
Self-RAGに関連する情報を集めた

はじめに
RAGの興味深い点は、プロンプトエンジニアリングと非常に似た軌道をたどっていることです。RAGは、最初はコンテキスト参照データを用いたプロンプトインジェクションから成るシンプルで効果的なコンセプトとして始まりました。
RAGの主な目的は、LLM(In-Context Learning)の能力を活用することです。
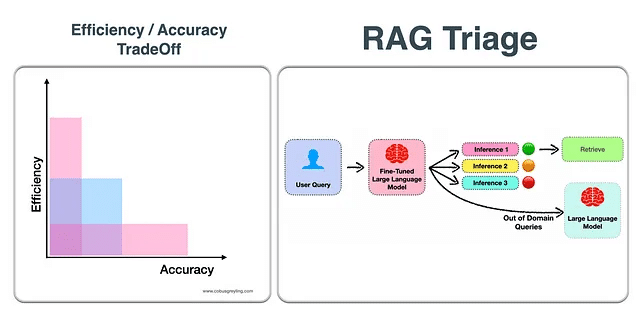
RAGには複雑さと効率の両方が伴います。リトリーバルはデフォルトで行われるわけではなく、ユーザーの要求をLLMが満たすことができるかどうかを判断するためにトリアージのプロセスが行われます。
効率と正確さのトレードオフ。効率と正確さの間には常にバランスが求められます。効率を犠牲にして正確さを追求すると、ユーザーエクスペリエンスや実用例に悪影響を与えます。一方、正確さを犠牲にして効率を追求すると、誤解を招く不正確な解決策につながります。
RAGを介して直接LLMの推論を行うか、プロンプトインジェクションを行うかを決定するためには、参照が必要です。Self-RAGの場合、セルフリフレクションを活用したファインチューニングされたLLMに対して行われます。
RAGのトリアージの原則は、さまざまな形で適用することができます。最も重要なのは、直接LLMからの質問を推論するか、RAGを利用するかを決定する際の参照です。そして、RAGを使用する場合には、応答の品質と正確さを評価できることです。
生成型AIベースのアプリケーションでは、直接推論やRAG以外の選択肢も考慮に入れることができます。たとえば、Human-in-the-loop、ウェブ検索、マルチLLMのオーケストレーションなどがあります。
Self-RAGとLLM、RAGの違い
大規模言語モデル(LLM)は広く使われていますが、パラメトリックな知識のみを使用するため、しばしば事実と異なる応答を提供したり、帰属(Attribution)を欠いていたり、ハルシネーションを起こし、特に時間た立つと共に、保有する知識は古くなっていきます。
Retrieval-Augmented Generation(RAG)は、この問題を解決するためのアプローチであり、品質保証(QA)などの知識集約的なタスクに対して効果がある事が実証されています。一方で、ランダムにデータを取得し、予め決められた数を取得したパッセージのを組み込むことは、LMの柔軟性を低下させたり、効果の無い応答生成につながる可能性もある事が課題として挙げられています。さらに、回答が引用された証拠によって生成されているかどうか、保証されません。
Self-RAGとは?
Self-Reflective Retrieval-Augmented Generation(Self-RAG)と呼ばれる新しいフレームワークは、リトリーバル+自己反映を使用して、言語モデルの品質と事実性を向上させます。反映トークン(Reflection Token)という独自のトークンを用いて、この手法はオンデマンドでパッセージを取得出来るよう、任意の単一の言語モデルをトレーニングします(例:生成中に1回取得するか、取得をスキップするか)。また、取得したパッセージと独自の生成物について作成し、反映します。反映トークンを生成することで、推論フェーズ中に言語モデルを制御可能にすることができ、さまざまなタスク要件に適応させることができます。
反映トークンとは?
反映トークンは、取得の必要性とその生成品質を示す取得トークンと批評トークンに分類されます。
Self-RAGは、反映トークンを使用して取得の必要性を決定し、生成品質を自己評価します。
反映トークンを生成することで、推論フェーズ中にLMを制御可能にし、さまざまなタスク要件に合わせてその動作を調整できます。
この研究では、Self-RAGがLLMおよび標準のRAG手法を大幅に上回ることが示されており、LLMや標準のRAG手法よりも優れた成績を収めています。
Self-RAGの特徴
広範囲に実施されたテストによると、Self-RAG(7Bおよび13Bのパラメータ)は、最も先進的なLLMやRAGモデルよりも顕著に優れたパフォーマンスを発揮します。特に、オープンドメインのQA、推論、事実検証のタスクにおいて、Self-RAGはChatGPTや検索拡張型のLlama2-chatよりも優れた結果を示します。これらのモデルと比較して、Self-RAGは長文生成において事実性と引用の正確さにおいても注目すべき改善を示しています。
Self-RAG は何ができるのか?
Self-reflection tokens を使用して、新しいフレームワークである Self-RAG は任意の LM を訓練し管理します。具体的には、各セグメント(たとえば文章単位)で、Self-RAG は次のことができます:
取得:
取得の価値を評価し、取得コンポーネントを管理するために、Self-RAG はまず取得トークンをデコードします。取得が必要な場合、当社の LM は入力クエリと前回の生成を使用して外部の取得モジュールを呼び出し、トップの関連文書を特定します。
生成:
標準の LM と同様に、取得が不要な場合、モデルは次の出力セグメントを予測します。取得が必要な場合、モデルはまず批判トークンを提供して取得した文書の関連性を評価し、その後、取得したセクションに基づいて継続を生成します。
批判:
モデルはまた、取得が必要な場合に、文章が生成を促進するかどうかを評価します。最後に、新しい批判トークンが応答の全体的な有用性を評価します。
Self-RAGの手順
LLMは取得したパッセージに基づいて情報を生成します。
特別なトークンを生成することを学習することで、出力を批判します。
これらの反射トークンは、取得の必要性を示したり、出力の関連性、サポート、または完全性を確認します。
一方、一般的なRAG手法は、引用された情報源からの完全なサポートを確認せずに、パッセージを無差別に取得します。

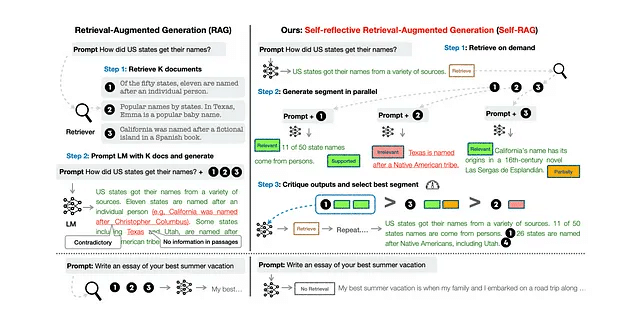
以下の画像を考慮すると...Self-RAGは、全体的な生成品質、事実性、検証可能性を向上させるために、テキストパッセージを取得し、批評し、生成する方法を学習します。
Self-RAGに関する考慮事項
追加の推論とコスト
Self-RAGは推論の面でより多くのオーバーヘッドを導入します。上記の画像を考慮すると、RAGへの自己反映的アプローチはより多くの推論点を導入します。
最初の推論ステップが実行され、3つの推論ステップが並行して実行されます。その3つの結果が比較され、RAG推論のために勝者が選択されます。
ドメイン外
また、上記の画像で見られるように、ドメイン外のクエリはそのように認識され、要求は検索を介して処理されず、直接LLM推論に送信されます。
主体的なRAG
画像を考慮すると、次の質問が必要です...
RAGプロセスに導入される複雑さを考えると、主体ベースのRAGアプローチが最も適しているのではないでしょうか?LlamaIndexが主体的RAGと呼ぶアプローチです。
意図
意図ベースのルーティングが使用され、生成的AIフレームワーク内でユーザー入力を適切に処理するために使用された研究があります。意図は単なる事前定義されたユースケースクラスです。

Self-RAGのトレーニング
Self-RAGのトレーニングには、Retriever、Critic、Generatorの3つのモデルが含まれています。
Criticをトレーニングし、Retrieverが回収した反射トークンとパッセージをさまざまな命令-出力データセットに追加します。Generator LMには、自分自身の生成物を回収または評価するための特別なトークンと自然な継続を生成するように教えるために、通常の次のトークン予測目標を使用します。
結果
6つのテスト全体で、Self-RAGはバニラChatGPTやLLama2-chatよりもはるかに優れたパフォーマンスを発揮します。また、一般的な回収増強技術を持つSOTAモデルを多くのタスクで上回ります。
Self-RAGが商業的に使われているLLMをどのように改善するか

大規模言語モデル(LLM)は、さまざまな産業で革新を起こしつつあります。金融部門の例を取ってみましょう。LLMは、同じタスクを繰り返し行うアナリストに比べて、非常に短い時間とコスト内で大量の文書を調査し、特定のトレンドを見つける事ができます。しかし一方では、問題も多く指摘されており、LLMから得られる回答が部分的であったり、不完全であったりする事が指摘されています。たとえば、過去15年間の企業Xの年間収益データが異なるセクションに含まれている文書がある場合を考えてみましょう。以下に示す標準的なRetrieval Augmented Generation(RAG)アーキテクチャの場合、通常、上位k個の文書を取得するか、固定されたコンテキスト長内の文書を選択します。

ただし、これにはいくつかの問題があります。
1つの問題は、上位k個のドキュメントにすべての回答が含まれていない、ということです。たとえば、過去5年または10年に対応する情報しか保有していない場合があります。
もう1つの問題は、ドキュメントのチャンクとプロンプトとの間の類似性を計算しても、関連するコンテキストが常に得られるとは限らないことです。この場合、誤った回答を得る可能性があります。
真の問題は、シンプルなケースでうまく動作するRAGアプリを開発したが、実用において他の人がこのプロトタイプを利用すると、テストでは使用しなかった質問をするため、上手く動作せず、失敗する、ということです。
ここで、Self-RAGが効果を発揮します。LM(Llama2–7Bおよび13B)を微調整し、特別なトークン[Retrieval]、[No Retrieval]、[Relevant]、[Irrelevant]、[No support / Contradictory]、[Partially supported]、[Utility]などを出力する賢い方法を開発しました。これらは、コンテキストが関連性/非関連性であるかどうか、コンテキストから生成されたLMのテキストがサポートされているかどうか、および生成物の有用性を決定するために追加されます。
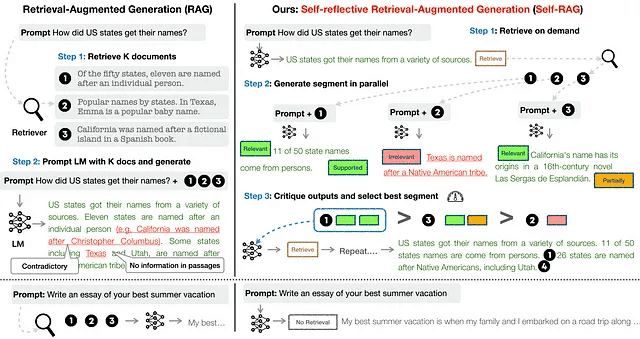
Self-RAGのトレーニング
Self-RAGは2段階の階層的なプロセスでトレーニングされました。
ステップ1では、生成された出力(プロンプトのみまたはプロンプト+RAG拡張出力)を分類するための単純なLMがトレーニングされ、関連する特別なトークンが末尾に追加されました。この「批評モデル: Critic Model」はGPT-4のアノテーション(Annotation)によってトレーニングされました。具体的には、GPT-4にタイプ固有の指示(「指示が与えられた場合、ウェブから外部ドキュメントを見つけることがより良い応答を生成するのに役立つかどうかについて判断してください。」)を使用してプロンプトされました。
ステップ2では、標準の次のトークン予測目的を使用して、生成モデルは継続を生成することを学習し、また特別なトークンを生成して生成物を取得/批評することを学習します。他の微調整やRLHF方法とは異なり、下流のトレーニングがモデルの出力に影響を与え、将来の生成物に偏りをもたらすことがありません。このシンプルなアプローチを通じて、モデルは適切な特別なトークンを生成するようにのみ訓練され、それ以外では基盤となるLMを変更しません。
Self-RAGの評価
論文では、公衆衛生の事実検証、多肢選択理論、Q&Aなどに対する多くの評価テストを実施しました。3種類のタスクが行われました。閉じたセットのタスクには事実検証と多肢選択理論が含まれ、精度が評価指標として使用されました。短文生成タスクにはオープンドメインのQ&Aデータセットが含まれていました。論文は、モデル生成にゴールドアンサーが含まれているかどうかを評価し、厳密な一致を必要としないようにしました。
長文生成のテストには伝記生成と長文QAが含まれていました。これらのタスクを評価するために、論文では伝記の評価にはFactScoreを使用しました。FactScoreは生成された情報のさまざまな要素と事実の正確さを測定するものです。長文QAについては、引用の精度と再珺(recall)が使用されました。

Self-RAG 評価
Self-RAGは、非独自のモデルの中で最も優れており、ほとんどの場合、13Bのパラメータが7Bモデルを上回っています。場合によっては、ChatGPTさえも上回ります。
推論
推論に関して、self-RAGリポジトリでは、LLM推論のためのライブラリであるvllmの使用を提案しています。
vllmをpipでインストールした後、以下のようにライブラリをロードしてクエリを実行できます。
from vllm import LLM, SamplingParams
model = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half")
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)
def format_prompt(input, paragraph=None):
prompt = "### Instruction:n{0}nn### Response:n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the difference between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))必要な情報を文字列として提供することができます。
paragraph="""Llamas range from 200 to 350 lbs., while alpacas weigh in at 100 to 175 lbs."""
def format_prompt_p(input, paragraph=paragraph):
prompt = "### Instruction:n{0}nn### Response:n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the differences between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt_p(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))[Irrelevant]Whatsapp is the odd one out.
[No Retrieval]Twitter and Instagram are both social media platforms,
while Whatsapp is a messaging app.[Utility:5]
[Relevant]Llamas are larger than alpacas, with males weighing up to 350 pounds.
[Partially supported][Utility:5]上記の例では、最初のクエリ(ソーシャルメディアプラットフォームに関連する)では、(リトリーバルの冒頭にある[Irrelevant]トークンによって示されるように)段落の文脈は無関係です。しかし、第二のクエリ(ラマとアルパカに関連する)に対しては、外部の文脈が関連しています。生成された文脈には、[Relevant]トークンで示される情報が含まれています。
ただし、以下の例では、「アボカドが好きです。」という文脈はプロンプトとは関係ありません。以下のように、モデルの予測は両方のクエリに対して最初は[関係なし]となり、単に内部情報を使用してプロンプトに答えます。
paragraph="""I like Avocado."""
def format_prompt_p(input, paragraph=paragraph):
prompt = "### Instruction:n{0}nn### Response:n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the differences between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt_p(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))Model prediction: [Irrelevant]Twitter is the odd one out.[Utility:5]
[Irrelevant]Sure![Continue to Use Evidence]
Alpacas are a much smaller than llamas.
They are also bred specifically for their fiber.[Utility:5]Self-RAGの利点
Self-RAGには、通常のLLMに比べていくつかの利点があります。
適応的なパッセージ検索:これにより、LLMは関連するコンテキストがすべて見つかるまで(もちろんコンテキストウィンドウ内で)コンテキストを取得し続けることができます。
より関連性の高い検索:埋め込み型のモデルは、多くの場合、関連するコンテキストを最適に取得することができません。Self-RAGは、関連性/非関連性の特別なトークンを使用することで、これを解決する可能性があります。
他の類似モデルを上回る:Self-RAGは他の類似モデルを上回り、驚くほどChatGPTを多くのタスクで上回ります。ChatGPTがトレーニングされていないデータと比較することは興味深いでしょう。つまり、より独自のエンタプライズのデータを使用した比較です。
基礎となるLMを変更せずに済む:これは非常に大きな利点です。なぜなら、微調整やRLHFが簡単にバイアスのあるモデルにつながってしまうことを知っているからです。Self-RAGでは特別なトークンを追加する事で解決し、それ以外はテキスト生成を同じままにすることで対応できます。
改善の余地があるとすれば、固定されたコンテキストの長さに対処するところです。これはSelf-RAGに要約コンポーネントを追加することで実現できるかもしれません。実際、これに関連した以前の研究があります(例: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation)。
もう一つの興味深い方向性は、OpenAIから発表されたコンテキストの長さウィンドウの拡大です。GPT-4 128kコンテキストウィンドウのアップデートが行われました。ただし、フォーラムで言及されているように、このコンテキストウィンドウは入力の長さを表し、出力制限は引き続き4kトークンです。
推論コードはこのGitHubリポジトリにあります:
事例:ハリー・ポッターと自己学習ナレッジグラフRAG
このデモでは、私たちはRAGのナレッジグラフの3つの主要な強力なアプリケーションをデモし、それがRAGの精度を向上させ、製品化までの時間を劇的に短縮し、自己学習RAGの最初の例の1つである方法を示したかったのです。
再帰的検索
オンデマンドオントロジー/自動ナレッジグラフ
メモリとマルチホップ推論
ビデオリンク: https://x.com/chiajy2000/status/1750573481971134811?s=20
このデモでは、ハリーポッターの本の章をアップロードし、新しい章が追加されるたびに自動的な知識グラフが構築される様子を見ます。知識グラフは、特定の質問に関連する関係やエンティティを検出しキャプチャするために構築され、ランダムな粒度の関係やエンティティをすべてキャプチャするのではなく、その質問に対応するものです。この形式では、時間の経過とともに再帰的に知識グラフを取得し、反復的に構築するように設定でき、新しい情報が導入されるたびにそれを行うことができます。
その後、知識グラフが自動的に結合しマージする方法を示し、別々の質問がされるたびに作成されるミニ知識グラフに基づいて学習することができるようにします。これにより、質問がされるたびに時間の経過とともに学習することができます。これにより、この自動化された知識グラフツールに質問のリストを投げるだけで、関連する知識ベース/第二の脳を作成することができます。開発プロセスを簡素化するだけでなく、この知識ベースはLLMのためのメモリツールとして機能し、簡単にマルチホップの推論を行うことができます。
私たちのテックスタックでは、Langchain、Pinecone Serverless、OpenAIを使用しました。
再帰的な取得
知識グラフは、単一の概念を中心に情報を修正し、繰り返し取得するコンテキストストアとして機能することができます。
このミニ知識グラフは単一の概念であるため、取得はよりスコープが狭く、構造化されており、その概念を含む質問に焦点を当てています。これにより、時間をかけて複数の文書や異なるチャンクにわたる単一の概念に関連するデータを取得することができます。
時間をかけた取得に関しては、RAGシステムが常にベクトルデータベースに新しい更新を持ち、新しい情報が流れ込んで歴史的に存在する回答に追加したい場合を想像してみてください。これが可能になります。
異なるチャンクを対象とした取得に関しては、質問の中心概念に関連する情報が多くの異なる文書やページに分散している場合を想像してみてください。これを自動的に取得し構造化することができます。
知識グラフは、焦点となる関連する概念に繰り返し情報を追加するコンテキストに意識したフィルターとして機能します。
オンデマンド知識グラフ
概念的なレベルでは、知識グラフは単純なものです。それは概念間の決定論的な関係を作成することで、物事がどのように関連しているかを理解できるようにします。
知識グラフを使用して構築することに新しい人々が直面する最大の問題は、適切なコンテキストに対して適切なオントロジーを構築することを理解することです。
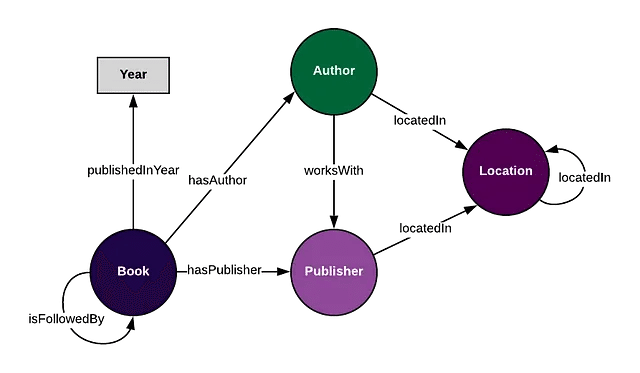
オントロジーとは、基本的にはグラフ内で追跡したい概念と関係です。上記のグラフでは、「著者」という概念や「hasAuthor」という関係がすべてオントロジーの一部であり、それは作成者が考えている特定の文脈において有用であることを期待しています。
LLMと特定の質問の文脈を考慮すると、作成されるオントロジーは大きく異なる場合があります。同じドメイン内でも、異なる質問には異なるオントロジーが存在します。
上記のデモでは、LLMによってコンテキストに応じた知識グラフの作成を可能にするワークフローを構築しました。質問に応じて、知識グラフはその質問に特に関連する概念と関係のみを捉えます。これは、大規模な知識グラフ内のあらゆる種類の関係やエンティティを捉えることよりも、特定の文脈や質問に関連する関係やエンティティに焦点を当てる方が効率的であるという私たちの信念に関連しています。
ここでの重要なステップは、知識グラフの構築を人間が介入して管理するためのワークフローツールを含めることです。現時点ではかなり遠い未来のことですが、時間の経過とともに、モデル自体が関連するミニ知識グラフの作成をより多く自動化できるようになると予想しています。ただし、一般的に知識グラフやLLMの採用が増えると、要求されるユースケースの数や細かい制御の粒度も増加し、現在存在しないものとなるでしょう。
メモリとマルチホップ推論
ハリーポッターのデモを通じて、質問「ハリーは何を着ていますか?」から作成された最初のミニ知識グラフが、ハリーに関する概念に関するコンテキストメモリとして保存されていることがわかります。
概念的に関連する質問「ダンブルドアは何を着ていますか?」がなされると、第二のミニ知識グラフが作成され、重なり合う関係を検出し、自動的に最初のミニ知識グラフに同期されます。
これは、RAGパイプライン内のメモリのデモンストレーションであり、具体的にはハリーポッターのミニKGのものです。その後、「ハリーとダンブルドアは何を着ていますか?」という最後の質問がなされると、検索が実行されると、LLMはまず関連する関係と事実をメモリストアでチェックします。それは、ハリーとダンブルドアの共通グラフが取得に関連しており、'ハリー'&'ダンブルドア'&'を持っている'に関連するものを取得します。これは、異なる文書間で異なるエンティティが共有する概念的関係を連結し、トラバースする単一の取得アクションで行われるマルチホップ推論です。
メモリは、異なるページや文書からの概念を横断的に推論するためにLLMが必要とする主要なプリミティブです。
RAGパイプラインに知識グラフシステムを実装することの非常に興味深い結果の1つは、システム内でのコンテキスト収集のインテリジェントな性質により、RAGシステムをMLエンジニアにとって馴染みのある方法でテストできることです。つまり、数百もの合成的な質問をRAGシステムに投げ、知識グラフとコンテキストを時間の経過とともに自動的に構築させることができます。これは、自己学習型のRAGシステムを作成する方法の最初の例の1つになるでしょう。
メモリ、自動化された知識グラフ、マルチホップ推論、および再帰的取得は、正確で高度なRAGシステムの非常に重要な部分です。これらがどのようにして高度なRAGテクニックが結集して、ますますスマートなRAGシステムを作り上げるか、そのあり方を示しています。
論文レビュー:Self-RAG:自己反省 (Self Reflection) を通じて検索、生成、批評の機能を学ぶ
https://arxiv.org/pdf/2310.11511.pdf
概要
この論文は、従来の自然言語処理のRetrieve-And-Generate(RAG)モデルの機能を拡張する革新的なSelf-RAGアプローチを紹介しています。Self-RAGは、タスクに必要かどうかに関係なく、一貫して生成のために固定数のドキュメントを取得し、生成の品質を再評価しないという点で従来のRAGモデルとは異なります。Self-RAGの注目すべき特徴の1つは、生成されたセグメントごとに引用文を提供し、取得されたパッセージによって出力がサポートされているかどうかの自己評価を行う能力です。この機能により、事実の検証が容易になります。モデルは、反射トークンを使用してテキストを生成するようにトレーニングされており、これらは拡張されたモデル語彙からの次のトークン予測として統合されます。反射トークンは、強化学習で使用される報酬モデルに触発されたものであり、トレーニングされた批評家モデルによって元のコーパスに挿入されます。このアプローチにより、トレーニング中に批評家モデルをホストする必要がなくなり、オーバーヘッドが削減されます。批評家モデルは、プロプライエタリな言語モデルにプロンプトを提示して収集されたデータセットに部分的に監督されます。Self-RAGには、反射トークンの予測によって定義された特定の制約を満たすためのカスタマイズ可能なデコーディングアルゴリズムがあります。これにより、反射トークンの確率を使用したセグメントレベルのビームサーチを可能にし、取得頻度の柔軟な調整やユーザーの好みに応じたモデルのカスタマイズが実現されます。
Self-RAGは、より多くのパラメータを持つ事前学習および命令チューニングされた大規模言語モデル(LLM)や広く採用されているRAGアプローチよりも、著しく性能が向上しています。引用の正確さが高く、推論を含む様々なタスクで、検索拡張型ChatGPTなどのモデルを上回り、推論トークンを使用したトレーニングと推論の効果が強調され、引用の精度と完全性のトレードオフのバランスをとるなど、全体的な性能とテスト時のモデルカスタマイズが向上しています。
推論中、各入力「x」と直前の生成物「y<t」に対して、モデルは検索トークンを用いて検索の必要性を評価し、デコーディングプロセスを開始します。検索が不要と判断された場合、モデルは次の出力セグメントを予測し、標準言語モデル(LM)の振る舞いに似た動作をします。しかし、検索が必要な場合、モデルはより複雑なプロセスに従います。つまり、検索されたパッセージの関連性を評価するために批評トークンを生成し、次の応答セグメントを予測し、応答の情報がパッセージと整合しているかどうかを評価するために別の批評トークンを使用します。最後に、新しい批評トークンが応答の全体的な有用性を評価します。各セグメントを生成するために、Self-RAGは複数のパッセージを効率的に並列処理し、自己生成の反射トークンを使用してソフト制約またはハード制御を強制します。
トレーニング中、Self-RAGは、拡張されたモデル語彙の中で反射トークンを次のトークン予測として扱うことで、どんな言語モデルでもテキストを生成する力を与えます。この拡張された語彙には、元の語彙と新しく導入された反射トークンが含まれています。トレーニングプロセスには、キュレーションされたコーパスでトレーニングされる生成モデル「M」が関与します。このコーパスには、リトリーバーモデル「R」によって取得された交互に挿入されたパッセージと、批評者モデル「C」によって予測された反射トークンが含まれています。批評者モデル「C」のトレーニングは、取得されたパッセージとタスクの出力の品質の両方を評価するために反射トークンを生成することに焦点を当てています。批評者モデルを利用することで、トレーニングコーパスはオフラインで行われるタスクの出力に反射トークンを挿入することで更新されます。その後、最終的な生成モデル「M」は従来のLM目的を使用してトレーニングされます。このトレーニングにより、「M」は推論中に独自に反射トークンを生成し、批評者モデルへの依存が不要となります。
6つのタスクを対象とした包括的な評価により、複数の指標を使用して、Self-RAGは、より多くのパラメータを持つ大規模な言語モデル(LLMs)や従来の検索拡張生成手法と比較して、優れたパフォーマンスを明確に示しています。

LLMsは固定された知識によって正確でない応答を生成する可能性があります。RAGは関連する知識を取得することで精度を向上させますが、汎用性を低下させることがあります。自己反映型のRetrieval-Augmented Generation(RAG)フレームワークは、適応的に情報を取得し、reflection tokensを使用してその出力を反映することで、これらの課題に対処します。この適応性により、モデルはさまざまなタスクに対応できます。実験では、Self-RAGがオープンドメインのQA、推論、事実の検証、長文のコンテンツ生成などのタスクで、ChatGPTやLlama2-chatを上回ることが示されています。
詳細 - セルフ-RAG:取得、生成、批評の機能を学ぶ

問題の形式化と概要

Self-RAGモデルは、複数のセグメント(セグメントは文である)を持つテキスト出力を生成するために訓練されています。これらのセグメントには、元の語彙と特別なreflectionトークンが含まれています。推論中、モデルは追加情報を取得する必要があるかどうかを決定します。取得が不要な場合、モデルは標準的な言語モデルのように進行します。取得が必要な場合、モデルは取得したパッセージの関連性、応答セグメントの正確性、および批評トークンを使用して応答の全体的な有用性を評価します。モデルは複数のパッセージを同時に処理し、ガイダンスのためにreflectionトークンを使用します。
トレーニングでは、モデルは反射トークンを生成するためにそれらを語彙に統合することを学習します。取得したパッセージと批評モデルによって予測された反射トークンを含むコーパスで訓練されます。この批評モデルは取得したパッセージとタスクの出力の品質を評価します。訓練コーパスは反射トークンで更新され、最終モデルは推論中にこれらのトークンを独立して生成するように訓練されます。
Self-RAGトレーニング

批評モデルを訓練するには、反射トークンに手動で注釈付けをする処理が大きくなります。GPT-4のような高価な専用モデルに頼る代わりに、著者はGPT-4に反射トークンを生成するよう促し、その知識を社内の批評モデルに移すようにします。異なる反射トークングループには、少数のデモンストレーションを伴う具体的な指示で促します。例えば、Retrieveトークンには、外部ドキュメントが応答を改善するかどうかを判断するよう指示されます。
与えられた指示に基づいて、ウェブから外部文書を見つけることが、より良い応答を生成するのに役立つかどうかを判断します。
GPT-4の反射トークンの予測は、人間の評価とよく一致しています。各トークンタイプについて4,000から20,000のトレーニングデータが収集されます。トレーニングデータが収集されたら、批評家モデルは事前にトレーニングされた言語モデルで初期化され、標準の条件付き言語モデリング目的を使用してトレーニングされます。批評家に使用される初期モデルはLlama 2-7Bであり、ほとんどの反射トークンカテゴリにおいてGPT-4の予測と90%以上の一致を達成しています。
生成モデルをトレーニングするために、元の出力は検索と批評家モデルを使用して推論プロセスをシミュレートします。各セグメントについて、批評家モデルは追加のパッセージが生成を改善するかどうかを判断します。その場合、「Retrieve=Yes トークンが追加され、トップKのパッセージが取得されます。その後、批評家は各パッセージの関連性とサポート性を評価し、それに応じて批評トークンを追加します。最終的な出力には反射トークンが追加されます。
生成モデルは、標準の次のトークン目的を使用して、この拡張されたデータで訓練されます。この目的は、ターゲットの出力と反射トークンの両方を予測します。訓練中、取得したテキストチャンクはマスクされ、語彙は反射トークンCritiqueとRetrieveで拡張されます。このアプローチは、PPOなどの別個の報酬モデルに依存する他の方法よりもコスト効果が高いです。Self-RAGモデルは、自分自身の予測を制御し評価するための特別なトークンも組み込んでおり、より洗練された出力生成が可能です。
Self-RAG 推論
Self-RAGは、反射トークンを使用して自分自身の出力を評価し、推論中に適応することができます。タスクに応じて、モデルは、より多くのパッセージを取得して事実の正確さを重視したり、オープンエンドのタスクでは創造性を重視するように調整することができます。モデルは、パッセージを取得するタイミングを決定したり、取得をトリガーするための閾値を使用することができます。
取得が必要な場合、生成器は複数のパッセージを同時に処理し、異なる継続候補を生成します。セグメントレベルのビームサーチ (beam search) が行われ、トップの継続を取得し、最良のシーケンスが返されます。各セグメントのスコアは、各批評トークンタイプの正規化された確率の加重合計である批評スコアを使用して更新されます。これらの重みは推論中に調整してモデルの動作をカスタマイズすることができます。振る舞いを変更するために追加のトレーニングが必要な他の方法とは異なり、Self-RAGは追加のトレーニングなしに適応することができます。
実験

Self-RAGは、複数のタスクで常にさまざまなベースラインを上回っています。
検索なし:
Self-RAGは、すべてのタスクで監督されたファインチューニングされたLLMを大幅に上回っています。PubHealth、PopQA、伝記生成、ASQAなどのタスクでも、ChatGPTを上回っています。また、バイオ生成タスクにおいては、プロンプトエンジニアリングを使用する同時手法であるCoVEをも上回っています。
検索あり:
Self-RAGは、多くのタスクで既存のRAGモデルを上回り、非特許のLMベースのモデルの中で最良の結果を達成しています。検索を使用した一部の指示チューニングされたLMは、PopQAやBioなどのタスクで成果を上げていますが、検索されたパッセージからの直接抽出が困難なタスクでは成果が出ていません。ほとんどの検索ベースラインは、引用の正確さに苦労しています。しかし、Self-RAGは引用の精度と再現率に優れており、引用の精度でさえChatGPTを上回っています。興味深いことに、より簡潔で基盤のある出力を生成する傾向があるため、小さなSelf-RAG 7Bが13Bバージョンを上回ることがあります。

結果は、Self-RAGと「No Retriever」または「No Critic」のベースラインとの間に、顕著なパフォーマンスの差が示され、これらのコンポーネントの重要性が強調されました。関連性を考慮せずにトップのパッセージのみを使用するか、または単に関連性スコアに依存することよりも、Self-RAGの微妙なアプローチの方が効果的でした。

Self-RAGのパフォーマンスにおけるトレーニングデータサイズの影響を調査するために、元の150kのインスタンスから5k、10k、20k、および50kのサブセットでモデルを微調整しました。一般的に、データが増えるとパフォーマンスが向上し、特にPopQAとASQAで顕著でした。Self-RAGのトレーニングデータを150kを超えて拡大することで、さらなる潜在的な利益を得ることが可能です。
Self-RAGの人間による評価では、Self-RAGの回答が妥当で関連性のある証拠によって支持されていることが示されています。
参照文献:
この記事が気に入ったらサポートをしてみませんか?