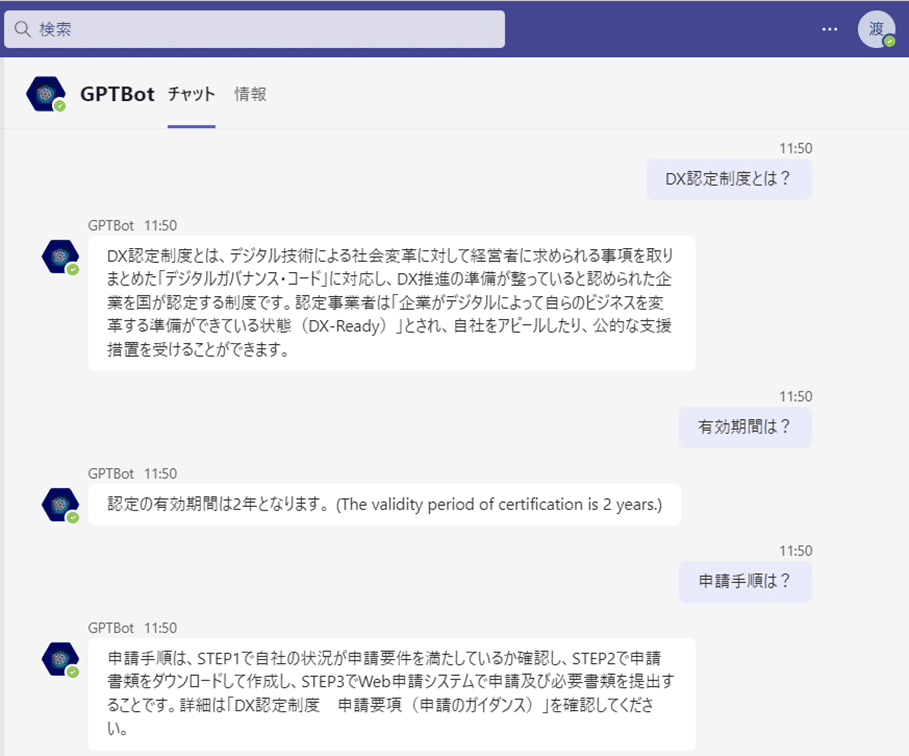
事前にインデックス化したWebページに対しても、上手く該当箇所の抽出と応答ができていますね。
今回はCSV2つとPDF、Webページをまとめてインデックス化しましたが、それぞれ情報が独立なため、問合せ内容に応じて必要なソースへアクセスできています。
今回はCSVとPDF, Webページをサンプルに実施しましたが、LlamaIndexは多くのデータコネクタを持つので、WordやPowerPointを含め様々なデータが接続できます。
データコネクタはLlamaHubから参照可能なので、自身が利用したいデータソースのコネクタがあるか、まずは調べてみるのが良いと思います。

「④データアクセス」デモ
先ほどのCSVは10-20行程度でしたが、今回はCodeInterpreterで生成した、1万件のダミーの顧客データを対象に問合せを行います。

上記のデータをAzure SQL Databaseに格納し、LangchainのSQLDatabaseChainで自然言語をSQLに変換してクエリさせます。

データベースに格納された1万件のサンプルデータに対しても、このようにTeamsから直接、自然言語で問合せができています。
ここは少しピンとこないという方もいるかと思いますので少し解説しておくと、以下のようにLangChainのSQLDatabaseChainを使う事で、問合せのテキストを対応するSQLに変換してクエリし、結果を返してくれます。
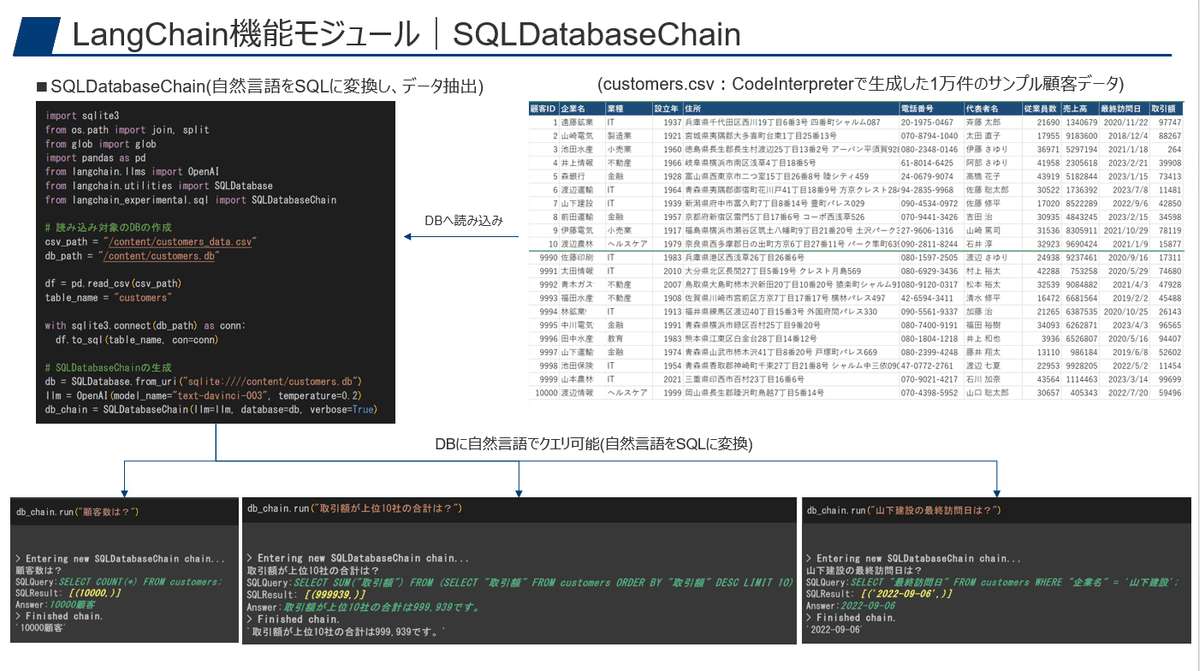
③のデモのように、テキスト的にチャンク分割したものから検索という形ではなく、テキストをSQLに変換する事で、必要なトークン数を大きく削減しながら、データベースの大量のデータに対しても容易にアクセスが可能になります。
結果の応答だけだと少し不安になる場合は、実際に叩いたSQLも含めてレスポンスに返す形にしても良いかもしれません。
まとめ
いかがだったでしょうか。
個人的には、様々なツールが乱立する中で、必要な機能がTeamsのUIに統合されていくのは非常に仕事がやりやすくなるのではないかと思います。
ベクトル化したテキストデータの検索に比べ、Text-to-SQLのDB検索は、問題設定が非常にシンプルになるため、正確性の面で実用性が高いなと今回特に感じました。
SQLを知らない方でも、テキストでDBのデータ検索ができるようになると、一気にデータの民主化と利活用が進むのではないでしょうか。
今回は問題を簡単にするために、ユーザーにモード選択させる形にしましたが、FunctionCallingで自動振り分けにしても良いかもしれません。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?