
美味しいトマトを収穫するには

夏だ。東京はもう朝から30度を超えると聞く。暑いのは嫌だが、身体を元気にしてくれる日本の美味しい夏野菜が恋しい。帰国の度に、スーパーの野菜や魚の鮮度には驚かされる。
農業は日本の一大産業だが、農業を支える従事者は年々減少傾向にあり、その優れたスキルやノウハウ、匠の技とも言える技術をいかに次世代の担い手へと伝承していくかが重要な課題になっている。同時に、若手の新規新規就農者の数は増加しており、若い世代ならではの新しいアイデアや最新技術を導入し農業をアップデートしようという動きも盛んになってきている。
AIはこんな分野でもイノベーションの中心的な役割を担っている。例えば、私の諸先輩方が起業したLaboro.AIは、エンジニアコラムにトマト画像物体検出データセットを公開している。どのトマトが成熟しているのかAIが分かれば、機械による成熟トマトのみの自動収穫、特定の成熟期のトマトのみへの農薬散布といったことが可能になるからだ。つい数日前は、野菜収穫ロボットを開発するAGRISTがシリーズBの調達を発表しており、これからの展開が益々楽しみだ。
今日は、身近なトマトを例に、機械学習モデルは具体的にどう実用化するのか、解説したい。モデル作成は簡単だが、正確で、早く、多数のユーザーが常時使えるモデルを提供するのは難しい。この一連の過程を合理化するために「MLOps(機械学習運用)」という一大産業も生まれており、この概念を理解することで、AI実用化に必要なステップのイメージが沸くと思う。
⓪ 手動でのモデル運用
トマトの成熟具合が分かるMLエンジンを開発するには、以下のようなアプローチが必要となる。

まず、畑にあるトマトの情報を収集する。様々な成熟度(成熟・半熟・緑熟)のトマトの写真を集める。通常サイズとミニトマトなど種類があれば、種類毎に収集する。これが探索的データ分析・データセットの編集だ。違う野菜が混在しないよう、要注意。
写真が揃ったら、それらにラベルを付ける。トマトの種類別に分類し、先ほどの3種類の成熟度に応じたラベルを付ける。写真の解像度の確認、標準解像度の設定、見づらい画像の破棄、及び画像のコントラストと明るさの調整をすることで、データの準備が整う。
次に、画像を分類するためのモデルを訓練する。TensorFlowのような機会学習プラットフォームで、1つの入力層、2つの隠れ層、1つの出力層を定義すれば、基本的な畳み込みニューラルネットワーク (CNN) を作成することができる(詳細は別記事「今さら聞けない、AIの基本(その1)」ご参照)。画像データセットを訓練セットとテストセットに分け、訓練データをCNNのインプットとして提供すれば、モデルの訓練が完了する。
次に、テストデータセットを使用してモデルを試してみる。結果と答えを比較し、予測の精度をチェックする。これをモデル評価と呼ぶ。
モデルのパラメータを調整して精度を上げ、モデルを再訓練し、再評価する。(パラメータとは、例えば層の数や、訓練データの数など、精度に影響を及ぼす変数のこと。)モデルが納得行く精度になるまで、反復を続ける。これをモデル分析と呼ぶ。
モデルが完成したので、常時このMLエンジンを利用できるよう展開する。クラウド上で予測機能を持つサーバーを作成し、画像をアップロードして順次結果を見られるアプリやウェブサイトを作成する。これをモデル展開と呼ぶ。
ここまで、データ準備から展開まで、全ての作業を手動で完遂した。この手動でのモデル展開プロセスをレベル0と呼ぶ。
① モデル運用の自動化(実験)
生産量が増えてくると、日々手動でモデルを訓練するのは厳しくなる。そこで次にできるのは、自動化のための実験だ。TensorFlowのようなツールを用いて、データ検証・準備、モデル訓練、モデル評価、モデル検証の各ステップの指示を入力する。モデル評価の際は、各モデルの評価指標を比較させることで、最良のモデルを自動選択することができる。このプロセスがMLOps (機械学習運用)のレベル1だ。実験を設定すれば、あとは適切なデータが利用可能であることと、データセットに偏りがないことを確認するだけで良い。
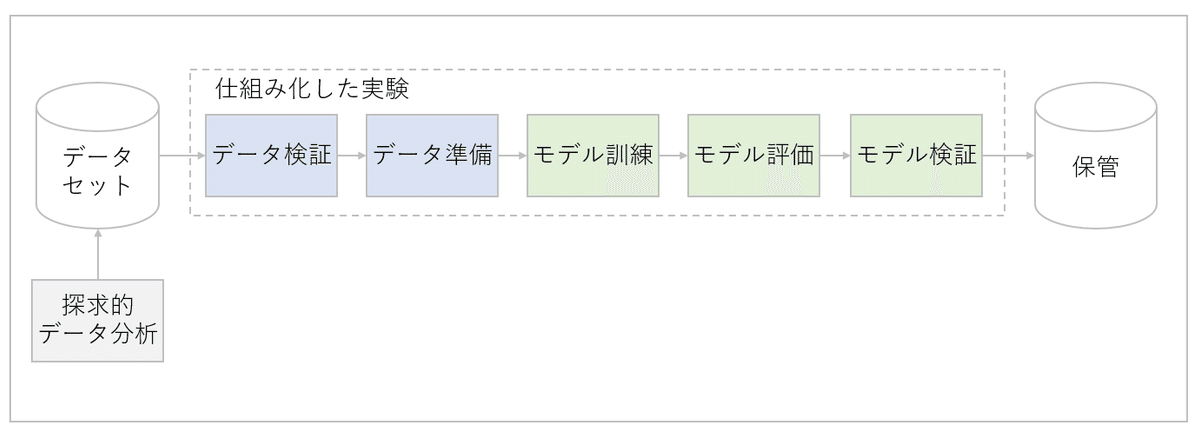
MLを駆使する殆どの企業は、このレベルの機械学習運用を達成している。また、これは個人のデータサイエンティストやMLエンジニアでも実現可能な水準だ。開発環境でモデルをテストするだけなら、これで十分である。
ここで、いくつかの質問を考えてみよう。
モデルは異なる種類のトマトでも結果を再現できるか?
新しいデータがデータセットに追加された場合、モデルは再訓練できるか?
モデルは一度に何十万人もの人々が使えるか?(うまくスケールするか?)
世界各地でモデルを展開する際、どのようにモデルをモニタリングするか?
これらのニーズに応えるには、レベル2への進化が必要となる。
② モデル運用の自動化(実装)

上記図を分解してみよう。
図の赤線より上は、先ほど説明したレベル1(実験)である。この実験自体が、自動化に必要なMLパイプライン(処理プロセス)の一部となる。
「特徴量」ストアを導入する。ここでは様々な情報源からデータを取得し、それらをモデルが必要とする特徴量(着目すべきデータの特徴。例えば、画像ピクセルのまとまりや、気温、湿度等)に変換する。MLパイプラインはこのストアからバッチ単位でデータを使用する。
MLパイプラインはメタデータストアに接続される。これは簿記のようなもの。モデルを手動で訓練しないため、ここにはパイプラインの各段階の記録がある。一つの段階が完了すると、次の段階が記録リストを参照し、前の段階の記録を見つけ、そこから作業を再開する。
モデルはモデルレジストリ(登記簿)に保存される。ここには様々な精度のモデルが多数保存されている。要件に基づき適切なモデルが選ばれ、継続的統合・展開(Continuous Integration / Continuous Delivery、略してCI/CD)パイプラインに送られ、予測サービスとして展開される。権限のあるユーザーは、必要に応じてこの予測サービスにアクセスできる。
最後に、このシステムの精度を監視する必要がある。例えば、遺伝子組み換えの新種トマトが登場したとする。モデルは新種を認識しないので、誤分類される可能性が高くなる。精度が低下したら、それがトリガーとなり、新しいデータでモデルが再訓練される。
このサイクルが続く。
精度が低下した場合は、新しいデータが利用可能なら、モデルの再訓練を行う。現実世界の変化がモデルに反映されるよう、モデルを最新の状態に保つことが重要だ。
まとめ
以上、農場のトマト収穫を例に、駆け足でMLOps(機械学習運用)の流れを説明させて頂いた。MLOpsが必要な理由は、主に以下のポイントに集約される。
機械学習モデルは膨大な量のデータに頼るため、追跡が難しい。
機械学習モデルで調整するパラメータの追跡は困難。小さな変更が結果に大きな違いをもたらすことがある。
モデルが扱う特徴量も追跡する必要がある。(有用な特徴量を作成するには、特徴量エンジニアリングという別のプロセスを通じた特徴量の精度向上が必要。)
機械学習モデルの監視は、展開されるソフトウェアやウェブアプリの監視とは異なる。
機械学習モデルのデバッグは非常に複雑。各ステップの分析が肝となる。
モデルは予測のために現実世界のデータを使うが、現実世界のデータが変化するとモデルも変化しなくてはならない。新しいデータの変化を追跡し、モデルがそれに応じて学習することを担保する必要がある。
より詳しく知りたい方には、Weights & Biasesの効果的なMLOps:モデル開発やCourseraのMachine Learning in Productionのコースをご覧頂くことをおススメしたい。
この記事が気に入ったらサポートをしてみませんか?