
Coursera machine learning week2 まとめ

第二週目のまとめです。この週はOctaveの扱い方と多変量線形回帰と正規方程式にについてまとめられています。今回はOctaveは除くので多変量線形回帰と正規方程式です。ではやっていきます。
・Multiple features(variables)
簡単に言えば前回の仮説関数から変数を増やしたものです。前回の住宅価格の予測では土地の大きさを一つの変数として表現しました。今回はそれに加えて寝室の数や築年数、何階建かという説明変数を加えます。ではこれらを踏まえた上でモデルを作成していきます。流れも後は単変量と同じです。
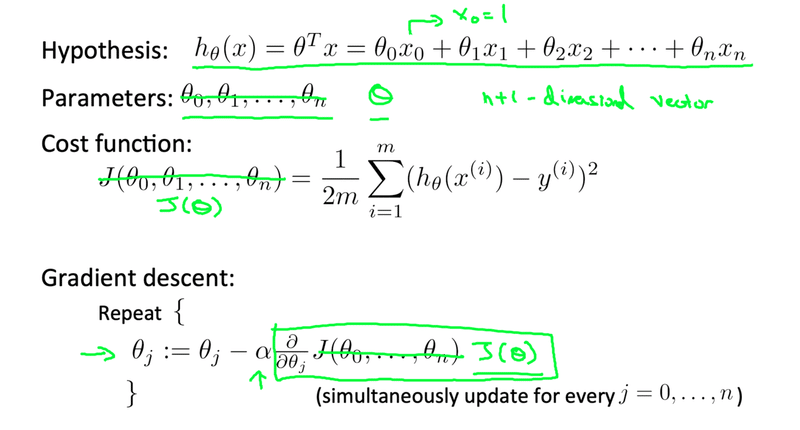
このまま勾配降下法を使ってもいいですが、ある細工をします。それがFeature Scalingです。これが何かと理解する前に例をあげます。先程の住宅価格の予想であれば寝室の数と土地の大きさを例にします。何か気付きますか?そうです、単位の大きさが違います。寝室の数はせいぜい大きくても5部屋とかだと思いますが、土地の大きさは何千feet^2にもなると思います。それをそのままモデルに当てはめてしまうと土地の大きさの影響力が他の変数と比べるとかなり大きくなってしまいます。
そこで登場するのがFeature Scalingです。feature scalingには種類があってそれが正規化(normalization)と標準化(standardization)です。
・正規化とは特徴量の値をある範囲におさめることです。よく使われるのが(0,1)(-1,1)です。
・標準化とは特徴量の平均を0に標準偏差を1にすることです。
ここまでできたらいよいよ機械学習をやっていきます。同じく勾配降下法を使います。再度確認します。
・Debugging: How to make sure gradient descent work correctly
前回学習率というものを学びました。学習率が小さすぎると学習は遅くなってしまい、逆に大きすぎると一向に収束しませんでした。
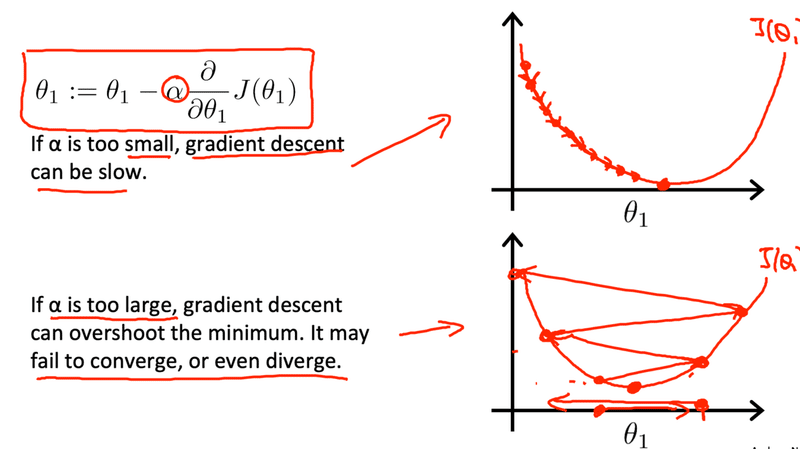
では学習がうまくいくとJ(θ)、コスト関数はどうなるでしょう。下の図は実際にどのように学習が進んでいるかを表しています。下の図をみてみると100回から200回ほどで学習はある程度進みコスト関数もかなり小さくなってきました。しかし300回から400回くらいになってくるとあまり変化してないですね。ここから何が分かるかというとαが適切な値で設定されていくことが分かります。

では適切な学習率はどのように求めればいいのでしょうか。次に表示する値がおすすめです。
0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1
・Linear Regression with multiple variables(多変量線形回帰)
仮説関数に使う変数は自分で組み合わせても大丈夫です。例えば与えられた変数の中に敷地の縦と横の変数があるとしたら、合わせて敷地の面積という風にしても大丈夫。
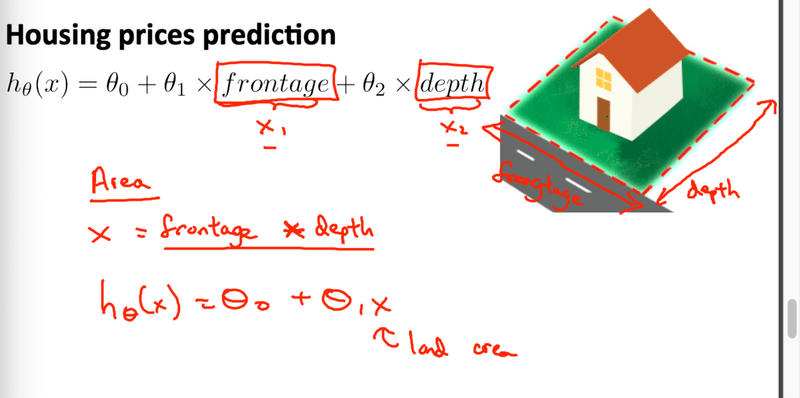
安易に組み合わせるのではなく変数同士を確認して組み合わせること。
・Normal equation(正規方程式)
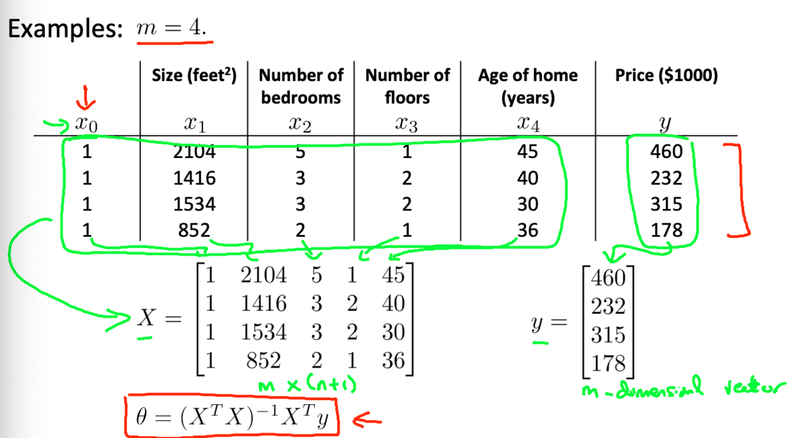
勾配降下法では反復を繰り返しながらθの値を求めていったが、正規方程式では解析的にθを求めることができる。住宅価格のデータを行列に当てはめてθの値を求めることもできる。
・Difference between gradient descent and normal equations(勾配降下法と正規方程式の違い)

勾配降下法
・αを求める必要がある
・多くの反復が必要
・特徴量が多いとうまく機能する
正規方程式
・αの設定が必要ではない
・反復が必要ではない
・転置ベクトルを求める必要がある
・特徴量が多いと学習が遅くなる
正規方程式から勾配降下法へと切り替える目安の特徴量の目安は10の6乗
・最後に
正直な話、メモ程度に考えているのでさらに深く知りたい方は次に紹介する記事を参考にしてください。
Googleでcoursera machine learning week◯など検索して貰えばさらに分かりやすくまとめられているので参考にしてみてください。(でもそれらに負けないように頑張ります笑)
この記事が気に入ったらサポートをしてみませんか?