
AIを用いて橋梁床版の画像からひび割れ検出を行ってみた

※本ブログはAidemy Premiumのカリキュラム「AI アプリ開発講座」の一環で、受講修了条件を満たすために公開しています。
成果物の橋梁床版ひび割れ検出アプリは下記です。
https://aidemy-final-output-jn.onrender.com/
0. はじめに ~この題材を選んだきっかけ~
皆さま初めまして。著者は今ソフトウェアベンダーの技術営業として働いています。最近は会社も「AI」を大々的にアピールをしており、顧客へ提案する内容や、求められるスキルも変わってきていると感じています。今回Aidemyを受講したきっかけも、単にこうしたプログラミングに興味があったことの他、現在の業務にも活かせるのでは?と考えたことが挙げられます。
ちなみに大学の頃には土木工学を学んでおり、特に橋梁の研究を行っていました。折角なので橋に関する題材をと思い、ちょうどKaggleにもデータセットのあった橋梁のひび割れ検出を行ってみようと思いました。

約1.5kmものロングスパンを2本の主塔とケーブルで支えている
国土交通省の調査によると、全国に橋梁は約73万橋もあり、建設後50年以上を経過した2m以上の橋梁の数は、現在の37%から10年後には61%にまで上昇する見込みとなっています。*1
一方で、日本国内では少子高齢化や生産年齢人口の減少が叫ばれています。生産年齢人口は1995年をピークに減少しており、2050年までには2021年比で約30%も減少する見込みです。*2
すなわち、点検すべき橋梁は増える一方で、これをメンテナンスする人手の確保が難しくなっていく、という大きな社会課題に直面しています。特にインフラに関しては、近年の笹子トンネルの崩落事故に代表されるように、メンテナンスや補修の不備が多くの人命を奪う事故に繋がりかねません。
そこで登場するのがドローンです。ドローンは人がアクセスしにくい高所や狭隘箇所にもアクセスし、橋梁表面のひび割れの画像や動画などを取得でき、メンテナンス作業の効率化・安全性向上が図れます。しかし、結局人の目でひび割れなど判断していては、いつまでも人手がかかってしまいます。
そこで、画像認識により機械的にひび割れを検知できれば、大きな人手の削減が可能となります。「いままで人間がやっていたことを、いかにコンピュータに任せるか」がこれからの人手不足の時代には重要となります。
…といっても自身が今できることは限られています。まずAidemyの講座で学んだことを活かして様々な検証を行いましたので、お気軽にご覧ください。
*1: 国土交通省 - 道路施策の展開
https://www.mlit.go.jp/road/toukei_chousa/road_db/pdf/2023/16-1-1.pdf
*2: 総務省 - 令和4年 情報通信に関する現状報告の概要
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r04/html/nd121110.html
1. 訓練データの用意
Kaggle 橋梁のひび割れ画像
今回、正解付きの教師データセットとしてKaggleの"Structural Defects Network (SDNET) 2018 (Concrete Cracks Image Dataset)"を使いました。この中には、橋梁床版/舗装/壁のひび割れ有/無の画像が約56,000枚保管されており、それぞれのサイズは256x256です。画像群は影や表面の凹凸、スケール、エッジなど障害物を含んでおり、畳み込みニューラルネットワーク(CNN)を用いたひび割れ検出アルゴリズム開発に寄与するとされています。特にこの中でも特に橋梁床版のデータセットを使って、ひび割れ検出を行うこととしました。
なお橋梁床版のひび割れ画像の例として、下のようなものがあります。ひび割れ幅は0.06-25mmと幅広く、スケールが小さくなるほど、またひび割れ幅が小さくなるほど画像中でひび割れを認識しづらくなります。

ひび割れと認識しやすい画像の例

ひび割れと認識しづらい画像の例
2. CNNモデルの構築~事前準備編~
開発環境と注意点
Google Colaboratory
CNNモデルの構築、検証において利用しました。「ランタイム」>「ランタイムのタイプを変更」>「T4 GPU」を選択すると計算時間が格段に向上します。但し無料版だと制限があり、上限に達するとしばらくGPUが使えなくなってしまうので、注意が必要です(筆者は成果物作成前の1カ月だけProライセンスを使いました)。
Visual Studio Code(VS Code)
自身のPC環境でのCNNモデルの検証や、webアプリ製作用の.pyファイル、.html/.cssファイル作成に活用しました。pipコマンドで必要なライブラリ(numpyやtensorflowなど)を簡単にダウンロードできますが、使用しているCPUやtensorflowのバージョンによってうまくtensorflowが使えない場合があるので、注意が必要です。著者もこれで少し苦労しました。
Github/Renderのアカウント
これは特に問題なくアカウントを作成できました。
Google Drive への画像データの保管
Kaggleから直接Google Driveへ画像を一斉ダウンロードできます。Google Colab上でのコマンドは下記のとおりです。なおデータセットのダウンロードについては、下記リンクを参照しました。
#Goole Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
#Kaggle.jsonファイルを配置
!mkdir -p ~/.kaggle
!cp /content/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
#今回必要なデータセットをダウンロード
!kaggle datasets download -d aniruddhsharma/structural-defects-network-concrete-crack-images
#zipを解凍し、所定のフォルダに保管
!unzip structural-defects-network-concrete-crack-images.zip -d /content/dataset
!cp -r /content/dataset /content/drive/MyDrive/Aidemy_final_output保存された画像は"Decks", "Pavements", "Walls"それぞれのフォルダの下層に"Cracked", "Non-cracked"フォルダがあり、この中にデータセットの画像があります。すなわち「床版」「歩道」「壁」それぞれの「ひび割れ有り」「ひび割れ無し」の画像群が保存されていることとなります。今回はこの中で"Deck"すなわち床版のデータセットを用いて検証を行うこととしました。

3. CNNモデルの構築~構築編~
まずはハイパーパラメータ等は適当な値で、下記のコードによりひび割れ検知モデルの構築を行いました。
import os
import cv2
import numpy as np
import random
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, confusion_matrix
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
#学習する画像サイズを指定
img_size = 256
# 画像データのパスを設定 ここではDeckフォルダ内の画像でCracked/Non-crackedを学習
path_Cracked = os.listdir('/content/drive/My Drive/Aidemy_final_output/Decks/Cracked')
path_Non_cracked = os.listdir('/content/drive/My Drive/Aidemy_final_output/Decks/Non-cracked')
#画像を読込む順番を統一し、同一枚数となるようダウンサンプリング
random.seed(42)
path_Cracked.sort()
path_Non_cracked.sort()
path_Non_cracked = random.sample(path_Non_cracked, len(path_Cracked))
# 画像データと正解ラベル(cracked: 1/Non_cracked: 0)をnumpy配列に整理
img_Cracked = []
img_Non_cracked = []
for i in range(len(path_Cracked)):
img = cv2.imread('/content/drive/My Drive/Aidemy_final_output/Decks/Cracked/' + path_Cracked[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (img_size,img_size))
img_Cracked.append(img)
for i in range(len(path_Non_cracked)):
img = cv2.imread('/content/drive/My Drive/Aidemy_final_output/Decks/Non-cracked/' + path_Non_cracked[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (img_size,img_size))
img_Non_cracked.append(img)
X = np.array(img_Cracked + img_Non_cracked)
y = np.array([1]*len(img_Cracked) + [0]*len(img_Non_cracked))
# 訓練データと検証データを準備
np.random.seed(42)
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形に
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# input_tensor の定義
input_tensor = Input(shape=(img_size, img_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vgg16 に追加するモデルを定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16 部分の重み更新は固定(19層目まで)
for layer in model.layers[:19]:
layer.trainable = False
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# 作成したモデルで学習を実施
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=256, epochs=30)
# epoch毎の予測値の正解データとの誤差を表示
train_loss=history.history['loss']
val_loss=history.history['val_loss']
train_accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
epochs=len(train_loss)
plt.plot(range(1,epochs+1), train_loss, marker = '.', label = 'train_loss')
plt.plot(range(1,epochs+1), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plt.plot(range(1,epochs+1), train_accuracy, marker = '.', label = 'train_accuracy')
plt.plot(range(1,epochs+1), val_accuracy, marker = '.', label = 'val_accuracy')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 予測値を出力
y_pred = model.predict(X_test)
#混合行列の出力
y_pred_labels = np.argmax(y_pred, axis=1)
y_true_labels = np.argmax(y_test, axis=1)
cm = confusion_matrix(y_true_labels, y_pred_labels)
true_positive = cm[1, 1]
false_positive = cm[0, 1]
true_negative = cm[0, 0]
false_negative = cm[1, 0]
# 各結果の割合を計算
print("偽陰性率", false_negative/(true_positive+false_negative))
print("偽陰性割合", false_negative/(true_negative+false_negative))コードの解説
学習する画像のサイズ
#学習する画像サイズを指定
img_size = 256Kaggleのデータは256x256であり、今回学習する「ひび割れ」という特徴は画像サイズが小さくなると消失してしまうことを懸念し、デフォルトの256x256のまま進めることとしました。
先に登場したひび割れを認識しやすい/しづらい画像データにおいて、サイズを256x256/128x128/64x64/32x32とそれぞれ変えた結果は下記です。128x128であれば特徴は判別できそうですが、64x64/32x32となるとひび割れの特徴が周辺の凹凸と似通ってきて、うまくひび割れの特徴を学習できないことが想定されます。
# 画像サイズの違いによるひび割れの特徴の見え方を確認
import cv2
import numpy as np
import matplotlib.pyplot as plt
img=cv2.imread('/content/drive/My Drive/Aidemy_final_output/Decks/Cracked/7001-60.jpg')
size=[256, 128, 64, 32]
for i in range(0,4):
img_resized = cv2.resize(img, (size[i], size[i]))
plt.subplot(2,2,i+1)
plt.imshow(img_resized)
plt.title(str(size[i]) + 'x' + str(size[i])+'px')
plt.axis('off')
plt.show()

学習する画像枚数のダウンサンプリング
# 画像データのパスを設定 ここではDeckフォルダ内の画像でCracked/Non-crackedを学習
path_Cracked = os.listdir('/content/drive/My Drive/Aidemy_final_output/Decks/Cracked')
path_Non_cracked = os.listdir('/content/drive/My Drive/Aidemy_final_output/Decks/Non-cracked')
# 画像を読込む順番を統一し、同一枚数となるようダウンサンプリング
random.seed(42)
path_Cracked.sort()
path_Non_cracked.sort()
path_Non_cracked = random.sample(path_Non_cracked, len(path_Cracked))"os.listdir('/content/drive/My Drive/Aidemy_final_output/Decks/Cracked')"により、Google Drive上のCrackedフォルダ内の画像にアクセスすることができます。今回、"Cracked"、すなわちひび割れ有りの画像は2,025枚あるのに対し、"Non_cracked"、すなわちひび割れ無しの画像は11,595枚もあります。学習に偏りを持たせないため、また再現性を保つため、"random.seed(42)"にて乱数を固定したうえで、"Non_cracked"の画像数が"Cracked"と同じになるよう、ランダムに画像を間引いています。
画像と正解ラベルの配列作成
# 画像データと正解ラベル(cracked: 1/Non_cracked: 0)をnumpy配列に整理
img_Cracked = []
img_Non_cracked = []
for i in range(len(path_Cracked)):
img = cv2.imread('/content/drive/My Drive/Aidemy_final_output/Decks/Cracked/' + path_Cracked[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (img_size,img_size))
img_Cracked.append(img)
for i in range(len(path_Non_cracked)):
img = cv2.imread('/content/drive/My Drive/Aidemy_final_output/Decks/Non-cracked/' + path_Non_cracked[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (img_size,img_size))
img_Non_cracked.append(img)
X = np.array(img_Cracked + img_Non_cracked)
y = np.array([1]*len(img_Cracked) + [0]*len(img_Non_cracked))
Xにひび割れ有り/無しの画像群を、yにラベルを追加(ひび割れ有り:1、ひび割れ無し:0)しています。Xについて、それぞれの画像は画素数とRGBで(256, 256, 3)の要素を持つ多次元配列です。今回はひび割れ有り/無しそれぞれ2,025枚のデータを含むので、Xは(4,050, 256, 256, 3)の要素を持つ多次元配列となります。numpyはこうした多次元要素を取り扱うことが得意なライブラリであり、特に多次元を持つ画像の取扱いに優れています。
訓練データと検証データの用意
# 訓練データと検証データを準備
np.random.seed(42)
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]一つ前までに作成した画像/ラベル群ですが、このままでは前半がひび割れ有り、後半がひび割れ無しときれいに分かれた配列となっています。そこで、(乱数を固定し)X/yそれぞれをランダムに並べ替えたうえで、全データの8割を訓練データ、2割を検証データとすることで、いずれのデータ群にもランダムにひび割れ有り/無しの画像が配置されます。
正解ラベルをone-hotの形に
# 正解ラベルをone-hotの形に
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)今回はひび割れ有り(ラベル:1)/無し(ラベル:0)という二分類問題であり、ラベル配列の各indexは1か0の単一の値を持つだけでしたが、one-hotとすることで、例えばラベル:0の場合には[1, 0]、ラベル:1の場合には[0, 1]と変換します。今後出てくるクロスエントロピー損失関数や出力層のsoftmax関数はそれぞれのラベルとなる確率を算出しており、ラベルがone-hot関数となっていることで適切に損失の計算や予測値算出ができます。
VGG16の転移学習を利用したCNNモデルの構築
# input_tensor の定義
input_tensor = Input(shape=(img_size, img_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vgg16 に追加するモデルを定義し、結合
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16 部分の重み更新は固定(19層目まで)
for layer in model.layers[:19]:
layer.trainable = False学習モデルの構築においては、ここがキーポイントとなってきます。以降の検証でも、この学習モデル自体の修正も行っています。
まずはinput_tensorによって、入力画像のテンソルを定義します。ここでは、最初に設定した画像サイズimg_size=256(px)、カラーチャネルが3(RGB)のデータを入力することを定義しています。
続いてvgg16モデルのロードですが、"include_top=False"によって最後の全結合層を除外、"weights='imagenet'"によってImageNetで事前学習された重みを使用することを意味します。また最後の"input_tensor=input_tensor"によって、入力する画像のテンソルを指定します。
vgg16に追加する全結合層の定義ですが、ドロップアウト層を追加して、50%のニューロンを無効にし過学習を防止しています。また、最後に2ユニットの全結合層を追加し、活性化関数をsoftmax関数とすることで、2クラスの分類問題を解決するためのモデルとしました。なおsoftmax関数は3以上の多クラス分類問題でも活用でき、逆に2クラス分類問題であれば、sigmoid関数を使うことができます(この時、出力層は1ユニット)。
最後に、vgg16と追加モデルを統合し、一部重み更新を固定します。
vgg16はImageNetの画像群から一般的な画像の特徴(エッジ、テクスチャ、形状)を既に学習したモデルであり、新たなデータセットに対しても効果的な特徴抽出が可能です。またこうした学習済モデルを活用し、重み更新を固定することで、計算資源の削減にもつながります。
モデルのコンパイル
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])コード上はさらっと書いてしまっていますが、少し数学的に考察してみようと思います。
loss='categorical_crossentropy'
これは損失関数を'categorical_crossentropy'、すなわちクロスエントロピーとする、という意味です。損失関数について簡単に言うと、予想から遠ざかるほど損失が大きくなり、予想に近づくほど損失が小さくなるような関数、ということになります。クロスエントロピー関数は式で表すと下記です。
$$
Loss = -\sum_{i=1}^{C} y_i \log(p_i)
$$
例えば2クラス分類問題で、one-hotラベルがy=[0, 1]、モデルの予測確率がp=[0.3, 0.7]の場合、損失値は下記となります。この値を小さくすることを目指します。
$$
Loss = - (0 \cdot \log(0.3) + 1 \cdot \log(0.7)) = 0.3567
$$
optimizer=optimizers.SGD(lerning_rate=1e-4, momentum=0.9)
これは学習においてSGD: 確率的勾配降下法を用いて損失関数を最小化する、ということです。SGDの他Adam等もあります。イメージは下記です。

図の青線が損失関数(ここではクロスエントロピー関数)、赤線が学習の過程です。SGDでは、あるエポックで学習をした後、次に向けて損失を最小化するように、「損失が小さくなる方向≒傾きが小さくなる方向」に向けて次の学習を行います(傾きとは微分なので、関数の微分が登場します)。
ここで、「次の学習に向けてどのくらい一気に進むか」というステップ幅が"learning_rate"、すなわち学習率です。学習率が大きいと、一気に損失を小さくできるため早期の収束が可能となる一方、学習率が大きすぎると発散してしまう恐れもあります。逆に、学習率が小さすぎると安定して損失の最小化が進むものの、収束に時間がかかるという懸念があります。下記で、緑線が学習率が大きすぎる場合、黄線が学習率が小さすぎる場合です。

また、学習の都度損失の最小化に向け降下する方向が異なると、学習の過程で振動が発生し、収束が遅くなる可能性があります。そこで"momentum"、すなわち「慣性」を設定することで、更新の都度その時の勾配の影響だけを考慮するのでなく、前の学習の勾配の影響も考慮することで、収束を早める効果があります。
matrics=['accuracy']
ここではモデル性能を評価する指標を設定しています。今回は"accuracy"、精度で評価を行っていますが、この他"Precision"(適合率)、"Recall"(再現率)なども設定できます。
構築したモデルを用いた学習の実行
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=256, epochs=30)構築したモデルを用いて実際に学習を行っていきます。今回はbatch_size=256, epochs=30でまずは学習を行っています。
学習の過程を可視化
# epoch毎の予測値の正解データとの誤差を表示
train_loss=history.history['loss']
val_loss=history.history['val_loss']
train_accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
epochs=len(train_loss)
plt.plot(range(1,epochs+1), train_loss, marker = '.', label = 'train_loss')
plt.plot(range(1,epochs+1), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plt.plot(range(1,epochs+1), train_accuracy, marker = '.', label = 'train_accuracy')
plt.plot(range(1,epochs+1), val_accuracy, marker = '.', label = 'val_accuracy')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])こちらは学習過程の表示だけなので詳細は割愛しますが、学習の過程でまだ学習の余地があるか、学習/検証データの間で大きな乖離が無いか(過学習を起こしていないか)を確認し、ハイパーパラメータの修正等を行いました。
モデルの性能評価
# 予測値を出力
y_pred = model.predict(X_test)
# 混合行列の出力
y_pred_labels = np.argmax(y_pred, axis=1)
y_true_labels = np.argmax(y_test, axis=1)
cm = confusion_matrix(y_true_labels, y_pred_labels)
true_positive = cm[1, 1]
false_positive = cm[0, 1]
true_negative = cm[0, 0]
false_negative = cm[1, 0]
# 各結果の割合を計算
print("偽陰性率", false_negative/(true_positive+false_negative))
print("偽陰性割合", false_negative/(true_negative+false_negative))モデル上では'accuracy'、すなわち精度での性能評価を実施していましたが、別の指標での性能評価もするため、混合行列の出力や独自指標の設定を行いました。すなわち、単純に「予測を外した」といっても、「本当はひび割れが無いのに、ひび割れ有りと評価した(偽陽性)」場合と、「本当はひび割れが有るのに、ひび割れ無しと評価した(偽陰性)」場合では、後者の方が安全上でのインパクトが大きいことが考えられます。そこで、独自に下記2指標での評価も行うこととしました。これらは小さいほど良いものです。
偽陰性率 = FN/(TP+FN)
「陽性のうち何割を見逃したか」という指標です。
偽陰性割合 = FN/(TN+FN)
「陰性と判断したもののうち、何割が実は陽性だったか」という指標です。
結果の考察
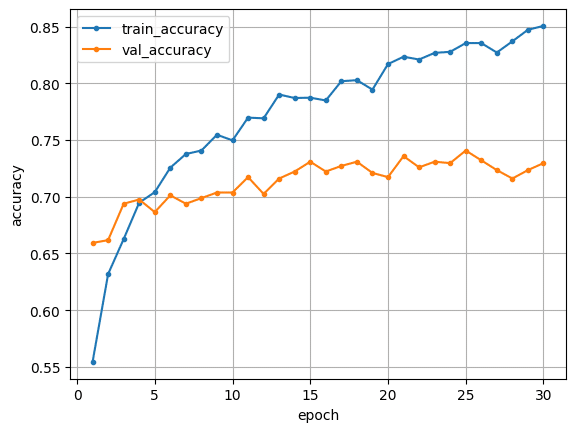
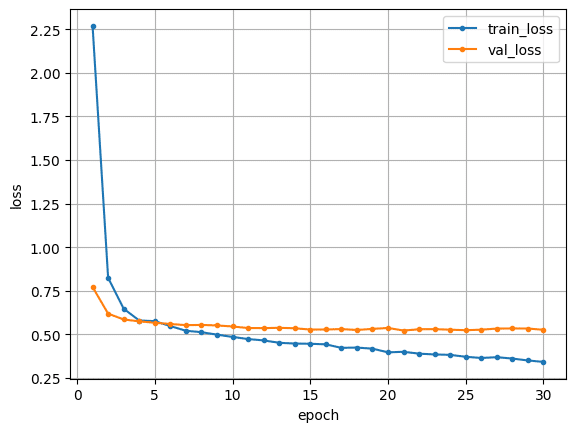
こちらのプログラムで回した結果は下記のようになりました。こちらをデフォルトとして、以降の検証を進めました。epochs=30では訓練データ側はまだ収束しておらず、epoch数を増やせばもう少し改善しそうですが、一方で検証データ側は既に収束しているように見え、かつ訓練データ側と乖離があることから、過学習を起こしていると考えられます。そこで、以降の検証ではこうした過学習を無くした学習を進める方法を検証することとしました。
精度:0.7296
偽陰性率:0.3117
偽陰性割合:0.2691
4. CNNモデルの構築~検証編①~
ハイパーパラメータ等の調整
以下では、様々なハイパーパラメータを調整したモデルの性能をデフォルトのケースと比較することにしました。まずは単純なパラメータの影響を調査するため、変更したパラメータ以外のパラメータは敢えてそのままで比較を実施しています。その後、変更する必要があると判断したパラメータを全て変えたモデルを最終版のモデルとして、再度モデルの性能評価を行うこととしました。
パターン①:epoch数:30->50
# 作成したモデルで学習を実施
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=256, epochs=50)3. にて検証を行ったものはepochs=30であり、既に検証データ側は収束しているように見えますが、まだ改善する可能性もあったため数を50まで増やして再度検証を実施しました。
結果が下記ですが、精度に多少の改善が見られたものの、やはり訓練/検証データ間で開きがあり、過学習が起きていることが予測されます。現段階において、epoch数を増やすことはモデルの改善に繋がらないと判断しました。
精度:0.7418 (デフォルト:0.7296)
偽陰性率:0.3169 (デフォルト:0.3117)
偽陰性割合:0.2624 (デフォルト:0.2691)


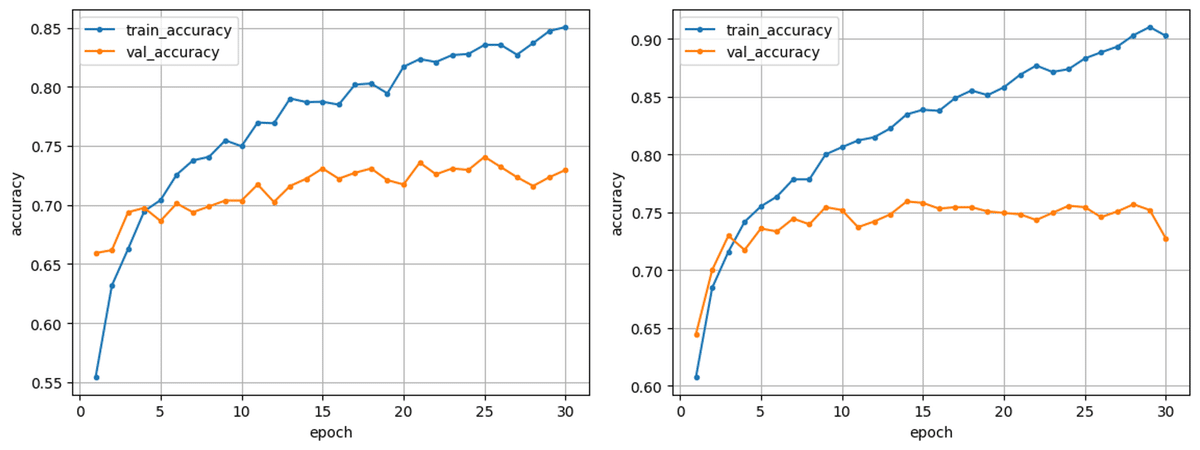
パターン②:batch size:256->64
→512パターンもあり
# 作成したモデルで学習を実施
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=64, epochs=30)一般にバッチサイズを小さくすることで、一度に行う計算量が減るためメモリ使用量が小さくなるほか、学習によるパラメータ更新がより頻繁に行われ、学習が早く進むといった効果がある一方、一度に学習する画像群が少なくなることで、訓練データ全体の分布を反映できず、画像群特有のノイズにより収束が遅くなる可能性があります。今回訓練データとして与えている画像群はそれぞれ大きな差異があるわけではなく、比較的類似したものが多いため、ノイズの影響は小さいと考えバッチサイズを小さくしました。
結果は下記です。精度は変わらないものの、偽陰性率は大きく下がりました。バッチサイズを小さくすることで、精度自体はさほど変わらないものの、より安全側に設計されたモデルとなったことが分かりました。現段階でその要因は定かでないものの、バッチサイズを小さくすることによる効果は期待できると仮定しました。一方で、やはり訓練/検証データ間で乖離が大きく、過学習を起こしていることが予測されます。
精度:0.7272 (デフォルト:0.7296)
偽陰性率:0.2208 (デフォルト:0.3117)
偽陰性割合:0.2273 (デフォルト:0.2691)

パターン③:VGG16 転移学習時の重み更新固定層数:19->15
# vgg16 部分の重み更新は固定(15層目まで)
for layer in model.layers[:15]:
layer.trainable = FalseVGG16はImageNetで一般的な画像の特徴を学んだモデルであり、これ自体は1000クラス分類問題を解決するモデルですが、VGG16の転移学習を用いることでこうした一般的な特徴抽出の恩恵を受けつつ、追加で全結合層を追加し、新たな分類問題に適応させることができます。
ここで重要となるのが、VGG16の重み更新を固定する層の数です。全ての層、すなわち19層全ての重み更新を固定すると、ImageNetでの学習の恩恵を最大限受けられますが、一方で新たな分類問題のための特徴抽出が不十分になる恐れがあります。そこで重み更新を固定する層の数を15層とすることで、下記VGG16のうち"block5"層が新しい分類問題に適応した特徴抽出を行ってくれることになります。

結果は下記です。精度が向上していることが分かります。すなわち前述のとおり、ImageNetの学習では今回の「ひび割れ」という特徴を抽出できていなかったために、重み更新の固定を一部外すことで、より今回の分類問題に適応したモデルとなったと判断できます。一方で、依然として訓練/検証データ間で乖離があり、過学習を起こしていると判断されます。
精度:0.7926 (デフォルト:0.7296)
偽陰性率:0.2363 (デフォルト:0.3117)
偽陰性割合:0.2069 (デフォルト:0.2691)


パターン④:追加全結合層数増加 1->2
# vgg16 に追加するモデルを定義し、結合
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))ここではVGG16に追加する全結合層を1層から2層に増やしました。目的としてはパターン③と同様で、今回の「ひび割れ検出」に特化し、より高度な特徴抽出を行うためです。なお、2層目のニューロン数は64で、過学習防止のためDropout層も追加しています。
結果は下記です。今回はepochs=30ですが、学習が収束しておらずまだ改善の見込みがあります。さらに特筆すべき点として、検証/訓練データ間で大きな乖離が見られないことです。追加層数を増やしたことで、学習に時間がかかるものの、より汎化された「ひび割れ」の特徴抽出を進められそうだと判断しました。
精度:0.7309 (デフォルト:0.7296)
偽陰性率:0.3012 (デフォルト:0.3117)
偽陰性割合:0.2642 (デフォルト:0.2691)


パターン⑤:学習率 固定値(1e-4)->変動値
# lerning_rateをスケジューリング
from tensorflow.keras.callbacks import LearningRateScheduler
def lr_decay(epoch):
initial_learning_rate = 1e-4
decay_rate = 0.1
decay_steps = 10
learning_rate = initial_learning_rate * decay_rate ** (epoch / decay_steps)
return learning_rate
lr_scheduler = LearningRateScheduler(lr_decay)
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# 作成したモデルで学習を実施
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=256, epochs=30, callbacks=[lr_scheduler])最後に、学習率の変更を行いました。学習率は前章のコンパイルのところで少し触れましたが、大きすぎると発散の恐れが、小さすぎると学習に時間がかかる恐れがあります。
また、epochsの増加と共に学習率を小さくする、というスケジューリングが可能です。学習の初期段階、すなわちまだ最適解まで距離がある場合は大きなステップで次に進み、学習の後期段階、すなわち最適解に近づいた場合はステップ幅を狭める、というもので、安定した学習が可能です。今回は「10回の学習毎に学習率を0.1倍にする」という指数関数を用いて学習率を徐々に小さくしました。
結果は下記です。精度自体は大きく変わりませんでしたが、訓練データ側の精度が悪くなり、訓練/検証データ間での乖離が小さくなった(≒過学習の程度が小さくなった)ことが分かります。単一の学習率で進めた場合、学習の後期段階においても訓練データに過剰にフィットした最適解に陥っていたものが、学習率を逓減したことでこれを防ぐことができたと考えられます。過学習の防止のため、学習率の逓減には効果があると判断しました。


精度:0.6963 (デフォルト:0.7296)
偽陰性率:0.3688 (デフォルト:0.3117)
偽陰性割合:0.3067 (デフォルト:0.2691)
結果の考察
デフォルトで設定した値では、ひび割れの特徴を正しく抽出できていないこと、またこれにより訓練データに過剰にフィットした、過学習なモデルが構築されていたと想定されます。そこで、パターン③によるVGG16重み更新固定層数の削減、及びパターン④による追加全結合層数の増加により、より今回のひび割れ検知に適応したモデルを構築できる、またパターン④やパターン⑤で学習率を逓減することにより、より今回のひび割れ検知性能を汎化できると考えました。
5. CNNモデルの構築~修正編①~
パラメータの調整
前章の検証を基に、下記の調整を行ったうえで改めてモデルを構築し、検証を行いました。モデル構築部分の最終的なコードは下記のとおりです。
パターン②:batch size:256->64
パターン③:VGG16 転移学習時の重み更新固定層数:19->15
パターン④:追加全結合層数増加 1->2
パターン⑤:学習率 固定値(1e-4)->変動値
# input_tensor の定義
input_tensor = Input(shape=(img_size, img_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vgg16 に追加するモデルを定義し、結合
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16 部分の重み更新は固定(15層目まで)
for layer in model.layers[:15]:
layer.trainable = False
# lerning_rateをスケジューリング
from tensorflow.keras.callbacks import LearningRateScheduler
def lr_decay(epoch):
initial_learning_rate = 1e-4
decay_rate = 0.1
decay_steps = 10
learning_rate = initial_learning_rate * decay_rate ** (epoch / decay_steps)
return learning_rate
lr_scheduler = LearningRateScheduler(lr_decay)
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# 作成したモデルで学習を実施
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=64, epochs=30, callbacks=[lr_scheduler])結果は下記のとおりです。精度としてはデフォルトより約7%程度高く、ちょうど8割程度であり、また訓練データとも大きな乖離が無く、過学習の可能性も低いモデルが構築できたと考えられます。一方で、偽陰性率、偽陰性割合共に数字が悪化してしまいました。
精度:0.8012 (デフォルト:0.7296)
偽陰性率:0.3688 (デフォルト:0.3117)
偽陰性割合:0.3067 (デフォルト:0.2691)


結果の考察
ひび割れが有るのに無しと判断してしまった(偽陰性)ケース
偽陰性率、偽陰性割合共に数字が悪化した原因として、「ひび割れがあるのにひび割れがないと判断した(偽陰性)ケースが増加した」ことが考えられます。そこで、誤った予測をした画像を集計してみました。画像集計部分のコードは下記のとおりで、画像タイトルに「ひび割れと予測した確率」が記述されています。保存された画像は下記からご確認いただけます。なお、"y_pred"はそれぞれの画像のラベルが"0"(ひび割れ無し)である確率と"1"(ひび割れ有り)である確率(当然その和は1となる)を持った配列であり、確率が大きい方のラベルが予測値として出力されます。今回は、ラベル"1"すなわちひび割れと予想された確率をタイトルに記載しています。
# 保存先のパスを指定
save_dir = "/content/drive/My Drive/Non_Crack_Misclassified"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 予測値をnumpy配列に
y_pred_array = np.array(y_pred)
# 正解が「1(ひび割れ有り)」でかつ予測が「0(ひび割れ無し)」の画像を抽出し保存
for i in range(len(y_pred_labels)):
if y_pred_labels[i] != y_true_labels[i] and y_true_labels[i]==1:
p=np.round(y_pred_array[i,1],4)
plt.imshow(X_test[i])
plt.title(f' p={str(p)}')
save_path = os.path.join(save_dir, f'Non_crack_misclassified_{i}.png')
plt.savefig(save_path)
plt.close() 保存された画像はいずれもひび割れ有りとラベルが付いたものですが、画像を見ていただいたら分かるとおり、いずれも「そもそもひび割れがあるのか?」と人間の目でひび割れを判別できないものや、あるいはひび割れ自体ではなくその周りに特徴的な模様があるものが多くありました。こうした特徴を持つ画像が少なく、うまく学習できていなかったことが原因と考えられます。しかし逆に、偽陰性であった画像の原因・特徴が明らかになったということは、それだけひび割れの特徴を正しく抽出したモデルを構築できたことの裏返しとも言えるため、決して悲観するものではないと感じました。

高い確率でひび割れであると判断したケース
一方で、下記は「ひび割れである」と高い確率(>0.9)で予測した画像を集計したコードと実際の画像です。目視でもはっきりとひび割れと分かるような画像がほとんどであり、今回構築したモデルは(大きな)ひび割れの特徴を抽出する、という目的を十分に果たせるモデルであると考えられます。
# 保存先のパスを指定
save_dir = "/content/drive/My Drive/Highly estimated cracks"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 予測値をnumpy配列に
y_pred_array = np.array(y_pred)
# ひび割れがある確率が0.9以上と判断された画像を抽出し保存
for i in range(len(y_pred)):
if y_pred_array[i,1]>0.9:
p=np.round(y_pred_array[i,1],4)
plt.imshow(X_test[i])
plt.title(f'pred={y_pred_labels[i]}, true={y_true_labels[i]}, p={str(p)}')
save_path = os.path.join(save_dir, f'Highly estimated cracks_{i}.png')
plt.savefig(save_path)
plt.close()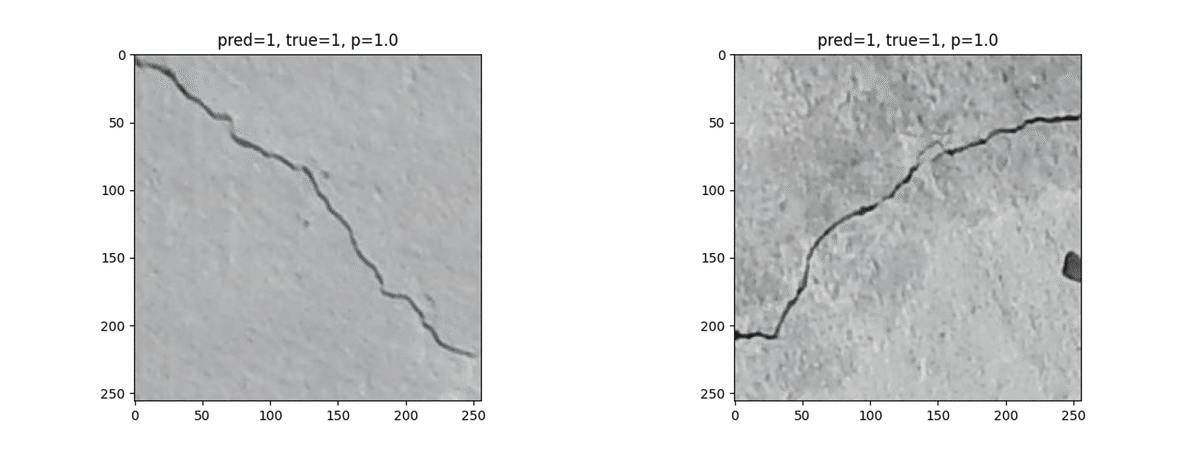
その他、予測を外したケース
最後に、予測を外したものを集計したコードと画像が下記です。偽陰性と判断してしまったケースの他、偽陽性と判断されたケースとして、例えば床版の境界部で、画像中にコンクリート以外が写っている画像などがありました。こうした画像も数が少なく、「コンクリート以外の何某かである」という特徴の抽出が行えなかったために偽陽性となったと考えられます。
# 保存先のパスを指定
save_dir = "/content/drive/My Drive/Misclassified"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 予測値をnumpy配列に
y_pred_array = np.array(y_pred)
# 予測を外した画像を抽出し保存
for i in range(len(y_pred_labels)):
if y_pred_labels[i] != y_true_labels[i]:
plt.imshow(X_test[i])
plt.title(f'pred={y_pred_labels[i]}, true={y_true_labels[i]}')
save_path = os.path.join(save_dir, f'misclassified_{i}.png')
plt.savefig(save_path)
plt.close() 
6. Webアプリの作成
ここでは、Flaskフレームワークを使用して画像をアップロードし、その画像を事前に学習された深層学習モデルを使って分類するWebアプリケーションを構築していきます。必要なフォルダ構成やファイルはローカル環境にて用意しています。最終的なフォルダ構成はコマンドプロンプト"tree /f"にて、下図のとおり簡易的に確認できます。
C:\Users\nakasuj\venv\final_web_app>tree /f
フォルダー パスの一覧: ボリューム Windows
ボリューム シリアル番号は 6007-D178 です
C:.
│ final_model.h5
│ final_output.py
│ README.md
│ requirements.txt
│
├─static
│ stylesheet.css
│
├─templates
│ index.html
│
└─uploads
.gitkeep以下に各部分の詳細な説明を記載します。
学習済モデル: final_model.h5
# モデルの保存
import os
from google.colab import files
result_dir = '/content/drive/My Drive/Aidemy_final_output/results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'final_model.h5'))前章までの検証で作成したモデルを.h5ファイルに保存し、webアプリ製作の準備を進めます。なお、過去の成果物のブログから、画像サイズ256x256のままでは無料版のRenderでは公開できない可能性が高いため、画像のサイズを100x100にして改めて学習を行いました。結果は下記であり、画像サイズを小さくすることで精度に若干の低下が見られたものの、前章までの検証で確認された汎化性能、ひび割れ特徴抽出は十分に担保できていると考えられます。ここで学習したモデルを用いてwebアプリの作成を行いました。
精度:0.7851 (最終版:0.8012)
偽陰性率:0.3325 (最終版:0.3688)
偽陰性割合:0.2525 (最終版:0.3067)


実行ファイル: final_output.py
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["ひび割れ無し","ひび割れ有り"]
image_size = 100
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./final_model.h5',compile=False)#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, color_mode='rgb', target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)講座の内容を参考にコードを作成しました。詳細は割愛しますが、下記に注意点を記載しておきます。
入力/出力時のtensorflow/kerasバージョン互換性
ローカル環境で"http://127.0.0.1:5000/"にてアプリの挙動を確認する際は、Google colaboratoryのtensorflow/kerasと同じバージョンをローカル環境に用意することで、出力/入力時のバージョン互換性の問題を解消でき、エラー無く検証が可能になるかと思います。著者はこのバージョンが揃っていなかったことでアプリの検証作業に少し手間取りました。
google colaboratoryのtensorflow/kerasのバージョン確認方法は下記です。
import tensorflow as tf
import keras
print(tf.__version__)
print(keras.__version__)ここで取得したtensorflow/kerasの特定のバージョン(著者の場合は、いずれも2.15.0)のライブラリを、コマンドプロンプト上で下記のとおり実行してローカル環境に用意しました。
pip install tensorflow==2.15.0
pip install keras==2.15.0再コンパイルの防止
学習済モデルの入力時、"compile=False"とすることで再コンパイルをしないようにしています。後々Renderでのデプロイ時にこの記述がないとエラーが起きる可能性があります。
スタイルシートファイル: stylesheet.css
header {
background-color: #5b5b5b;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #ffffff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
body{
background-image:url("https://lh3.googleusercontent.com/d/1o-eGv_ELRg6nvz7l8X0mwvA95NW8eCNp");
background-repeat: no-repeat;
background-position:50% 50%;
background-size:contain;
}
.main {
height: 500px;
}
h2 {
color: #000000;
margin: 120px 0px;
text-align: center;
}
p {
color: #000000;
margin: 100px 0px 50px 0px;
text-align: center;
}
.answer {
color: #ff0000;
margin: 100px 0px 50px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}講座の内容を参考にコードを作成しました。詳細は割愛しますが、ヘッダーやフッターの色、メイン部の背景に画像を入れる等のカスタマイズを行っています。
テンプレートファイル: index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Bridge_deck_Crack_detection</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">Crack detection</a>
</header>
<div class="main">
<h2> AIが送信された画像のひび割れの有無を判別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>講座の内容を参考にコードを作成しました。詳細は割愛します。
ライブラリファイル: requirements.txt
absl-py==0.9.0
astor==0.8.1
bleach==3.1.5
bottle==0.12.18
click==7.1.2
certifi==2020.6.20
chardet==3.0.4
flask==2.0.1
future==0.18.2
gast==0.3.3
grpcio==1.31.0
gunicorn==20.0.4
h5py==2.10.0
html5lib==1.1
itsdangerous==2.0
idna==2.10
Jinja2==3.0.1
line-bot-sdk==1.16.0
Markdown==3.2.2
MarkupSafe==2.0
numpy==1.18.0
oauthlib==3.1.0
pillow==7.2.0
protobuf==3.12.4
PyYAML==5.4.1
python-dotenv==0.14.0
requests==2.25.1
scipy==1.4.1
six==1.15.0
tensorboard==2.3.0
tensorflow-cpu==2.3.0
termcolor==1.1.0
urllib3==1.26.5
Werkzeug==2.0.0講座の内容を参考にコードを作成しました。詳細は割愛します。
.gitkeepファイル
.gitkeepファイルは内容としては空っぽであり、何か意味があるファイルではありません。しかし、後々の処理でファイルを追加するためにデフォルトで空のフォルダを用意したいという場合(今回では、"Uploads"フォルダ)に、空フォルダだけだとGitHubでコミットされなくなってしまうため、ダミーファイルとして保存されているものとなります。
GitHubリポジトリの作成~Renderでのデプロイ
こちらも本筋でないため詳細は割愛しますが、下記が注意点です。
環境設定
Renderのダッシュボード->"Environment"から下記のとおり環境設定をすることで、デプロイ時にエラー無くwebアプリの公開が可能となりました。
Key: PYTHON_VERSION
Value: 3.8.2

アプリの検証
作成されたwebアプリの画面は下記のとおりです(無料版のRenderでデプロイすると少し開くのに時間がかかる?)。

https://aidemy-final-output-jn.onrender.com/
試しに明らかにひび割れの画像を入力してみると…


確かに「ひび割れ有り」と判断してくれました。
7. 感想
今回はひび割れを自動検知する学習モデルの作成をメインで行いました。精度自体が云々というよりも、様々なパラメータを変えながら比較検証をすることで、そのパラメータにどんな意味があるのか?またこのパラメータと別のパラメータはトレードオフの関係になっている?など、様々な知見を得られたことが大きな成果だったのではないかと思いました。
また、実際に予測値を外したケースの画像なども実際に確認してみると、これは本当にひび割れ有りなのか?などデータ自体にも少なからず疑問を感じました。こうした画像認識系のAIにおいて、「学習データの準備」に一番時間がかかる、という話を聞いたことがありましたが、どれだけ人の手でちゃんとした分類を事前にしておくか(例えば、どこまでのひび割れを検出したいか?等)がとても重要なのだと改めて感じました。
最後に、技術カウンセリングやオンラインでの質問室などで真摯にご対応いただいたチューターの皆さま、誠にありがとうございました。
8. CNNモデルの構築~検証・修正編②~
(2024.7.17 追記)
成果物作成としてのブログとアプリの製作に関しては上記までの内容で一旦完了となりますが、チューター様との面談でまだモデルに改善の余地がありそうでしたので、下記追加検証編です。
ハイパーパラメータ等の調整
パターン⑥:batch_size: 256->512
# 作成したモデルで学習を実施
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=512, epochs=30)4章の検証ではバッチサイズを小さくしましたが、基本的にはバッチサイズは大きい方が良しとされているとのことでしたので、バッチサイズを512にして実行してみましたが、GPUメモリの不足によりエラーが発生してしまいました(Google Colab上 T4 GPU)。今回、画像サイズが256x256と比較的大きいもので学習しており、精緻な学習にはやはり高スペックなPCが必要になるのだと改めて感じました。また、バッチサイズ256では学習ができましたので、今回はバッチサイズを256に戻して学習を行うこととしました。
パターン⑦:転移学習のベースモデル:VGG16->ResNet50
VGGはILSVRC2014にて準優勝だったモデルであったのに対し、ResNet50は翌年のILSVRC2015にて優勝したモデルとなっています。VGGと層数や構造が異なるのは当然として、ResNet50の特徴としてShortcut Connectionを用いたResidual Blockやバッチ正規化が挙げられます。詳細は下記ご参照ください。
ResNet50に関してはモデル構造が複雑だったので、まず何層あるかを確認するために、下記コマンドを実行してモデル構造をExcelファイルで出力してみました。トップ層除いて175層のモデルとなっていることが分かりました。
import pandas as pd
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Input
# 入力テンソルの定義
input_tensor = Input(shape=(256, 256, 3))
# ResNet-50の基本モデルのロード(トップ層は含まない)
model = ResNet50(weights='imagenet', include_top=False, input_tensor=input_tensor)
# モデルの概要を取得
model_summary = []
i=1
for layer in model.layers:
layer_summary = {
'No': i,
'Layer Name': layer.name,
'Layer Type': layer.__class__.__name__,
'Output Shape': layer.output_shape,
'Number of Parameters': layer.count_params()
}
model_summary.append(layer_summary)
i=i+1
# DataFrameに変換
df_model_summary = pd.DataFrame(model_summary)
# Excelファイルに書き出し
file_path = "ResNet50_model_summary.xlsx"
df_model_summary.to_excel(file_path, index=False)
print(f"Model summary has been saved to {file_path}")ResNet50はConv1~Conv5_xまで、大きく5層に分類することができそうです。VGG16の検証を基に、ResNet50の全てのパラメータ更新を固定するのでなく、Conv4_xまで(143層目まで)のパラメータ更新を固定して、学習を実行することとしました。
# 必要なライブラリをインポート
from tensorflow.keras.applications import ResNet50
# input_tensor の定義
input_tensor = Input(shape=(img_size, img_size, 3))
resnet50 = ResNet50(weights='imagenet', include_top=False, input_tensor=input_tensor)
# resnet50 に追加するモデルを定義し、結合
top_model = Sequential()
top_model.add(Flatten(input_shape=resnet50.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの結合
model = Model(inputs=resnet50.input, outputs=top_model(resnet50.output))
# resnet50部分の重み更新は固定(143層目まで)
for layer in model.layers[:143]:
layer.trainable = False結果は下記です。VGG16の重み更新の層数を減らしたのと同様、精度に改善が見られました。また過学習が起きていることは変わりませんが、訓練データの方の精度が格段に上がっていることが分かりました。ResNet50の転移学習を行うことに効果があると判断しました。
※今回の比較対象は、VGG16にて15層目まで固定したパターン③です。
精度:0.7741 (パターン③:0.7926)
偽陰性率:0.2857 (パターン③:0.2363)
偽陰性割合:0.2381 (パターン③:0.2069)


以上の内容を基に、最終的に下記パラメータを設定しました。
パターン④:追加全結合層数増加 1->2
パターン⑤:学習率 固定値(1e-4)->変動値
パターン⑦:転移学習のベースモデル:VGG16->ResNet50
結果は下記です。過学習は防げているように思いますが、正直、あまり結果の改善には繋がりませんでした。
精度:0.7469 (最終版:0.8012)
偽陰性率:0.3117 (最終版:0.3688)
偽陰性割合:0.2609 (最終版:0.3067)


ResNet50がVGG16に比べて深いモデルであることなどが影響しているのかもしれませんし、学習データのラベル付け自体をもう少し工夫する(小さなひび割れは無視してしまう等)必要もあるかもしれません。いろいろ考えだすとキリが無くなりそうなので、一旦検証はここまでとしたいと思います。
この記事が気に入ったらサポートをしてみませんか?