
複合AIシステムのデザインパターン(対話型AI、CoPilot、RAG)

Design Patterns for Compound AI Systems (Conversational AI, CoPilots & RAG)
https://medium.com/@raunak-jain/design-patterns-for-compound-ai-systems-copilot-rag-fa911c7a62e0
オープンソースツールを使用して設定可能なフローと複合AIシステムを構築する方法。
複合AIシステムの理解
最近の記事である モデルから複合AIシステムへのシフト において、バークレーの研究者たちはAIが単一のモデルの使用から複数のコンポーネントの複雑なシステムへと移行していることについて話しました。基本モデルが同じ(例えばGPT4)であっても、その使用方法により、それがより大きなシステムの異なる部分のように見せる事ができます。
以下は、これらのシステムが一般的にどのように使用されているかのいくつかの方法です:
RAG(理解が鍵) - これらのシステムは、思考生成、推論、コンテキストを使用してユーザーの質問を理解し、それに対応します。これらはエージェントアシスト設定に最適です。ダイアログモデルのようなユーザー向けモデルと一緒に使用すると、RAGシステムは会話型AIまたはCoPilotシステムの一部になることができます。
マルチエージェント問題解決者(チームワークが鍵) - これらのシステムは、異なるエージェントが協力して働く結果に基づいたソリューションを構築します。各エージェントは独自のツールを持ち、推論と行動計画において特定の役割を果たします。
会話型AI(チャットが鍵) - これらは、カスタマーサービスエージェントのように、人間とやり取りし、人間の入力に基づいて繰り返し行うタスクを自動化します。ここでの主な特徴は、過去の会話を記憶し、新しい会話を生成する能力で、あなたが人間と話しているかのように感じさせます。会話型AIは、基礎となるRAGシステムやマルチエージェント問題解決者を使用することができます。
CoPilots(人間の関与が鍵) - これらのシステムは、ツール、データ、推論、計画を使用して人間と対話しながら問題を解決できます。システムがCoPilotである主な特徴は、人間の作業環境を理解していることです。例としては、MetaGPT Researcher: Webを検索しレポートを作成、A measured take on Devin、Let’s build something with CrewAI、Autogen Studioがあります。
***注:*LLMを使用して多くのシステムを設定した後、それらが皆が望む完璧な解決策ではないことがわかりました。すべてのAIと同様に、LLMでさえ単純なタスクを実行するためには多くの作業が必要で、パフォーマンス保証があっても、信頼性や安定性が保証されるわけではありません。
***潜在的な利点:*LLMの最良の使用法は、製品やサービスがどこで改善できるかを理解し、その情報を使って時間とともに改善することで、機械学習を支援することです。これは人間のレビュアーの作業を減らすことを意味するかもしれません。LLMをテストし評価できる閉じたシステムでは、それらは多くのことを達成できますが、それは高価です。しかし、それはまた、より良いLLMを作るためのデータを生成します。この改善のサイクルこそが、LLMが本当に輝く場所です。
これらのシステムのコンポーネントとそれらがどのように相互作用して複雑なシステムを構築するか
複合AIシステムは通常、互いに依存して特定のタスクを行い、デザインパターンを実行するために連鎖する「モジュール」を使用してデプロイされます。
ここで、モジュールは、システム内の個々のコンポーネントを指し、それは検索エンジン、LLMなどの基礎となるシステムの助けを借りても借りなくても、よく定義されたタスクを行います。一般的なモジュールには、ジェネレーター、リトリーバー、ランカー、クラス分類器などがあり、これらは伝統的にNLPのタスクと呼ばれています。これらは、ドメイン固有の概念的な抽象化であり(例えば、NLPのモジュールはコンピュータビジョンや推奨システムとは異なる抽象化モジュールを持つかもしれませんが、それらはすべて同じ基本モデルの提供や検索プロバイダーに依存するかもしれません)。

Key components of a module

追加の標準モジュール
AIの領域では、ツール、エージェント、コンポーネントなどの用語によく出会います。これらはすべて実質的にモジュールです。
LLMベースの自律エージェント - 複合AIシステムの重要なモジュール
モジュールの一種に、LLMによって可能となる、独立した推論と計画を立てる能力を持つ自律エージェントがあります。自律エージェントは、環境との相互作用時に推論アプローチと行動計画を決定するための一連のサブモジュールに依存する可能性があります。
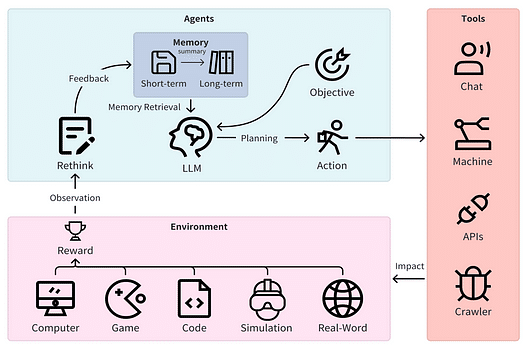
Key capabilities or skills of a Autonomous Agent module:

推論能力は思考の連鎖を引き起こし、実際の行動に結びつきます。
推論 — 観察を行い、仮説を生成し、データに基づいて検証するなど、問題を解決するための論理的な方法。
思考 — 推論の適用と因果関係の一貫した生成。
思考の連鎖 — 解決策を論理的につながった推論の連鎖に分解する一連の思考。
計画 — サブゴールの形成を行い、現状から未来の状態への道筋を作るための決定力。これは通常、行動を起こし、学習するための基本的な環境にアクセスすることで利益を得る。LLM計画についてはここで詳しく読むことができます。
ツール — エージェントがエージェントからの指示に基づいて外部世界と対話することを可能にするサブモジュール。
アクション — 名前が示す通り、これはエージェントが計画を通じて目標を追求するための決定的なステップです。ツールがアクションをトリガーするために呼び出されることがあります。アクションは環境で行われます。
環境 — エージェントのアクションと報酬が発生する外部世界、例えばカスタムアプリ(Microsoft Word、コーディング環境など)やゲーム、シミュレーションなど。
「確率的なオウム」との作業
注:大規模言語モデル(LLM)の推論と計画における限界についての広範な理論的研究にもかかわらず、こことここで示されているように、LLMが解決方法を"オウム返し"できることは明らかです。問題と過去の解決例が提供されれば、LLMは論理的な思考過程を効果的に複製できます。それが一般化するかどうかは、ここでは焦点ではありません。ヤン・ル・クンが言うように、自己回帰モデルは失敗する運命にある!
ビジネス環境では、信頼性の高いタスクの繰り返しと過去の経験からの学習を、過剰な創造性なしで目指すのが目標です。
これらの”思考過程の複製”は実際にどのように計画を立てるのでしょうか?
この調査に基づくと、LLMは以下のようにして自律的なエージェントを強化できるようです:
タスクの分解 - 実生活でのタスクは通常複雑で多段階的であり、計画を立てるのが非常に難しくなります。このような方法は分割統治の考え方を採用し、複雑なタスクをいくつかのサブタスクに分解し、それぞれのサブタスクについて順序立てて計画を立てます。例えば、TDAG
複数の計画選択 - このような方法は、LLMに「もっと考える」ことに焦点を当て、タスクに対するさまざまな代替計画を生成します。その後、タスク関連の検索アルゴリズムが用いられて、実行する計画を一つ選びます。例えば、ReWoo
外部モジュールを利用した計画 - また、計画の取り出しとも言えます。
反省と改善 - この方法論は、反省と改善を通じて計画能力を向上させることを強調します。LLMに失敗について反省し、計画を改善することを奨励します。例えば、自己批評と改善ループ。
メモリ強化型計画 - このようなアプローチは、付加的なメモリモジュールを用いて計画を強化します。このモジュールには、一般的な知識、過去の経験、ドメイン固有の知識など、価値のある情報が保存されます。この情報は計画を立てる際に取り出され、補助信号として機能します。

これらの特徴の訓練方法、特にRAGのために知流ためには、企業向けRAGのためのLLM Fine-tuningの簡素化をチェックしてみてください。
これらのモジュールを理解したところで、会話型AI、RAG、およびCoPilotシステムの複雑な問題を解決するためにどのように異なる設計を作ることができるかを見てみましょう。
複合AIシステムデザインパターン
役立つ定義
現在のAIの話題性を考えると、特定の用語が誤解されたり、誤用されたりすることも多いので、まずは正確な定義を設定しましょう:
"Agentic"パターンとは何ですか? 自律エージェントの主な利点は、自身の行動コースを決定する能力です。もし私たちが手動でフローや決定を定義しているなら、それは単にスマートなワークフローです。しかし、フローが事前に定義されていない場合や、決定過程が上記の能力とツール、行動を利用している場合、私たちは"Agentic"パターンを扱っています。例えば、Agentic RAGは、モジュールが検索ツールにアクセスを許可され、事前に定義されたステップなしで複雑な検索フローを自動的に生成できるパターンです。
"ワークフロー"とは何ですか? 簡単に言うと、ワークフローとは、問題を一貫性のある、繰り返し可能な方法で解決するための事前エンコード、手動で宣言された計画です。
"マルチエージェント"とは何ですか? これは、各々が自身の役割と責任を持つ異なるモジュールが、お互いの出力を共同で処理し、問題を協力して解決するシステムを指します。
エージェントを作成する際には、以下に注目してください:
エージェントのプロファイリング — エージェントの役割に密接に関連したプロンプトに基づいて、エージェントの行動を定義します。
エージェントのコミュニケーション — これらの部分がお互いにどのように交流するかを特定し、下の画像で示されているように描き出します。
エージェント環境のインターフェース — 環境からのフィードバックを収集して、エージェントが学習、適応、そしてより具体的な反応を作り出すのを助けます。
エージェントの学習と開発 — エージェントは、環境との交流(特にコーディングアシスタントの場合)、他のエージェント、自己評価、人間からのフィードバック、ツールから学びます。各設計がリアルタイムで問題解決にどのように取り組むかを見ていきましょう。
パターンを選ぶ前に考えるべきこと
RAG、会話型AI、CoPilots、複雑な問題解決者などのデザインパターンを作成する際には、以下のことを考慮する必要があります:
モジュール間の相互作用の方法は固定されているのか、それともそれらは独立して動作することができるのか? エンジニアリングフロー対エージェントシステム。
情報は一方向に流れるのか、それともメッセージを渡すようなものなのか? 彼らは協力して働くのか、それとも反対に働くのか? エージェントモジュロ.*
システムは自己学習できるのか? 自己修正が重要なのか?
推論と行動をループさせることができるのか?
モジュールは互いに学習することができるのか?
各モジュールの結果は実世界でテストすることができるのか?
システムの動作方法はユーザーの入力に基づいて変化するのか?
パターン1 - RAG / 会話型RAG
以下の図は、RAG / 会話型RAGシステムのモジュールの主なタスクを示しています。これは情報検索(IR)分野から始まり、ニューラルサーチと知識グラフによって改善され、言語モデルを用いたループベースの形に進化しました。IRと対話システムが結合し、会話中にクエリが変わると、これを会話型IRと呼びます。
RAGシステムを機能させるためには、ユーザーが何を尋ねているかを理解し、関連する知識(組織化されているかどうか)を見つけて、それをGenerator / Dialogue Managerに適切な指示で提供することが重要です。これは、よく計画されたワークフローを使用するか、次に何をすべきかを選択するAgentモジュールを使用して実行できます(次の部分で詳しく説明します)。

RAGシステムはダイアログマネージャーとペアにすることができます。ダイアログマネージャーがエージェントである場合、RAGはツールとして使用できます。
以下は、エージェントが複雑なRAGシステムを操作するのを助ける中間モジュール/ツールの一部です。
クエリの理解と変更
クエリの拡張 / 複数のクエリ
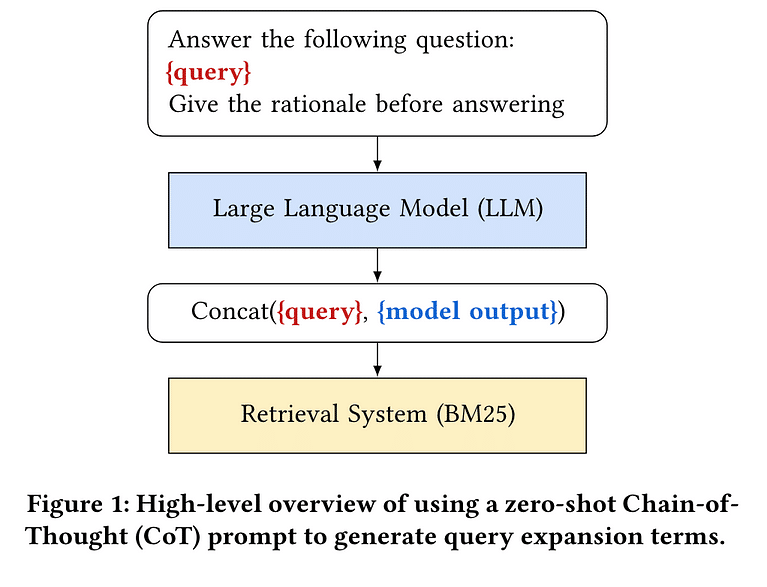

LLMを使用して検索クエリをより詳細にすると、特定のタイプのリトリーバーを使用した場合の検索結果が向上します。
自己問い合わせリトリーバー
自己問い合わせリトリーバーは自己に質問をすることができます。自然言語での任意のクエリを取り、LLMチェーンを使用して構造化クエリを作成し、これを自身のVectorStoreに適用します。このようにして、初期のユーザークエリを保存されたドキュメントと比較し、ユーザークエリからの任意のフィルターをドキュメントのメタデータに適用することができます。
エンティティの識別
クエリの強化
情報の検索または意図の理解
複数のドキュメントの検索
会話の管理
レスポンスの作成
エージェント型RAG
エージェント型RAGは、LLMによって駆動されるモジュールが、使用可能なツールのセットに基づいて、質問にどのように答えるかを推理し計画するデザインパターンです。高度なシナリオでは、複数のエージェントを接続して、エージェントが情報を取得するだけでなく、確認、要約などを行うような創造的な方法でRAGを解決することもあります。これについては、マルチエージェントセクションを参照してください。
改善が必要な主要な手順とコンポーネントは次の通りです:
推理、サブタスクの形成、および体系的な配置に基づいた計画。
複数のパスの生成と推理、計画に基づくRAGアプローチ(ReWooとPlan+)による自己整合性に基づく自己修正は、単なる推理に基づくもの(ReAct)よりも優れています。
実行に基づいて適応する能力、より多エージェント型のパラダイム。
通常、これらは以下のパターンを使用して実行されます:
推理に基づいたエージェント型RAG
ReAct:https://blog.langchain.dev/planning-agents/
ReAct:言語モデルにおける推論と行動のシナジー
While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and…

検索ツールを使用して理由(Reason)と行動(Act) ⇒ ReAct
計画に基づくAgentic RAG
https://blog.langchain.dev/planning-agents/
ReWOO:効率的な拡張言語モデルのための観察からの推論の分離
https://arxiv.org/abs/2305.18323
Augmented Language Models (ALMs) blend the reasoning capabilities of Large Language Models (LLMs) with tools that allow…


ReWoo - ReActよりもはるかに少ないトークン生成につながります。
ReActがReWooよりもずっと劣っている理由についての詳細は、こちらをご覧ください。
PlanRAG
それは二つのコンポーネントで構成されています:まず、全体のタスクをより小さなサブタスクに分割する計画を立て、次にその計画に従ってサブタスクを実行する。
https://openreview.net/forum?id=4sajV6NEnWE
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
デプロイメントパターン2 - 会話型AI
過去、チャットボットの会話は単純なパターンに従っていました:ボットが話し、ユーザーが反応し、その後ボットが返答します。このパターンは、Rasa開発者の「ストーリー」としても知られており、異なる現実世界の状況を表しています。各ユーザーの意図は、ユーザーの状態と相互作用に基づいて数百の「ストーリー」で示すことができます。その後、ボットはアクションを起こしてストーリーに従い、準備された反応で答えます。例えば、ユーザーがニュースレターにサインアップしたい場合、次の2つのシナリオが考えられます:
ユーザーはすでにサインアップしています。
ユーザーはまだサインアップしていません。

ユーザーが「ニュースレターを購読するにはどうすればいいですか」と尋ねた場合、ボットはユーザーがすでに購読しているかどうかを調べてから進める必要があります。このプロセスは現在ハードコーディングされています。ボットが理解できない場合、「すみません、まだ学習中で、xyzに関してはお手伝いできます」と言います。
ボットの作成と維持における課題は、これらのプロセスを管理することです。私たちはこれを行うことで、ボットがさまざまな実世界の状況に対応できるようにしています。しかし、これらのパスを作成することは、条件を確認し、アクションを実行し、会話の目標に到達するという複雑なプロセスを伴うため、複雑になることがあります。
私たちは、このプロセスを自動化するために言語モデル(LLMs)を使用しています。LLMsを使用すると、「推論」と「計画」の能力を使ってパスを作成することができます。これについてはこちらで詳しく学ぶことができます。
例えば、あなたがカスタマーサービスのエージェントだとします。ユーザーがあなたのサービスの購読方法を尋ねます。次のステップをどのように決定しますか?それは完全に自由な形式であることはできませんが、コストの考慮からあまりにもスクリプト化されすぎることもできません。しかし、以下のようなガイドラインがあったらどうでしょうか:
条件 - メールが存在する場合、ユーザーは購読できますツール - check_subscription、add_subscription
この場合、次のようなプランを作成することができます:
ユーザーは購読を希望している、という声明に基づく - 「どうやって購読しますか?」
ユーザーにメールを聞く - 「あなたのメールアドレスは何ですか?」
彼が有効なメールを提供した場合、ツールをトリガー - check_subscription
ユーザーがまだ購読していない場合、トリガー add_subscription
成功または失敗を返答。
これがLLMが行いたいことです - 参照し、行動に移すことができる「プラン」を作成すること。このプロセスについてはこちらで詳しく学ぶことができます。
では、モジュールテンプレートでのプランナーがどのように見えるか見てみましょう。

上記のプランナーは、ツールや条件を使用して、設計時または実行時にプランやストーリーを作成することができます。これについての実例を研究で見てみましょう:
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
大規模な言語モデル(LLMs)は複雑な推論タスクにおいて大きな可能性を示していますが、それでも不足しているときには…

KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
プランナーが信頼性のある推論でパスを決定するためのツールは何がありますか?
同様の発言によって引き起こされた過去のパス。
行動の企業グラフ、および行動間の依存関係。これにより、プランナーはある行動が正しい結果につながるかどうかを決定し、次にそれが次の行動につながり、再帰的に問題を解決するまで進むことができます。その関連のある実世界の統合については、こちらこちらを参照してください。これは、Neo4JとLangchainを使用した知識グラフと計画の統合であり、必ずしも計画パスに関連しているわけではありません。
ユーザー/会話の現在の状態。
デプロイメントパターン3 - 複数のエージェント
多数のエージェントが存在する設定では、LLM(Large Language Models)ベースのジェネレーターに役割とタスクを割り当てることが目指されています。これらのジェネレーターは、特定のツールを装備しており、スマートな答えや解決策を提案するために協力して働きます。
明確に割り当てられた役割とサポートモデルのおかげで、各エージェントは "プラン" の一部または小さな目標を "エキスパート"に引き渡すことができます。彼らは次にこの出力を使用して次のステップを決定します。詳細については、最後にあるGPTPilotの例をご覧ください。
大規模言語モデルに基づくインテリジェントエージェントの探求:定義、方法、展望
Intelligent agents could be a step towards artificial general intelligence (AGI). Therefore, researchers have…
このようなパターンは、実行チェーンの次のステップを定義する権限を制御する以下の通信パターンを使用して実行されます。これについての詳細は Orchestrating Agentic Systemsとしての詳しい情報はこちらをご覧ください。

エージェント/モジュールがどのようにコミュニケーションを取り、現実世界のCoPilotsを構築するかhttps://arxiv.org/pdf/2402.01680v1.pdf
関心の分離:各エージェントは、それぞれの指示とフューショットの例を持つことができ、別々の微調整された言語モデルによって支えられ、さまざまなツールによって支援されます。タスクをエージェント間で分割すると、結果が向上します。各エージェントは、多数のツールから選択するのではなく、特定のタスクに集中できます。
モジュラリティ:マルチエージェントデザインでは、複雑な問題を管理可能な作業単位に分割し、それを専門のエージェントと言語モデルで対象とすることができます。マルチエージェントデザインでは、全体のアプリケーションを混乱させることなく、各エージェントを独立して評価し、改善することができます。ツールと責任をグループ化すると、より良い結果が得られます。エージェントは、特定のタスクに集中しているときに成功する可能性が高くなります。
多様性:エージェントチームに強い多様性を持ち込むことで、異なる視点を取り入れ、出力を洗練させ、ホールシネーションとバイアスを避けます。(典型的な人間のチームのように)。
再利用性:エージェントが構築されたら、これらのエージェントを異なるユースケースで再利用する機会があり、エージェントのエコシステムを考え、適切なコレオグラフィー/オーケストレーションフレームワーク(AutoGen、Crew.aiなど)を用いて問題を解決することができます。
デプロイメントパターン4 - CoPilot
CoPilotシステムで私が見る唯一の違いは、ユーザーとテスト機能とのインタラクションによって得られる学習です。
続きは後ほど...
フレームワークと実装
これらのCoPilotsを構築するフレームワークと、実際のCoPilotsの実装(GPT Pilotやaiderなど)を区別することは重要です。ほとんどのシナリオでは、オープンソースのCoPilotsはフレームワーク上に開発されておらず、すべての実装はゼロから開発されています。
レビューする人気のある実装:OpenDevin、GPT Pilot
レビューする人気のある研究論文:AutoDev、AgentCoder
人気のあるフレームワーク - Fabric、LangGraph、DSPy、Crew AI、AutoGen、Meta GPT、Super AGIなど。
可能な限り、LLMベースのマルチエージェントについて以下の定義に従おうと試みます。
Deep Dive — アプリ
GPT Pilot
GPT Pilot プロジェクトは、創造的なプロンプトエンジニアリングとLLMのレスポンスを「レイヤー化」した流れで連鎖させることで、複雑に見えるタスクを実行する優れた例です。
レイヤー化されたコミュニケーション方式で働くいくつかのプロファイルがあります。下の緑のボックスをご覧ください:

個々のエージェントは、階層的な方法で相互作用し、エージェントは一つのノードから次のノードにトリガーされ、決定を下すエージェントは存在しません。

この製品は、効果的に動作するためのいくつかの素晴らしい戦略を使用しています:
LLMがコードを作成できるように、タスクを小さく、管理しやすい部分に分割します。
テスト駆動開発を使用し、ユーザーから有用な例を収集して正確で効果的な更新を保証します。
コンテキストの巻き戻しとコードの要約を使用します。
設計プロセスは複雑であることがありますが、各エージェントを調整してコストを抑え、すべてが正確に動作するようにすることが非常に重要です。
この記事が気に入ったらサポートをしてみませんか?