
AutoHyDE: 次世代のRAG開発のための手法(HyDEを拡張したAutoHyDEの紹介)

元データ: AutoHyDE: Making HyDE Better for Advanced LLM RAG | by Ian Ho | Apr, 2024 | Towards Data Science
AutoHyDE:高度なLLM RAG向けにHyDEをより良くする
HyDEの高度なLLM RAGに対する取り組みの紹介+ AutoHyDEの紹介:HyDEの効果、カバレッジ、適用性を向上させるためのフレームワーク
はじめに
情報検索増強生成(RAG)の分野では、仮説的文書埋め込み(Hypothetical Document Embeddings:HyDE)が、取得された文書の関連性を向上させるための強力なクエリ書き換え手法として証明されています。従来の検索は単に元の入力を使用して埋め込みベクトルを作成するだけでしたが、HyDEは、取得されるべき索引文書の埋め込み空間により関連性の高い埋め込みベクトルを生成する方法論です。
簡単に説明すると、次の処理を行います:
ユーザー入力から仮説的文書を作成する
仮説的文書を埋め込みに変換する
埋め込みを使用して類似の文書を取得する
RAGと基本的なHyDEをいくつかの仕事や個人プロジェクトで使用してきましたが、既存のHyDEの実装が常にうまく機能せず、期待していたほど柔軟ではないことに気付き、方法論についての研究を行い、論文やソースコードを調査した結果、現在のアプローチについての考えを共有し、より効果的でさまざまなユースケースで適応可能なHyDEの強化バージョン(AutoHyDEと呼んでいます)を提案したいと思います。
この記事は次のような構成です。
セクション1:元のHyDE論文に詳しく触れ、LangChainの実装にどのように変換されたかを説明します。
セクション2:現在のHyDEアプローチの主な制限について議論します。
セクション3:HyDEのより良いバージョンと考えるものであるAutoHyDEを紹介します。AutoHyDEは、索引文書の基礎となる関連性パターンを自動的に発見し、これらの関連性パターンを直接表す仮説的文書を生成するフレームワークです。
また、LangChainのHypotheticalDocumentEmbedderクラスを直接調整して、AutoHyDEを実現しました。これにより、LangChainの他の部分とも連鎖させることができます。
詳細については、リポジトリ、デモ、およびソースコードをご覧ください。

セクション1: HyDEとは?
HyDE: オリジナル論文
架空の文書埋め込み(HyDE)は、最初にGaoらによって2022年の論文で紹介されました。その論文のタイトルはRelevance Labelsなしでの正確なゼロショット密な検索(Zero-Shot Dense Retrieval )です。
この論文では、セマンティック埋め込みの類似性を使用したゼロショット密な検索を改善する方法を見つけることを目指しています。そのために、彼らはHyDEと呼ばれる2段階の方法論を考案しました。
ステップ1では、言語モデル(論文ではGPT-3を使用)に指示して、元のクエリ(論文内の質問に限定されたもの)に基づいて架空の文書を生成させることが含まれています。
ステップ2では、この架空の文書を埋め込みベクトルに変換するためにContrieverまたは「教師なし対照エンコーダ」を使用し、その後、下流の類似性検索と検索に使用されます。

HyDE方法論のイラストは、元の論文から取得可能。
[オプション] Contrieverについて
元のHyDE論文で使用されているContrieverは、2022年8月にIzacardらによって発表された論文「Unsupervised Dense Information Retrieval with Contrastive Learning」から派生しています。この論文では、著者らはニューラルネットワークが検索のための用語頻度法の良い代替手法として登場したが、大量のデータが必要であり、常に新しい応用領域に適用できるわけではないと主張しています。そのため、彼らはコントラスティブラーニングを用いて埋め込みネットワークを非監督学習する方法を考案しました。
コントラスティブラーニングに興味がある方は、情報を得るために論文のセクション3を参照できますが、ここでは高レベルな要約を紹介します。
まず、彼らは損失関数(コントラスティブInfoNCE損失)を定義し、文書の正のペアを報酬し、負のペアを罰するようにします。次に、文書表現の正のペアを構築します。正のペアは、逆クローズタスク(ICT)と独立したクロッピングというデータ拡張手法を使用して構築されます。負のペアは、バッチ内負のサンプリングとバッチ間負のサンプリング(MoCoとも呼ばれる)を使用して構築されます。最後に、これをBERTベースの小文字化されたアーキテクチャでトレーニングします。
論文の結果は、この方法がBM25などの非監督学習用語頻度法と一致し、また用語一致法では不可能なクロスリンガル検索でも優れたパフォーマンスを示したことを示しています。
この記事の目的上、トレーニングとデータ拡張の詳細についてはさらに掘り下げませんが、興味がある場合は論文をご覧ください。ContrieverはHuggingFaceのリンクで見つけることができ、研究リポジトリはこちらにあります。
とにかく、HyDE論文では、このContrieverを使用して生成された文書を埋め込みます。また、監督学習でドメイン内で微調整されたContrieverFTも探求しています。さて、記事の主題であるHyDE論文に戻りましょう。
HyDE論文に戻る
以前、HyDE方法論とその基盤となるcontrieverの起源について概要を提供しました。さて、論文からいくつかのキーとなる抜粋を見て、HyDEで何が起こっているのかを詳しく見てみましょう。
…第2ステップでは、非監督対照エンコーダを使用してこのドキュメントを埋め込みベクトルにエンコードします。ここでは、エンコーダの密なボトルネックが、余分な(幻覚的な)詳細が埋め込みから取り除かれる損失圧縮器として機能することを期待しています。このベクトルを使ってコーパスの埋め込みと照合します。
より形式的には、仮想的なドキュメント埋め込みベクトルは次のように定義されます:
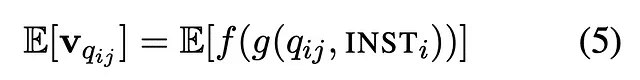
HyDE Paper で生成された文書をエンコードするための式
ここで、g は仮想的な文書生成の最初のステップでの InstructLM(query, INST) 関数であり、
そして、f は文書エンコーダー (contriever) である
“厳密には、g は連鎖規則に基づく確率分布を定義し、V は以下の式を用いて推定される”

HyDE Paper内の埋め込みベクトルを推定するための式
元の論文では、このリポジトリでPythonの実装も見つけることができます。ここでは、
fはリポジトリで見られる生成関数です: *
def generate(self, query):
prompt = self.promptor.build_prompt(query)
hypothesis_documents = self.generator.generate(prompt)
return hypothesis_documents指定されたリンクから関数を生成します:texttron/hyde
gはリポジトリで見られるエンコーディング関数です:
def encode(self, query, hypothesis_documents):
all_emb_c = []
for c in [query] + hypothesis_documents:
c_emb = self.encoder.encode(c)
all_emb_c.append(np.array(c_emb))
all_emb_c = np.array(all_emb_c)
avg_emb_c = np.mean(all_emb_c, axis=0)
hyde_vector = avg_emb_c.reshape((1, len(avg_emb_c)))
return hyde_vector
texttron/hyde からの encode 関数推定式と同様に、単純な平均化が使用されて、様々な仮想的な文書にわたる埋め込みベクトルを推定することがわかります。この平均集約された埋め込みは、その後、類似性検索に使用されます。
全体的に、HyDEは実装が本当に複雑ではないことがわかります。生成、埋め込み、平均、取得。
さて、最近登場したHyDEの人気のある実装を見てみましょう。
LangChainの実装
LangChainとLlamaIndexの両方には、論文やリポジトリで見たものに類似したHyDEの実装があります。LLMの機能を試しているほとんどの人にとって、これらがHyDEを使用する最もありそうな方法です。また、これらのHyDEクラスの下で使用されているプロンプトにもっと詳しく見ていきます。LangChainの実装に焦点を当てましょう。参照用のリポジトリはこちらです。
from_llmコンストラクターにおけるHypotheticalDocumentEmbedderのlangchain/hyde
最初のステップは、from_llmを使用してHypotheticalDocumentEmbedderを作成することです。既存のプロンプトテンプレートの1つを選択することができます。以下にニュース記事を書くためのものが表示されています。または、独自のカスタムプロンプトを定義することもできます。
trec_news_template = """Please write a news passage about the topic.
Topic: {TOPIC}
Passage:"""その後、embed\_query を実行できます。これにより、ますます生成された架空のドキュメントがプロンプトテンプレートに基づいて生成され、その後これらのドキュメントが埋め込まれて結合されます。embed\_documents 関数は単純に、from\_llm 定義から定義された base\_embeddings を使用します。一方、combine\_embeddings は平均集約です。
langchain/hyde の embed\_query 関数
また、List[str] 型の documents に注目すると、複数のドキュメントを生成できるためです。ただし、from\_llm ステップで LLM を適切に定義する必要があります。以下に例を示します:
multi_llm = OpenAI(n=4, best_of=4)
embeddings = HypotheticalDocumentEmbedder.from_llm(
multi_llm, base_embeddings, "web_search"
)
result = embeddings.embed_query("Where is the Taj Mahal?")HyDEの使用方法についての簡単な解説については、notebookを参照してください。それほど複雑ではなく、LangChainは基本的な機能のほとんどを抽象化して使用しやすくしています。
セクション2: HyDEの制限
HyDEの設計とLangChain&LlamaIndexライブラリでの実装についての良い理解が得られたので、その制限について話したいと思います。
最初に気づいたことは、HyDE論文が異なる命令LLMを実験している一方で、HyDEプロセスのこの側面をさらに最適化することについてあまり時間を割いていないことです。論文の表4から、異なるモデルを使用するとかなり大きな結果のばらつきが生じることがわかります。

HyDEの結果は、HyDE Paperで異なるLLMを使用することによって生じます。
ここでの重要な含意は、最も多くのパラメータを持つ最大のモデルを使用しないことです。代わりに、基盤となるLLMが全体的な検索関連のタスクに対して非常に大きな違いをもたらすという事実は、異なるLLMを使用することに加えて、生成タスクはさらなる最適化の価値があると私を説得します。
実際、研究者自身も次のように述べています。
InstructGPTモデルはパフォーマンスをさらに向上させることができる... これは、ファインチューニングされたエンコーダーでは捉えられない要因がまだ存在する可能性を示唆していますが、それは生成モデルだけが捉えるものです。
その可能性を考えると、セクション1のLangChainの詳細な説明からも、プロンプトテンプレートは仮想的な文書を指示するために事前に決められていることがわかります。例えば、「主張を支持/反論するための科学論文の一節を書いてください」。これは、クエリ/入力がこれらの事前に定義されたテンプレートにうまく適合する場合にのみ機能します。それ以外の場合、仮想的な文書を生成するためにカスタムテンプレートを提供することもできますが、これにも制限があります。
第一に、既存の実装は主にQ&Aフレームワークに限定されています。現実世界では、全ての検索ユースケースが質問に答えるためのものではないため、したがってLLMに仮想的に質問に答えるように求めることは意味がありません。したがって、これ以外の状況では、LLMに仮想的に何を生成させるのでしょうか?はい、カスタムプロンプティングは可能ですが、書いたプロンプトが実際に既存の文書に関連している保証はありません。基盤となる文書が関連パターンについて非常に均一でない限り、これらのパターンを捉えるためのプロンプトを書くことは非常に手作業で完璧でないプロセスになるでしょう。
さらに重要なことに、文書をチャンク化してインデックス化する際、チャンクは常にスタイル、トーン、構造などで均質ではありません。そのため、入力に基づいて仮想的な文書を生成するために単一の一般的なプロンプトを使用することは不十分であり、異なる種類のチャンクに対応するために複数のプロンプトを書くことは非現実的です。例えば、ブログ投稿の仮想的な文書を生成しようとしていると想像してください。異なる著者、トーン、執筆スタイルがある場合、この多様性を捉える一般的なプロンプトをどのように作成するのでしょうか?したがって、HyDEの現在の実装は、カバレッジの観点から見てかなり硬直しており、最適でないように見えます。
より技術的なレベルでは、最終的なベクトル埋め込みに関して、論文は次のように述べています。
私たちは単峰分布であると仮定し、v_qijの分布を期待値として考えるだけです。つまり、クエリが曖昧でないとします。
しかし、考えてみると、ほとんどの人間は曖昧さを伴う検索問題に取り組んでいます。
これは重要な警告です。実際の使用例では、クエリが1つまたは2つのキーワードほど曖昧である場合、vの分布が実際にはきれいな単峰分布ではないと想像できます。これは、同じ基本的なクエリが複数のベクトル埋め込み表現のモードにマッピングされる可能性があることを意味します。
HyDEを改善するためにはどのように始めればよいでしょうか?
HyDEは監視されていないように見えます。HyDEではモデルはトレーニングされません:生成モデルとコントラストエンコーダーの両方がそのまま維持されます。
HyDEの非監視の性質は重要です。なぜなら、密な検索のための監視された手法には巨大なデータセットや膨大な計算量が必要なくなるからです。
ただし、厳密に監視されたままでいることにより、いくつかの利点を失います。具体的には、文書埋め込みにより適合する複数の生成関数g(q, INST)を動的に定義する方法がありません。
その代わりに、より適応性があり汎用性のある半監督アプローチを考慮する価値があるかもしれません。このアプローチでは、仮想的な文書の生成を単一の事前定義/カスタムプロンプトに強制的に適合させる必要はありません。LangChain/LlamaIndexの実装とは異なり、カスタムプロンプトを書く必要すらありません。
代わりに、HyDEの強化版は、基本的な検索以上にさまざまな関連パターンを自動的に学習し、インデックス化されたチャンクの異なるクラスタに適合する仮想的な文書を生成します。このアプローチをAutoHyDEと呼びます。
AutoHyDEについてさらに詳しく話す前に、現在のHyDEの実装に関して最後に触れたい点があります。AutoHyDEではこれには触れませんが、それには一定の注意が必要だと思います。
再び埋め込み間の平均化式を思い出すと、次のコード行として現れます。
list(np.array(embeddings).mean(axis=0))シンプルな集約ですが、特に埋め込みの多様な分布を考慮すると、あまり意味がありません。たとえば、すべてのドキュメントチャンクにわたる関連パターンの多様性をうまく捉える連鎖エンコーディング関数 f(g(q, INST)) を構築できたとしましょう。これらの多様な分布されたエンコーディングを平均すると、全く関連性のない平均値になる可能性があります(Jensenの不等式のような平均化を考えてください)。もちろん、これは単一モードの分布の場合にはうまく機能しますが、これはほとんど現実的な仮定ではなく、普遍的に検証する方法はありません。
とにかく、AutoHyDE について話しましょう。
セクション3:AutoHyDE
概要
要約すると、AutoHyDEの主なポイントは、ベクトルデータベース内のさまざまな関連パターンを自動的に発見し、これらのパターンのカバレッジを向上させるためにさまざまなドキュメントを生成することです。
技術的には、LangChainのclass HypotheticalDocumentEmbedderの既存の実装を取り、AutoHyDEを実現するための新しい機能を作成しました。これにより、お持ちのRAGチェーンの一部としてすぐに機能するようになります。これは私が書いたembed\_query関数の更新版であり、以下の解説で各サブメソッドを探求します。

興味がある場合は、実装をこちらでチェックしてみてください:https://github.com/ianhojy/auto-hyde/tree/main
以下は、使用方法のクイックデモです:
# DEFINE BASE LLM AND EMBEDDINGS
from langchain_openai import OpenAIEmbeddings
base_embeddings = OpenAIEmbeddings()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4-1106-preview", temperature=1)
# SET UP VECTOR DB
from langchain_community.document_loaders import TextLoader
loader = TextLoader("data/util.txt")
documents = loader.load()
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator='.', chunk_size=1200, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
from langchain_community.vectorstores import Chroma
db = Chroma.from_documents(docs,
base_embeddings,
collection_metadata={'hnsw:space': 'cosine'})
# INSTANTIATE AND USE AUTO_HYDE
from src.auto_hyde import HypotheticalDocumentEmbedder
hyde_embedder = HypotheticalDocumentEmbedder(
llm_chain=llm, base_embeddings=base_embeddings
)
hypo_params = {
'baseline_k': 20,
'exploration_multiplier': 5,
'verbose': True
}
query = 'what is the relationship between justice and happiness?'
hyde_embedding = hyde_embedder.embed_query(text=query, db=db, hypo_params=hypo_params)AutoHyDEのデモコード
AutoHyDEの動作を説明するために、J.S.ミルの功利主義を使用します。それをチャンク化し、インデックス化し、クエリに基づいて関連するチャンクを受け取ろうとします。
私はこれを選んだのは、卒業生時代の哲学101の良き日々に苦労したからだけでなく、ミルの知識が豊富な道徳哲学の博士号を持っていても、仮想的な文書を生成するためのカスタムプロンプトを書くのが本当に難しいテキストの良い例だからです。ミルの文章は非常に直感的で一貫性がありません。ランオンセンテンスには本当に長けています(私もそうです)。
以下でAutoHyDEの実装を説明する際に、高レベルの説明と、リポジトリに興味を持つ人のためのより技術的な説明を両方行います。
ステップ1:クエリからキーワードを抽出する
あなたがこのエッセイ課題を受け取ったと想像してください:
正義と幸福の関係は何ですか?
このステップ1では、LLMはキーワードを抽出するよう促されます。この場合は次のようになります:
>>> Extracting Keywords from your Query…
>>> …Keywords Extracted: ['relationship', 'justice', 'happiness']重要なのは、これらのキーワードがStep 3で利用されるため、通常の検索では見落としてしまう文書を迅速に特定するためです。
技術的な実装
これは私がキーワードを抽出するために書いた関数です。
@retry(tries=5)
def extract_keywords(
self,
text: str,
hypo_params: dict
) -> List[str]:
if hypo_params['verbose']:
print(f"n>>> Extracting Keywords from your Query...")
KEYWORD_EXTRACTION_PROMPT = """
Your goal is to extract a list of keywords from an input phrase, sentence, or several sentences.
- You can only generate 1 to 5 keywords.
- Keywords should be nouns, issues, concepts
- Keywords should not include verbs, prepositions, pronouns
- Each keyword can only be one word long.
- If the input is just a single word, return that word as the only keyword.
{format_instructions}
The input is:
{input}
"""
class KeywordListSchema(BaseModel):
keywordList: list[str] = Field(description="list of one-word keywords based on a given phrase")
parser = JsonOutputParser(pydantic_object=KeywordListSchema)
prompt = ChatPromptTemplate.from_template(
template=KEYWORD_EXTRACTION_PROMPT,
intput_variables = ["input"],
partial_variables = {
'format_instructions': parser.get_format_instructions()
}
)
keyword_extraction_chain = (
{'input': RunnablePassthrough()}
| prompt
| self.llm_chain
| parser
)
keywords = keyword_extraction_chain.invoke(text)['keywordList']
if hypo_params['verbose']:
print(f">>> ...Keywords Extracted: {keywords}n")
return keywords特に特別なことはありません。JsonOutputParserを使用して、キーワードのリストを正確に取得することを確認しています。
ステップ2:初期検索を行う
キーワードを抽出するだけでなく、元のクエリを使用して初期検索も行います。ワークフローの一環としていくつのチャンクを取得したいかを自問してください。
RAGで質問に答えるためのコンテキストとして20のドキュメントを取得することを最初に意図していたと仮定すると、このステップ2では20を超えるドキュメントを取得して、20の制限によって無視された(より適切な言葉がないため)潜在的なドキュメントを探索できます。これはexploration\_multiplierを使用して切り替えることができます。*baseline\_k*が20でexploration\_multiplierが5の場合、コサイン類似度に基づいて20 x 5 = 100のトップドキュメントを探索します。
技術的な実装
def do_init_retrieval(
self,
db: VectorStore,
text: str,
hypo_params: dict
) -> List[Tuple[Document, float]]:
k = hypo_params['baseline_k'] * hypo_params['exploration_multiplier']
if hypo_params['verbose']:
print(f"n>>> Performing Initial Retrieval of {k} documents...n")
docs = db.similarity_search_with_score(
text,
k=k
)
return docsステップ3:キーワードを含む無視された文書を取得する
単純な検索で取得した20の文書に加えて、80の文書が考慮の対象となります。これらはあなたが無視していた文書です。
この80の文書の中から、元のクエリに直接関連する文書のサブセットを見つけたいと思います。これを効率的に行うにはどうすればよいでしょうか?単純な方法としては、ステップ1で抽出したキーワードを含む文書を選択するだけです。これをより良くする方法もありますが、キーワードの一致はすでに無視された文書の最初の選別を行うには迅速で効果的な方法だと思います。この識別方法を改善する方法を検討するかもしれませんが、今のところはこれで十分です。
これがコードからの出力です:
>>> Checking 80 Docs ranked after 20 for presence of keyword…
>>> …69 neglected Docs identified上記の出力では、80の文書のうち69が['relationship', 'justice', 'happiness']のいずれか1つ以上を含んでいることがわかります。
直感的には、これらは通常の上位20の文書の検索では見落とされていたかもしれない潜在的に関連性のある文書として理解できます。
技術的な実装
def get_remaining_docs_with_keywords(
self,
text: str,
init_docs: List[Tuple[Document, float]],
keywords: List[str],
hypo_params: dict
) -> List[Document]:
remaining_docs_with_keywords = list()
if hypo_params['verbose']:
print(f"""n>>> Checking {len(init_docs[hypo_params['baseline_k']:])}
Docs ranked after {hypo_params['baseline_k']} for presence of keyword...""")
for r in init_docs[hypo_params['baseline_k']:]:
page_content = r[0].page_content.lower()
for keyword in keywords:
if keyword.lower() in page_content:
remaining_docs_with_keywords.append(r)
continue
if hypo_params['verbose']:
print(f">>> ...{len(remaining_docs_with_keywords)} neglected Docs identifiedn")
return remaining_docs_with_keywords各文書について、もしキーワードが見つかれば、それを無視された文書のリスト(remaining\_docs\_with\_keywords)に追加します。
ステップ4:無視された文書をクラスタリングする
これは重要なステップです。私たちは69の無視された文書それぞれについてLLMに参照を求め、元のユーザークエリに基づいてそれぞれのための仮想文書を作成することに誘惑されるかもしれません。
しかし、これは計算コストがかかり、これらの文書全体に存在する主要な関連パターンを発見する最も効率的な方法ではありません。
代わりに、埋め込みを使用して69の文書をクラスタリングします。これにより、データセット全体に存在する主要な関連パターンを発見することができます。以下の出力では、69の文書がその後、6つの異なるグループにクラスタリングされたことがわかります。
>>> Clustering neglected Docs...
>>> ...6 Clusters identifiedTechnical Implementation技術的実装
クラスターの数をどのように選択するのか?ここでは、HDBSCANを使用します。これは、DBSCANの半教師あり階層クラスタリングバージョンであるHDBSCANがドキュメントでどのように説明されているかです:
このアルゴリズムは、DBSCANとほぼ同じように開始します:密度に従って空間を変換し、DBSCANとまったく同じように変換された空間で単一連結クラスタリングを実行します。ただし、デンドログラムの切断レベルとしてイプシロン値を取る代わりに、異なるアプローチが取られます:デンドログラムは、少数のポイントがクラスタから離れるポイントとして分割される結果を見て縮約されます。これにより、ポイントを失うクラスタが少ないより小さなツリーが得られます。そのツリーは、最も安定したまたは持続的なクラスタを選択するために使用できます。
直感的には、min\_samplesはコアポイントの最小近傍数を制御するパラメータです。min\_samplesが大きいほど、クラスタリングからノイズとしてラベル付けされるポイントが増えます。今のところ、1としておき、後で実験を行いますが、一般的には、"HDBSCANはそれに対してあまり敏感ではなく、いくつかの適切なデフォルトを選択できますが、これはアルゴリズムの最大の弱点のままです。" min\_cluster\_sizeは、クラスタから離れるポイントを識別したり、2つの新しいクラスタを形成するために分割するために使用されます。
ドキュメントにラベルを付けた後、クラスターがない(-1とラベル付けされた)ものを削除し、次に、ラベル付けされたグループ番号をキーとし、各ドキュメントのページ内容を値とする辞書を作成します。
def cluster_docs(
self,
remaining_docs_with_keywords: List[Document],
hypo_params: dict
) -> Dict[int, List[str]]:
from hdbscan import HDBSCAN
if hypo_params['verbose']:
print(f"n>>> Clustering neglected Docs...")
embeddings = self.embed_documents([
r[0].page_content
for r in remaining_docs_with_keywords],
{'verbose': False})
hdb = HDBSCAN(min_samples=1, min_cluster_size=3).fit(embeddings)
remaining_docs_with_cat = filter(lambda x: x[1] != -1, zip([r[0].page_content for r in remaining_docs_with_keywords], hdb.labels_))
cat_dict = {}
for page_content, cat in remaining_docs_with_cat:
if cat not in cat_dict:
cat_dict[cat] = [page_content]
else:
cat_dict[cat].append(page_content)
if hypo_params['verbose']:
print(f">>> ...{len(cat_dict)} Clusters identifiedn")
return cat_dictステップ5:仮説文書の生成
今、関連パターンのグループを表す6つのクラスタごとに、当社のLLMに、クラスタに属する文書を参照して、それらの文書に類似した新しい仮説文書を作成するように求めます。これは、AutoHyDEアプローチを既存のHyDEアプローチとは異なる重要なステップです。AutoHyDEでは、関連パターンが自動的に学習され、それらを使用して仮説文書が生成されます。カスタムプロンプトの作成は一切必要ありません。
以下のコードの最初のクラスタの例を示します。LLMは最初の無視された文書クラスタ内のすべての無視されたものを参照し、元のクエリに基づいて仮説文書を作成しました。これはすべてのクラスタに対して行われます。以下のテキストを見ると、それが実際にミルの複雑なスタイルをかなりよく模倣していることがわかります。このスタイルを捉えようとしてカスタムプロンプトを書く必要はありませんでした。すべての必要が、フューショットプロンプティングでした。

以下は、著者による画像:AutoHyDEから生成された仮想的なドキュメントの仮説的な実装に関するテキストです。
技術的な実装
以下の関数が行うことは、特定のドキュメントのクラスタごとに仮説的なドキュメントを生成することです。以前と同様に、JsonOutputParserを使用して、希望する出力を得るようにしています。以下のHYPOTHETICAL_DOCUMENT_PROMPTで見られるように、フューショットアプローチが一般的にうまく機能することがわかりました。
@retry(tries=5)
def generate_hypo_docs(
self,
text: str,
cat_dict: Dict[int, List[str]],
hypo_params: dict
) -> List[str]:
hypo_docs = list()
if hypo_params['verbose']:
print(f"n>>> Generating Hypothetical Documents for each Doc Cluster...n")
HYPOTHETICAL_DOCUMENT_PROMPT = """
Your instruction is to generate a single hypothetical document from an input.
- This hypothetical document must be similar in style, tone and voice as examples you are provided with.
- This hypothetical document must appear like it was written by the same author as the examples you are provided with.
- This hypothetical document must also be similar in length with the examples you are provided with.
{format_instructions}
### EXAMPLES ###
Below are some examples of hypothetical documents, all written by the same author, in pairs of <Input> and <Hypothetical Document>:
{ref_documents}
### INSTRUCTION ###
Now generate a new hypothetical document.
<Input>
{input}
<Hypothetical Document>
"""
class HypotheticalDocumentSchema(BaseModel):
hypotheticalDocument: str = Field(description="a hypothetical document given an input word, phrase or question")
parser = JsonOutputParser(pydantic_object=HypotheticalDocumentSchema)
prompt = ChatPromptTemplate.from_template(
template=HYPOTHETICAL_DOCUMENT_PROMPT,
intput_variables = ["input", "ref_documents"],
partial_variables = {
'format_instructions': parser.get_format_instructions()
}
)
hypothetical_document_chain = (
{'input': RunnablePassthrough(), 'ref_documents': RunnablePassthrough()}
| prompt
| self.llm_chain
| parser
)
cat_ii = 1
for cat in cat_dict.keys():
ref_doc_string = ""
doc_ii = 1
for doc in cat_dict[cat]:
ref_doc_string += f"nn<Input>"
ref_doc_string += text
ref_doc_string += f"nn<Hypothetical Document>n"
ref_doc_string += f'{{"hypotheticalDocument": "{doc}"}}'
doc_ii += 1
hypo_doc = hypothetical_document_chain.invoke(
{'input': text, 'ref_documents': ref_doc_string}
)['hypotheticalDocument']
if hypo_params['verbose']:
print(f"n### Hypo Doc {cat_ii} ###")
print(hypo_doc+'n')
hypo_docs.append(hypo_doc)
cat_ii += 1
return hypo_docsステップ6+7: 埋め込みと結合
最後に、仮想的なドキュメントのリストを持ち、各クラスターごとに1つずつ、仮想的なドキュメントを埋め込み(ステップ6)し、それらを単一の埋め込みベクトルに結合します(ステップ7)。
このステップは、仮想的なドキュメントを埋め込み、その後平均を取って最終ベクトルを得るという、元の実装に似ています。
⚠️前述のように、このステップは、特に異なる関連性パターンを持つドキュメントを発見し、生成しようとしているときに、ドキュメントのより広範な異質性を捉える意味が本当にあるとは思いません。ただし、LangChainの既存の実装との互換性を維持し、(LangChain RAGの他のコンポーネントと直ちに使用できるという点が重要です)、単一の埋め込みベクトルを出力するために、今のところこれを保持します。そして、後で集約の制限に対処するかもしれません。シンプルな平均化が良い考えではないと納得した場合は、常にステップ6で停止することができます。
>>> Generating embeddings for hypothetical documents...
>>> Combining embeddings for hypothetical documents...hyde_embedding[:10]
>>> [
0.015876703333653572,
-0.013635452586265312,
0.021941788843565697,
-0.02570370381768275,
-0.015861831315729033,
-0.0003427757204382006,
0.0027591148428962454,
-0.00883308151544041,
-0.014893267477206646,
-0.020748802766928837
]技術的な実装
def embed_documents(self, texts: List[str], hypo_params) -> List[List[float]]:
"""Call the base embeddings."""
if hypo_params['verbose']:
print("n>>> Generating embeddings for hypothetical documents...n")
return self.base_embeddings.embed_documents(texts)
def combine_embeddings(self, embeddings: List[List[float]], hypo_params) -> List[float]:
"""Combine embeddings into final embeddings."""
if hypo_params['verbose']:
print("n>>> Combining embeddings for hypothetical documents...n")
return list(np.array(embeddings).mean(axis=0))以前と同様に、私がこのHyDEの強化バージョンを実装したリポジトリは、こちらのリポジトリで見つけることができます。
セクション4: 結論
これでAutoHyDEのデモは終わりです!
まとめると、AutoHydeで行われている主な改善点は、仮想的な文書の生成方法です。これまでのように(LangChainで事前に定義されたものであろうと、ユーザーによってカスタマイズされたものであろうと)固定のプロンプトを使用してこれらの文書を生成する代わりに、私は自動的にそれらの文書全体で見逃される可能性のある基盤となる関連性のパターンを発見し、それぞれのパターンに対して仮想的な文書を生成するためのフレームワークを考案しました。
この方法により、HyDEをさまざまなタスクやコンテキストに適応させることができるだけでなく、関連性のパターンが異なるインデックス上での検索にも対応することができます。
この記事が気に入ったらサポートをしてみませんか?