
【ついに来た】DifyでWebサイトからナレッジ追加がリリース

ナレッジのデータソースにWebサイトが追加
ナレッジのデータソースにWebサイトが追加されました。
以前から表示はあったのですが、「coming soon」ってなっており気になっていた機能です。
これでRAGがはかどりそうですね!
クローリングにはFireCrawlというサービスを使います。
FireCrawlとは?
FireCrawlは、ウェブサイトをクローリングし、LLM(Large Language Model)で処理しやすいMarkdown形式に変換するAPIサービスです。
ウェブサイト全体の情報を効率的に収集できるため、Difyの知識ベース構築に最適です。
FireCrawlの設定
FireCrawlのための設定を行います。
「ナレッジ」画面を開き、「データソース」から「ウェブサイト」を選択します。

FireCrawlを使うにはAPIキーが必要なので、FireCrawlのアカウントを作成します。
右上の「Account」から、APIキーを取得します。

取得したAPIキーを設定画面に貼り付けて保存すれば、FireCrawlが使えるようになります。

ためしに、https://docs.firecrawl.dev/sdk/python から取得してみたところ、このようにチャンクが追加されていました!
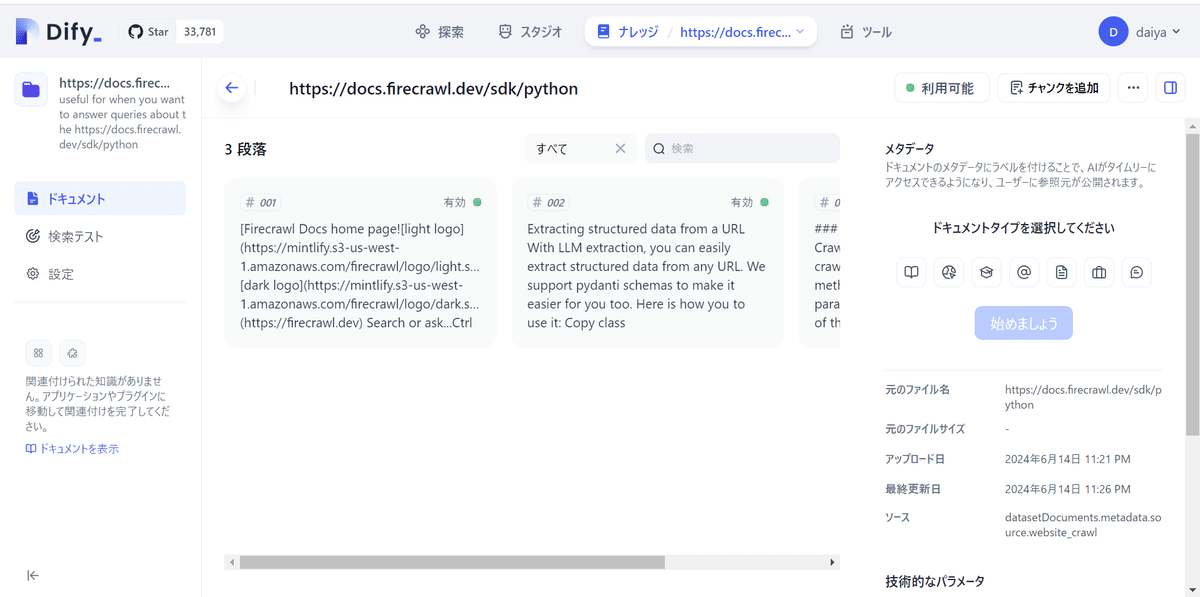
FireCrawlからAPIキーを取得するだけで簡単なのでぜひ試してみてください!
設定項目
設定できる項目として6つの項目があります。
Crawl sub-pages(配下のサブページもクロールするか)
Limit(デフォルト: 10)
Exclude paths
Include only paths
Max Depth
Extract only main content (ヘッダー、ナビバー、フッターなどを除外)

Include only pathsについて
FireCrawlでクロールするURLを指定するためのパターンを設定します。ここで指定したパターンにマッチするURLのみがクロールの対象となります。
例えば、ブログ記事のURLが "/blog/YYYY/MM/DD/article-name" のような形式である場合、"/blog/*" というパターンを指定することで、すべてのブログ記事がクロールされるようになります。
同様に、製品ページのURLが "/products/category/product-name" のような形式である場合、"/products/*" というパターンを指定することで、すべての製品ページがクロールされるようになります。
パターンは配列形式で複数指定することができます。
例: ["/blog/*", "/products/*"]
Exclude paths について
Include only paths の逆になります。除外したいURLを指定します
Max Depth について
クロールする深さの限度を設定します。深さはURLの階層で表現され、入力したURLを起点として相対的に指定します。
深さ0:入力したURLのページのみをクロールします。
深さ1:入力したURLのページと、そのページ内の1階層下のリンク先のページをクロールします。
深さ2:入力したURLのページと、そのページ内の1階層下と2階層下のリンク先のページをクロールします。
以降、深さを増やすごとに、次の階層のリンク先のページがクロールに含まれていきます。
例えば、入力したURLが "https://www.example.com" で、深さを1に設定した場合、
"https://www.example.com/products"
などの1階層下のページまでクロールされます。
深さを2に設定した場合は、さらにその下の階層、
"https://www.example.com/products/item2"
なども含めてクロールされます。
深さを大きくするほどクロールするページ数が増えるため、必要以上に大きな値は設定しないようにしましょう。
しかし
私の設定が悪いのかもしれませんが、サブページをうまく取得できないサイトが多かったです。
https://mendable.ai はサブページも取得できる
https://docs.firecrawl.dev/sdk/python はサブページ取得できなかった
これはこちらの設定の問題かもしれないので追って調査したいと思います。
どうやら robots.txt や sitemap.xml に大きく影響されるようです。
Firecrawlのクローリングは「robots.txt」や「sitemap.xml」が大きな影響を与える。サブページが読み取れない場合はsitemap.xmlが設定されてないケースが多い。これは、Difyで実装する時も一緒👀。 https://t.co/oUmUncfyAe pic.twitter.com/PgwcFwxPmV
— sangmin.eth | Dify Ambassador (@gijigae) June 16, 2024
X(Twitter)では更にリアルタイム性の高いDifyや他LLM、AIサービスの情報・活用法などを発信しています。フォローよろしくお願いします!
https://twitter.com/flowphantom
この記事が気に入ったらサポートをしてみませんか?