
Coursera machine learning week3まとめ(part2)

前回ロジスティック回帰についてまとめました。今回はそれの続きです。今回の内容は過剰適合と正則化についてまとめます。
・The problem of overfitting
過剰適合とは何でしょうか。簡単に言えば訓練データに対してとても精度が良すぎるせいで、テストデータなどの未知のデータに対しての性能が悪くなってしまうことです。
原因として外れ値も含んでいるから。
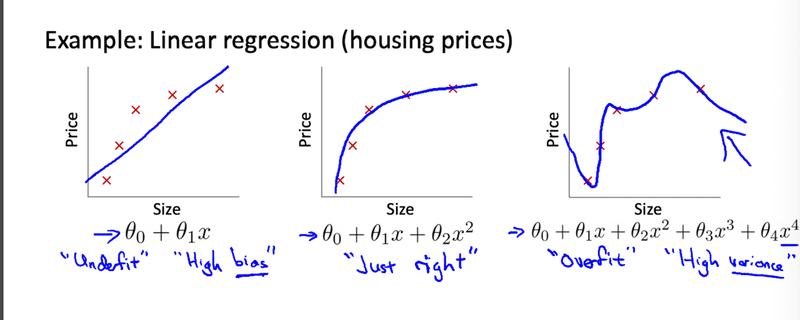
講座では住宅価格の例が挙げられています。一番左は訓練データに対しても精度が悪そうです。このようにテストデータだけではなく訓練データにも精度が悪くなってしまうことを適合不足(Underfitting)と言います。一番右側が過剰適合が生じている例です。とても複雑な関数になってしまい、予測が難しくなります。恐らくロジスティック回帰の方でみるとより顕著になっていますね。決定境界がかなり複雑になっています。
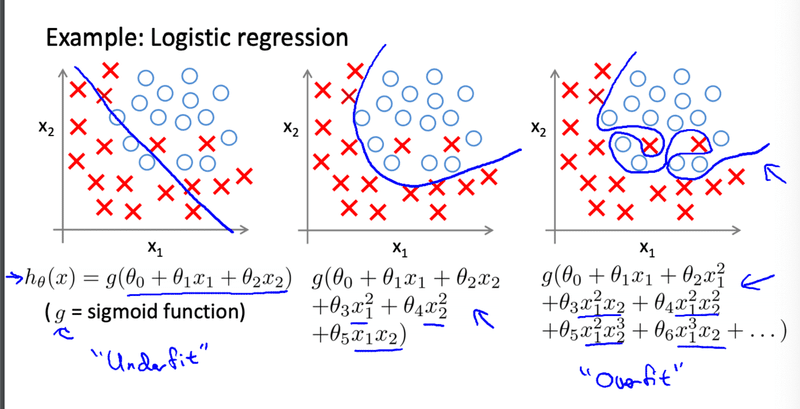
この過剰適合を防ぐための方法として次のような方法が紹介されています。

一つ目が特徴量の削除。例えば主成分分析(PCA)などがありますが後の講座で扱うそうです。二つ目が正則化という方法です。
・Regularization
正則化と簡単に言えばパラメータを小さくすることです。λという記号を使用します。
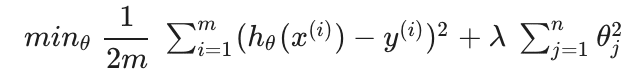
これを行うことで複雑だった関数がよりシンプルになり過剰適合が起きにくくなります。
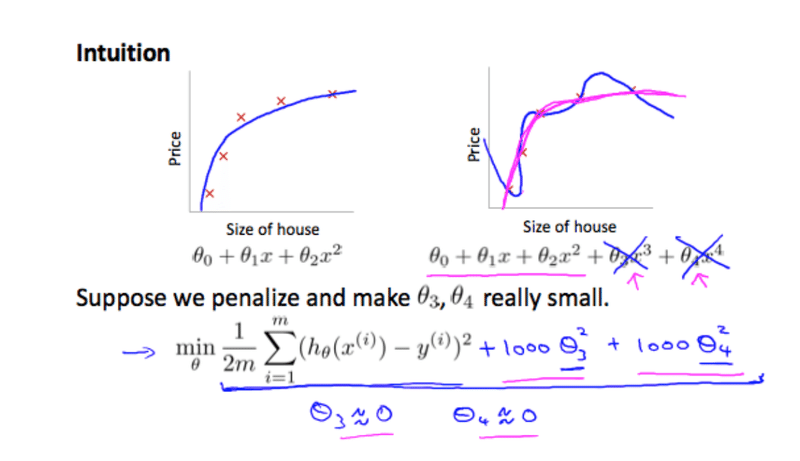
しかしλの数が極端に大き過ぎると失敗してしまいます。過剰適合が失敗して、適合不足になったりします。
・Regularized linear regression
線形回帰には次のように当てはめます。後ろに正則化をつけます。
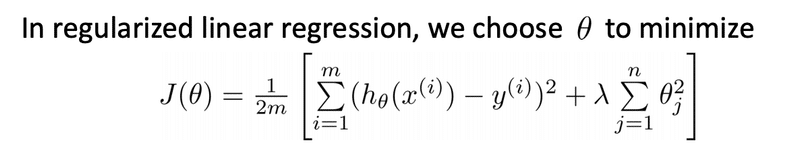
勾配降下法を実行すると次のようになります。
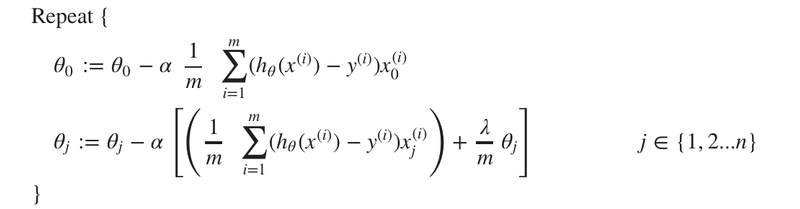
正規方程式ではどうでしょう。対角成分が左端以外1になっている行列を入れます。
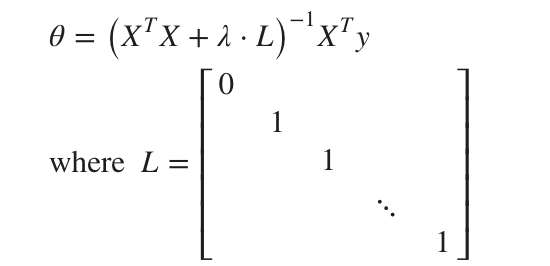
以上です。正則化に関してはまた別の記事であげようかなと考えています。正則化にラッソ回帰やリッジ回帰があります。以前簡単にまとめたので載せておきます。
この記事が気に入ったらサポートをしてみませんか?