
魚識別アプリ作成

1.はじめに
AIアプリを作れると、今後楽しいことが待っているとふと考え、オンラインスクールを探し、その中でPython、AI関係を学ぶなら、Aidmyだとすぐカウンセリングを申し込み、カウンセリング後、次の日には受講手続きを行いました。その後、1週間程で、鼻息荒く受講開始します。とりあえず50%くらいの理解で先を急ぎ、途中コロナ休暇も挟み(10日間まともに勉強できなかったのは痛かった)なんとか、受講開始60日ほどで成果物作成までこぎつけました。ここでは、成果物作成の過程をまとめていきたいと思います。
2.構築環境
Google Colaboratory
3.作成したプログラム
1.画像収集
Googleから icrawlerを利用し、スクレイピングして画像を収集しましたが、
1匹だけで写っている学習できそうな画像がほぼないため断念。
!pip install icrawler
#pythonライブラリの「icrawler」でBing用モジュールをインポート
from icrawler.builtin import BingImageCrawler# 画像のダウンロード
bing_crawler = BingImageCrawler(downloader_threads=4,
storage={'root_dir': 'img_Fish'})
bing_crawler.crawl(keyword='鯵', filters=None, offset=0, max_num=100)
今回は、精度を高めることを意識してkaggleのデータセットを利用しました。

今回識別する海の生き物の画像は、
1.鯵
2.鯛
3.スズキ
4.えび
5.ます
の5種類の識別を行い、それぞれのデータ数は1000枚の画像を使用し処理をしていきます。
@工夫したところ
ダウンロードした画像は3GBと容量が大きいので、アップロード時間を短縮するために、ZipファイルをGoogleDriveに保存して、cd コマンドで解凍したファイルを保存するディレクトリに移動してから下記コードを実行しました。
!unzip /content/drive/MyDrive/FIshImage_kaggle2.必要なライブラリのインポート
Aidemyで学んできたカリキュラムを参考に必要なライブラリをインポートします。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
import pickle
from google.colab import drive3.画像の読み込み
画像の読み込みを行なっていきます。
# お使いの仮想環境のディレクトリ構造等によってファイルパスは異なります。画像読み込み
path_horse_mackerel = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel")
path_red_sea_bream = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Red Sea Bream/Red Sea Bream")
path_sea_bass = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Sea Bass/Sea Bass")
path_shrimp = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Shrimp/Shrimp")
path_trout= os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Trout/Trout")
img_horse_mackerel = []
img_red_sea_bream = []
img_sea_bass = []
img_shrimp = []
img_trout = []
for i in range(len(path_horse_mackerel)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel/" +path_horse_mackerel[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (100,100))
img_horse_mackerel.append(img)
for i in range(len(path_red_sea_bream)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Red Sea Bream/Red Sea Bream/"+ path_red_sea_bream[i])
#print(path_red_sea_bream[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (100,100))
img_red_sea_bream .append(img)
for i in range(len(path_sea_bass)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Sea Bass/Sea Bass/"+ path_sea_bass[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (100,100))
img_sea_bass.append(img)
for i in range(len(path_shrimp)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Shrimp/Shrimp/" +path_shrimp[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (100,100))
img_shrimp.append(img)
for i in range(len(path_trout)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Trout/Trout/" +path_trout[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (100,100))
img_trout.append(img)
with open("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/img_lists.pkl", "wb") as f:
pickle.dump((img_horse_mackerel,img_red_sea_bream ,img_sea_bass ,img_shrimp,img_trout), f)・各コード解説
path_horse_mackerel = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel")osモジュールの、ファイルやディレクトリの一覧を取得できるlistdir関数を使用し、それぞれのデータファイル名を取得します。
img_horse_mackerel = []for文でそれぞれの種類のデータを読み込み、データクリーニングして、 append()メソッドで保存するリストを作成します。
for i in range(len(path_horse_mackerel)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel/" +path_horse_mackerel[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (100,100))
img_horse_mackerel.append(img)OpenCVライブラリのメソッドを使用し、読み込み、データクレンジングを行い、for文を回しそれぞれのデータを上記で作成している、リストに保存します。
@工夫したところ
with open("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/img_lists.pkl", "wb") as f:
pickle.dump((img_horse_mackerel,img_red_sea_bream ,img_sea_bass ,img_shrimp,img_trout), f)pickleモジュールを使用して、for文とOpenCVライブラリで読み込み、リストに保存したデータを、1つのフォルダにまとめて書き込み、
with open("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/img_lists.pkl", "rb") as f:
img_horse_mackerel,img_red_sea_bream ,img_sea_bass ,img_shrimp,img_trout = pickle.load(f)上記コードで、データを読み込むようにして、読み込みにかかる時間を大幅に削減しました。
参考文献:
4.モデルの定義と学習
機械学習モデルを定義して学習させていきます。
#学習データと学習データに対応するラベル作成
X = np.array(img_horse_mackerel + img_red_sea_bream + img_sea_bass + img_shrimp + img_trout)
y = np.array([0]*len(img_horse_mackerel) + [1]*len(img_red_sea_bream) + [2]*len(img_sea_bass)+ [3]*len(img_shrimp) + [4]*len(img_trout))
#画像をシャッフル
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割 スライスを使用
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#ワンホットベクトル
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# vgg16のインスタンスの生成
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(5, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
#---------------------------
for layer in model.layers[:19]:
layer.trainable = False
#---------------------------
#krass Adam
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=128, epochs=40, validation_data=(X_test, y_test))
・各コード解説
#学習データと学習データに対応するラベル作成
X = np.array(img_horse_mackerel + img_red_sea_bream + img_sea_bass + img_shrimp + img_trout)
y = np.array([0]*len(img_horse_mackerel) + [1]*len(img_red_sea_bream) + [2]*len(img_sea_bass)+ [3]*len(img_shrimp) + [4]*len(img_trout))読み込んだデータが何の画像かを識別するため、学習データと学習データに対応するラベル作成します。
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]・ 学習効力をあげるためrandom.permutationメソッドを使用します。
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]今回は、学習データを8割、テストデータを2割に分割して学習させました。
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)カテゴリデータに対する前処理の一つ、one-hotベクトル化を行います。
参考文献
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(5, activation='softmax'))モデルは、画像処理で評判の高い、vgg16を使用します。また過学習を防止するため正規化 Dropoutも使用しました。
for layer in model.layers[:19]:
layer.trainable = False
#---------------------------
#krass Adam
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['accuracy'])vgg16の重みは、19に設定し、optimizerは、krassのAdamを使用する。
history = model.fit(X_train, y_train, batch_size=128, epochs=40, validation_data=(X_test, y_test))バッチサイズは、バッチサイズは機械学習分野の慣習として、「2のn乗」(32, 64, 128, 256, 512, 1024, 2048)が使われることが多いということで、最初は32で指定しました。しかし、テストした結果、過学習が 起きていたので128まで上げました。
5.テスト結果データを可視化する。
plt.figure()
epoch = range(len(history.history["loss"]))
plt.plot(epoch, history.history["loss"],label="loss")
plt.plot(epoch, history.history["val_loss"],label ="val_loss" )
plt.plot(epoch, history.history["accuracy"], label = "accuracy")
plt.plot(epoch, history.history["val_accuracy"], label = "val_accuracy")
plt.legend()
plt.show()matplotlibライブラリを使用し、テストデータの結果を可視化します。
6.画像データを識別する関数を作成する。
def pred_fishSearch(img):
img = cv2.resize(img, (100, 100))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return "鯵"
elif pred == 1:
return "鯛"
elif pred == 2:
return "スズキ"
elif pred == 3:
return "えび"
else:
return "ます"画像を受け取り、どの種類の海の生き物かを判定して返す関数を作成しました。
7.精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])テストデータを引数に指定して、model.evaluate()メソッドで学習済みのモデルの評価を行います。
for i in range(len(path_horse_mackerel2)):
img = cv2.imread("/content/drive/MyDrive/real_test_fish_img/test_horse_mackerel/" + path_horse_mackerel2[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_fishSearch(img))任意の画像を読み込み、『6.画像データを識別する関数を作成する。』のところの、pred_fishSearch関数で、読み込み画像の識別を行います。
8.モデルの学習結果
最初の結果はなんと、

正解率が18 %
5種類をランダムに選んだ時の確率、20 %を下回る結果になりました。
上記のコードは、最終的に仕上げたコードですが、最初のコードは以下の通りです。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# お使いの仮想環境のディレクトリ構造等によってファイルパスは異なります。画像読み込み
path_horse_mackerel = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel")
path_red_sea_bream = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Red Sea Bream/Red Sea Bream")
path_sea_bass = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Sea Bass/Sea Bass")
path_shrimp = os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Shrimp/Shrimp")
path_trout= os.listdir("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Trout/Trout")
img_horse_mackerel = []
img_red_sea_bream = []
img_sea_bass = []
img_shrimp = []
img_trout = []
for i in range(len(path_horse_mackerel)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel/" +path_horse_mackerel[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_horse_mackerel.append(img)
for i in range(len(path_red_sea_bream)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Red Sea Bream/Red Sea Bream/"+ path_red_sea_bream[i])
#print(path_red_sea_bream[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_red_sea_bream .append(img)
for i in range(len(path_sea_bass)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Sea Bass/Sea Bass/"+ path_sea_bass[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_sea_bass.append(img)
for i in range(len(path_shrimp)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Shrimp/Shrimp/" +path_shrimp[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_shrimp.append(img)
for i in range(len(path_trout)):
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Trout/Trout/" +path_trout[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_trout.append(img)
#学習データと学習データに対応するラベル作成
X = np.array(img_horse_mackerel + img_red_sea_bream + img_sea_bass + img_shrimp + img_trout)
y = np.array([0]*len(img_horse_mackerel) + [1]*len(img_red_sea_bream) + [2]*len(img_sea_bass)+ [3]*len(img_shrimp) + [4]*len(path_trout))
#画像をシャッフル
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割 スライスを使用
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#ワンホットベクトル
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(5, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
#---------------------------
for layer in model.layers[:15]:
layer.trainable = False
#---------------------------
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=0.01, momentum=0.9),
metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=32, epochs=40, validation_data=(X_test, y_test))
# 画像を一枚受け取り、何の魚かを判定して返す関数
def pred_fishSearch(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return "鯵"
elif pred == 1:
return "鯛"
elif pred == 2:
return "スズキ"
elif pred == 3:
return "えび"
else:
return "ます"
# ここに解答を記述してください
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# pred_fishSearch 関数に鯵の写真を渡してを精度を確認
for i in range(5):
# pred_fishSearch
img = cv2.imread("/content/drive/MyDrive/FIshImage_kaggle/Fish_Dataset/Fish_Dataset/Hourse Mackerel/Hourse Mackerel/" + path_horse_mackerel[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_fishSearch(img))
Test accuracy: 0.1876247525215149
正解率 18%を叩き出し、改善点を見つけ、修正をしていった箇所を記述していきます。
vgg16の重みを変更
変更前
for layer in model.layers[:15]:
layer.trainable = False変更後
for layer in model.layers[:19]:
layer.trainable = Falsevgg16の重みを、15から19に変更しました。この変更が、1番正解率を上げる要因になりました。
optimizerの変更
変更前
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=0.01, momentum=0.9),
metrics=['accuracy'])変更後
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['accuracy'])最適化アルゴリズム(Optimizer)を、 optimizer=optimizers.SGD(learning_rate=0.01, momentum=0.9)から
optimizer=optimizers.Adam()に変更しました。
参考文献
・Dense(出力層)、レイヤー変更
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(5, activation='softmax'))レイヤーの層を、深くしてみました。
結果は下記の通りです。

top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
history = model.fit(X_train, y_train, batch_size=128, epochs=40, validation_data=(X_test, y_test))レイヤーの層を、1つにしました。
結果は下記の通りです。

今回は、VGG16をモデルに使用しているためか、レイヤーを変更しても、実行結果はあまり変わりませんでした。
・画像のresizeの値
機械学習の界隈では、accuracy(正解率)をツーナイン、スリーナインというところを目指すということをお聞きして、とりあえずツーナインを目指し、他に改善点はないか確認してみると、resizeの値が小さいのではないかということが判明し、識別する関数で受け取った画像をresizeする値を、以下のように変更しました。
変更前
def pred_fishSearch(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))変更後
def pred_fishSearch(img):
img = cv2.resize(img, (100, 100))
pred = np.argmax(model.predict(np.array([img])))データ量は、4倍に増えることになります。
そして、結果は、ツーナインを超え、スリーナインを達成することができました。

9.任意画像識別結果
テストデータで、上記のようなaccuracyを得ることができましたが、任意の画像を入れた時に、きちんと識別できるか確認するために、任意の画像を読み込ませて、検証してみました。
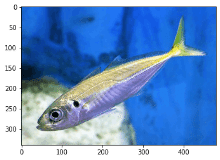
鯵検証

1/1 [==============================] - 0s 126ms/step
鯛

1/1 [==============================] - 0s 21ms/step
鯵

1/1 [==============================] - 0s 15ms/step
ます
1/1 [==============================] - 0s 16ms/step
ます

1/1 [==============================] - 0s 18ms/step
ます
鯛検証

1/1 [==============================] - 0s 18ms/step
鯛

1/1 [==============================] - 0s 17ms/step
鯛

1/1 [==============================] - 0s 19ms/step
鯛

1/1 [==============================] - 0s 21ms/step
鯛

1/1 [==============================] - 0s 22ms/step
鯛
スズキ検証

1/1 [==============================] - 0s 22ms/step
鯛

1/1 [==============================] - 0s 19ms/step
鯛

1/1 [==============================] - 0s 20ms/step
スズキ

1/1 [==============================] - 0s 19ms/step
ます

1/1 [==============================] - 0s 22ms/step
スズキ
えび検証

1/1 [==============================] - 0s 32ms/step
えび

1/1 [==============================] - 0s 23ms/step
えび

1/1 [==============================] - 0s 20ms/step
えび

1/1 [==============================] - 0s 28ms/step
えび

1/1 [==============================] - 0s 23ms/step
えび
ます検証

1/1 [==============================] - 0s 31ms/step
ます

1/1 [==============================] - 0s 26ms/step
ます

1/1 [==============================] - 0s 22ms/step
ます

1/1 [==============================] - 0s 22ms/step
ます

1/1 [==============================] - 0s 23ms/step
ます
以上の識別結果をまとめると、
鯵 正解率 1/5
鯛 正解率 5/5
スズキ 正解率 2/5
えび 正解率 5/5
ます 正解率 5/5
という結果になりました。
色や、形に特徴のある鯛やえび、ますはうまく識別できているようですが、特徴のあまりない鯵やスズキは、 正解率が半分もいかなく、あまり良くない結果となってしまいました。 今回、正解率の上がらなかった種類の、学習に使用したデータセットを確認してみると、少ない画像を、 データクレンジングをして水増しをした画像が多く、その辺が上手く識別できなかった原因だと推測られます。モデルを学習をさせて、高いaccuracyを出すことができても、学習させる画像の選択によって、特徴が似ていたり、特徴が少ないものは、上手く識別ができないことがあるという事も、今回の成果物作成で学ぶことができました。
4.今後の活用
今後は、釣り人や主婦が画像をアップロードして、何の魚かすぐ識別できるように、識別可能な魚の種類を増やしていこうと思います。また、学習に使用する画像データの選択、データクレンジングのスキルを高め、任意画像の識別精度も上げていきます。さらに、この魚識別アプリで得たスキルと知識を、他の画像識別にも転用して、さまざまなアプリを作成していきたいです。
5.おわりに
どの学習でも同じですが、機械学習の勉強は奥が深く、現在、底も皆目見当がつかない状況ですが、学習すればするほど、理解できることも少しずつ増え、楽しくなってきます。道のりは、まだまだ先が長いですが、コツコツ学習を続け、世の中のお役に立てる人物になれるよう邁進していく所存です。
最後に、カリキュラム学習から、成果物作成までこれたことは、Aidemyのスタッフの方々の親切で、手厚いサポータのおかげであった事は紛れもない
事実で、この場をお借りして、御礼申し上げます。
アプリのHerokuリンク
この記事が気に入ったらサポートをしてみませんか?