
title、image、descriptionだけ表示させる

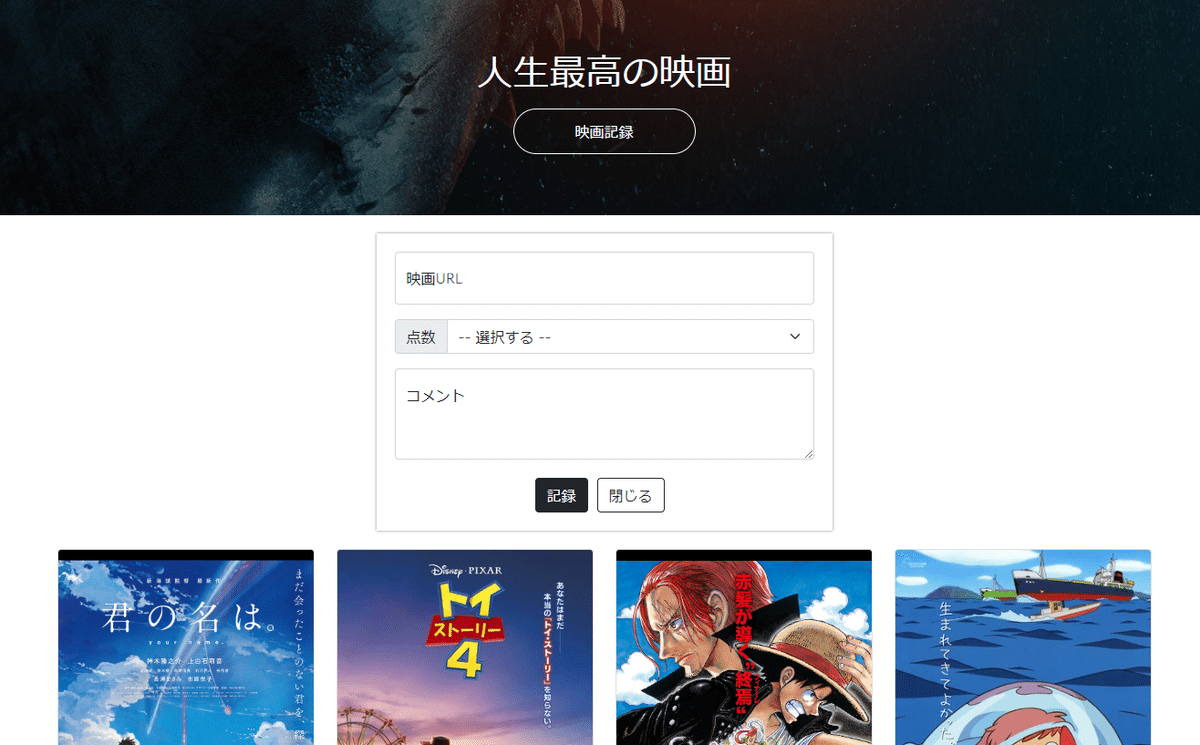
今日は、以前講義中に作成した映画のレビューサイトをアップグレードしていくらしい。内容は、このサイトの「映画記録」ってボタンをおすと、こんな入力フォームがでてくるんだけど、ここに映画のURLと評価、コメントを入れて「記録」ボタンを押すと、あらたにその映画の画像・評価・コメントが追加されるという機能をやってみる。
クローリング、あ、やったような気がする…。
今回はクローリングするサイトの個別の映画のURLを入れたら、タイトルや画像、コメントなどが表示するようにするんだけど、それってどうやるの?というお話。
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://eiga.com/movie/98389/', headers = headers)
soup = BeautifulSoup(data.text, 'html.parser')
ogtitle = soup.select_one('meta[property="og:title"]')['content'].split(' : ')[0]
ogimage = soup.select_one('meta[property="og:image"]')['content']
ogdesc = soup.select_one('meta[property="og:description"]')['content']
print(ogtitle,ogimage,ogdesc)パイチャームで、こういうコードになった。タイトル、画像、ディスクリプションをひっぱってくるには、メタタグをもってくる。今回の講義の中で、なるほどと思ったのが、データを分けるために使われるsplitという関数。もともと、contentタグの中には「content="マイ・エレメント : 作品情報 - 映画.com"」という情報が入っていたけど、:以降の「作品情報~」は不要だから、表示させたくないよね、と。もし表示させちゃうと、↓の画像のタイトルが、ぜんぶ「ハウルの動く城 : 作品情報 - 映画.com」みたいになっちゃうから。そういうときに便利なのが、split関数のようでsplit(’ : ')で、:からデータを分けるってことらしいです。はい。それで[ ]内のデータのうち:で分けて、[0]で、ゼロ番目のデータを表示させる、という指示になってました。そうそう、0番目は一番左。
だから、content="「マイ・エレメント 」「: 作品情報 - 映画.com」
とわけて、マイ・エレメントだけを表示させたんだな。

とりあえず、、、脳みそ爆発オバサンとしては、この回では
これくらいしか理解できていない。こ、こんなんで、だいじょぶか?
この記事が気に入ったらサポートをしてみませんか?