
Coursera machine learning week3 まとめ(part1)

この週は教師あり学習問題の分類問題に焦点を当てています。この週の最後には正則化や過剰学習も紹介されています。
この週のロジスティック回帰の問題が難しかったのでpart1でじっくりロジスティック回帰についてまとめます。part2では残りの正則化や過剰学習についてまとめます。
・Classification
分類問題の例として以下のような例が挙げられています。
・Email : Spam / Not Spam?
・Online Transaction / Fraudulent (Yes / No)?
・Tumor : Malignant / Benign ?
y∈{0, 1}で表すことができ、0は大抵negative class(ものがない)を示していて、1はPositive class(ものがある)を示しています。例として0がBenign、1がMalignantみたいな感じです。malignantは悪性という意味なので腫瘍があると解釈できます。benignは良性という意味なので腫瘍がないということになります。
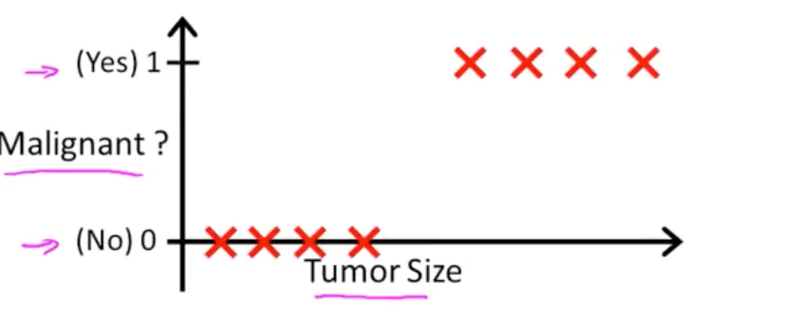
腫瘍の大きさから、悪性か良性かを分類する例↑
仮にこの図にy=xの直線を引くと悪性か良性を判断する閾値は0.5となる。
もし0.5以上になる腫瘍の大きさを超えたらy=1と判断する(つまり悪性)もし0.5よりも小さかったらy=0と判断する(つまり良性)
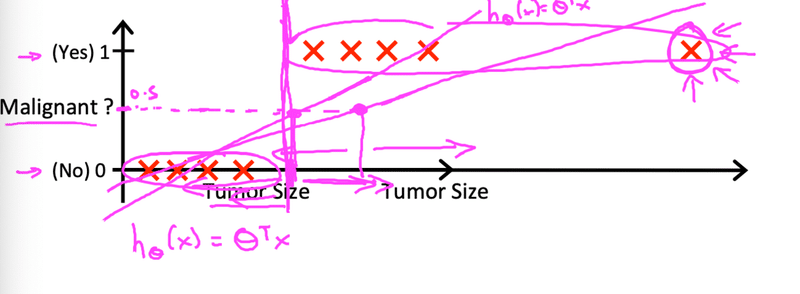
しかし外れ値があるとうまく機能しなくなる。以下の図の右端の腫瘍は他の腫瘍の大きさと比べるとかなり大きいが、y=1で直線を引くと良性という判断になってしまう。それはおかしいので分類問題では線形を用いることは好ましくない。
・Hypothesis Representation(ロジスティック回帰のコスト関数)
ロジスティック回帰では出力値が0か1を求めたい。ここで使用するのがシグモイド関数と呼ばれるものである。(別の名をロジスティック回帰と呼ぶ)シグモイド関数は以下のようになる。

式は次のように表すことができる。
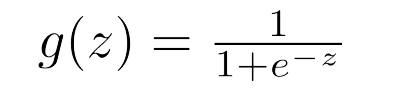
この式を元に仮説関数を作成していくと次のようになる。
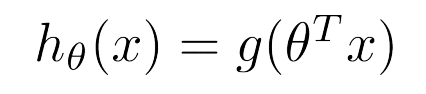
この出力が0.7の場合は70%の確率で悪性(1)、30%の確率で良性(0)となる。
・Decision boundary(決定境界)
先ほども紹介したがシグモイド関数で定義されるh(x)が0.5以上の場合は1、0.5以下の場合は0と判断できます。またこの定義からg (z)の場合も求めることができます。
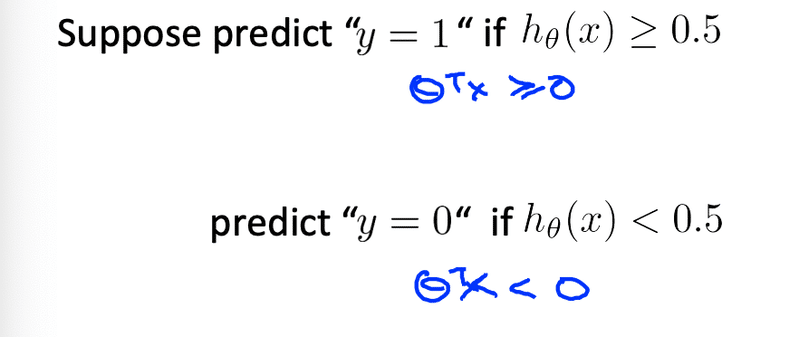
例えば次のように0か1かを分ける線を決定境界と言います。
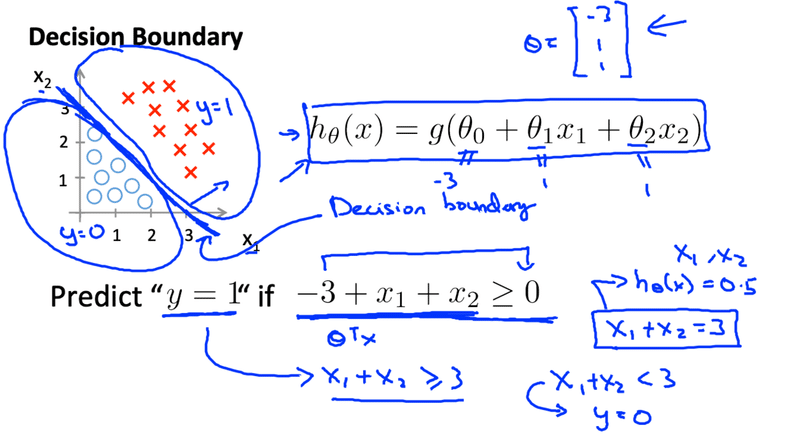
また非線形の場合でも求めることができます。

・Cost Functions(コスト関数)
ではθを求めるために線形回帰と同じようにコスト関数を最小化します。線形回帰の場合はこのようなコスト関数になった。
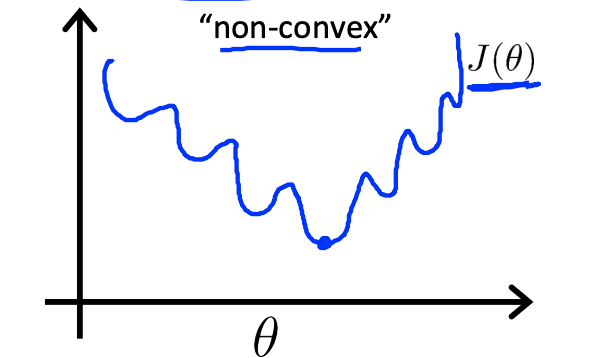
しかしロジスティック回帰では先程のg(z)を代入すると下のようなnon-covvexな関数になってしまう。そうすると局所解に陥る可能性が高くなる。(見せかけの最小値)
なのでロジスティック回帰の場合は以下の関数をコスト関数として扱う。
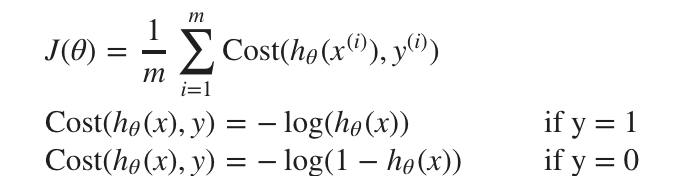
y=1の時のグラフは次のようになる
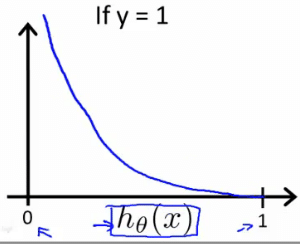
y=0の時のグラフは次のようになる
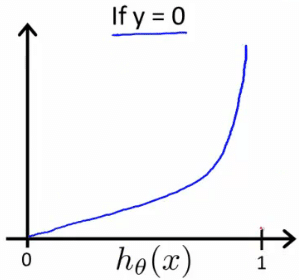
またこの関数を単純化して一行で表現することもできる。(プログラムに適用するときに便利)
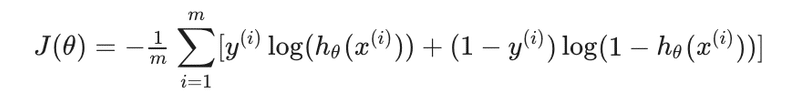
試しに0や1を代入しても上で紹介したような式になる。次にベクトル化した際は次のようになる。
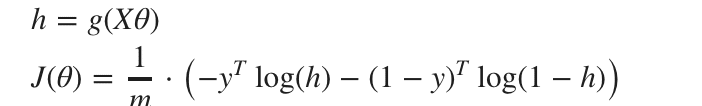
こちらも同じように勾配降下法に入れてみると次のようになる。ロジスティック回帰の際もθは同時に更新する。
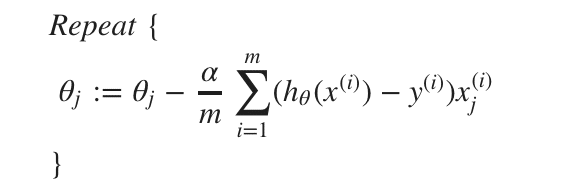
・Advanced optimization
勾配降下法によってコスト関数をを最小化していきました。しかし勾配降下法では以前紹介したように局所解に陥りやすかったり、学習率αを設定する必要がありました。
ここで登場するのが"Conjugate gradient(共役勾配法)", "BFGS", and "L-BFGS"と言ったアルゴリズムである。
これらのアルゴリズムを使用することで学習率αを手動で選ぶ必要がなく、尚且つ勾配方よりも速い場合が多い。一見便利なアルゴリズムだが、これらのアルゴリズム自体複雑で実際に何が起きているのかを把握することが難しい。
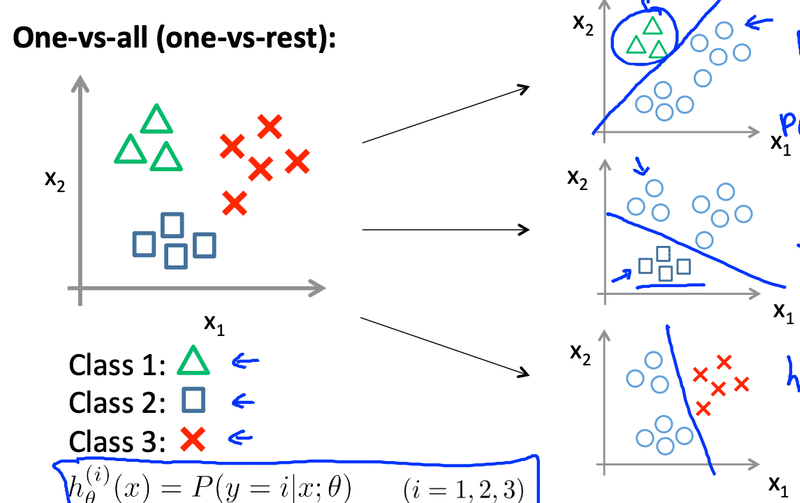
・Multi-class classification One-vs-all
三つ以上の分類をする場合も沢山あると思います。例えばこのメールが誰からきたのかなど沢山例がある。
そのような場合三つの境界線を引くことになる。一つの図に三つ引くのではなく、場合分けとして考える。例えば三角のclass1を分類したい場合はそれ以外を同じものとして二値分類に持ち込む。そしてそれ以外のclassも同じように実行する。このプロセスで分類することができます。
新たに予測する際は以下のh(θ)を最大化するクラスiを選択する。
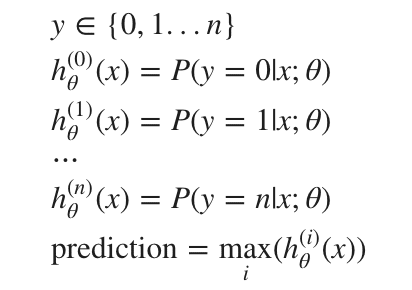
この記事が気に入ったらサポートをしてみませんか?