サクッとiPhoneでローカルLLMを試す。LLMFarm

MLXやらOpenELMやらのApple製LLMの波に乗るべくiPhone 15 Proを購入したので早速オンデバイスLLMを試してみます。「LLMFarm」というオープンソースなプロジェクトがあるのでこちらを使わせていただきました。
https://github.com/guinmoon/LLMFarm
「LLMFarm」:軽量なモデルをiOS/M系Silicon で実行できるライブラリ。機械学習ライブラリ『ggml』と『llama.cpp』をベースにしている。TestFlight経由でデモアプリも配布されており、誰でも簡単にオンデバイスLLMを試せる。
必要なもの: iPhone
1. TestFlightをインストール
『TestFlight』・・・ベータ版アプリケーション配布用アプリ。
iOSアプリケーションは通常、AppStoreの審査を通過しなければリリースはできないが、TestFlightではベータ版を開発者向けにクローズドに提供できる。
※今回のLLMFarmはguimoon氏が配布しています。感謝。
2. LLMFarmをインストール
TestFlight経由でLLMFarmがインストールできます。
3. モデルをダウンロード
今回はLLMFarm経由でMistral-7B-v0.1のQ3_K_S(3ビットに量子化したモデル)をインストールしてみます。
(※iPhone 15 ProはRAMが8GBあるので動きますが、それ以下のiPhoneの場合は動かない場合があります。その際はPhi-3-miniを試してみてください。)

画面右上の詳細ボタンをタップ
settingをタップ
Download modelsをタップ
Mistral-7B-v0.1を選択する
Q3_K_Sを選択する
ダウンロードする
Tips:
LLMFarm経由でのダウンロードは低速なので、Macがある場合はHugging Faceから直接ダウンロードして、ケーブルで転送する方が速いです。
4. チャットの設定
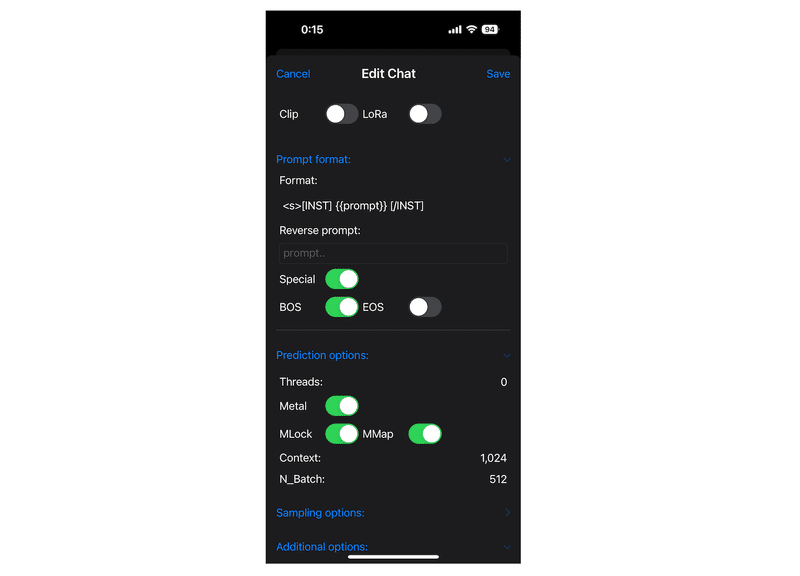
4-1. Mistral用Prompt templateの設定
モデルごとに会話の開始終了のトークンは異なるのでそれぞれ設定する必要があります。今回はMistral用の設定です。
Promptをタップ
以下を設定する
<s>[INST] {{prompt}} [/INST]
4-2. GPUとメモリの設定(任意)
高速化のための設定が推奨されています。
Prediction optionsをタップ
Metalを有効にする
(Metal: Apple Silicon用低レベルAPI。推論にGPUが使えるようになる)MLockを有効にする
(モデルをメモリ内にロックでき、メモリマップ時にモデルがストレージに勝手にスワップアウトされないようになります。)
5.チャットしてみる
これでオンデバイスでLLMを動かすことができます。
機内モードにして実行してみましょう。
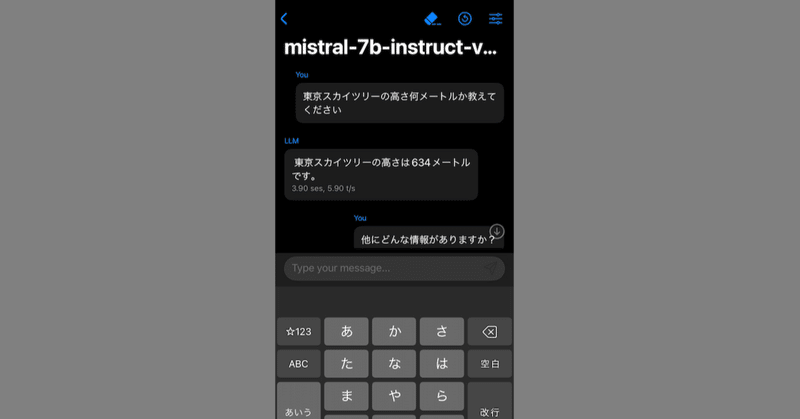
↓チャットの様子。精度は実用的とは程遠い。

番外編 Hugging Faceのモデルを使う
画面中央のdownloadからiPhoneにDLできる。
Gemma-7BやPhi-3など、Hugging Face上のモデルは直接GGUF形式でDLするとRAMサイズが足りるモデルであれば実行できます。
LLMFarmの[import from file…]からインポートできます。
この記事が気に入ったらサポートをしてみませんか?