Linux でフラットファイルデータを扱う

この記事を読んでいただきたい方
* フラットファイルとはどんなデータか知りたい方
* Linux でフラットファイルを操作するやり方の雰囲気を見てみたい方
* IPOC のデータの処理方法の基本「バケツリレー」の中身を知りたい方
* ALZETA の動作原理を知りたい方
1. はじめに
IPOC ではフラットファイル形式のデータを Linux などの UNIX 系システム上で処理しています.ここでは,フラットファイル形式のデータに対してどういう処理が行えるか見てみます.
2. フラットファイルとは
フラットファイルとは,文字情報だけでできた表形式のデータです.一行が一件の「レコード」で,レコードは,区切り文字で分割された複数のフィールドから成ります.もっとも身近なところでは CSV は,区切り文字をカンマ (',') とするフラットファイルです.Excel ファイル(拡張子が ".xls" や ".xlsx" であるもの)と異なるのは,「セルの色」や「フォントの種類,大きさ」という装飾を付けられないところです.最初に述べた「文字情報だけでできた」というのは,そのことを指します.
データの装飾は,データの処理が完了してから最後に Excel や Tableau など,データの可視化に長けたツールを用いて行います.
3. フラットファイルのデータ操作
では,フラットファイルのデータに対してどういう操作が行えるのでしょうか?例をいくつか挙げてみましょう.
3-1. 表示(出力)
cat というツールで,フラットファイルの内容を表示できます.以下は「販売」というフラットファイルの内容を表示した例です.
ツールの使い方(最初の '$' 文字以降を入力します)
$ cat 販売
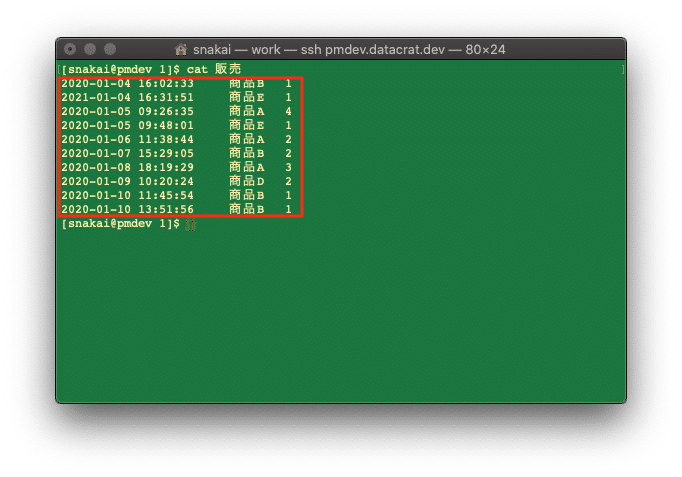
※この「販売」というフラットファイルは,タブ文字を区切り文字としています.
第1フィールドは時刻 (1レコード目ですと,"2020-01-04 16:02:33")
第2フィールドは商品コード(1レコード目ですと,"商品B")
第3フィールドは販売個数(1レコード目ですと,"1")
です.
3-2. ソート
Linux には sort というツールがあります.以下は,商品コード(第2フィールド)でフラットファイルをソートした例です.
ツールの使い方(最初の '$' 文字以降を入力します)
$ sort -t $'\t' -k 2 販売

"商品A" → "商品E" の順にレコードが並び替えられていることがわかります.
3-3. 集計
awk というツールを使用して,集計ができます.以下は商品コード(第2フィールド)をグループに指定して,販売個数を集計した例です.
ツールの使い方(最初の '$' 文字以降を入力します)
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {qty[$2] += $3} END {for (i in qty) {print i, qty[i]}}' 販売

3-4. (横)結合
join というツールがあります.以下は二つのフラットファイル「販売」と「商品」を結合する例です.「販売」の商品コードを参照して,対応する商品情報を追加します.
「商品」の内容(商品コード,商品名,単価)

なお,join コマンドで結合を行うときは,結合するファイルを,結合のキーとするフィールドでソートしておく必要があります.「商品」は商品コード順にソートされていますので,「販売」をソートした別のフラットファイル「販売.sorted」を作成し,「販売.sorted」に「商品」を結合します.
ツールの使い方(最初の '$' 文字以降を入力します)
$ sort -t $'\t' -k 2 販売 > 販売.sorted
$ join -t $'\t' -1 2 -2 1 販売.sorted 商品
※ sort コマンドを使用する際に,
"> ファイル"
を指定することにより,データを表示する代わりにファイルに保存します.

3-5. (縦)結合
表示にも使用した cat ツールで,データの縦結合ができます.「販売」に異なる期間の販売データ「販売2」を結合します.
「販売2」の内容

ツールの使い方(最初の '$' 文字以降を入力します)
$ cat 販売 販売2

3-6. (横方向)演算
awk ツールが使用できます.先述の集計は,複数レコードの同一フィールドの集計を取るものでしたが,この演算は,同一レコードの複数フィールドの値を計算して,レコードに加えます.さきほどの「販売」「商品」を横結合したデータを一旦,「販売_詳細」というデータに保存します.「販売_詳細」には,販売数量(第3フィールド)と単価(第5フィールド)がありますので,それらを掛け算して売上データを作ります.
ツールの使い方(最初の '$' 文字以降を入力します)
$ join -t $'\t' -1 2 -2 1 販売.sorted 商品 > 販売_詳細
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {print $0, $3 * $5}' 販売_詳細

awk を使用して第3フィールドと第5フィールドを掛け算した売上データを,最終フィールドに追加しています.
3-7. 文字列操作
awk を使用して文字列操作ができます.下の例では,商品名の産地情報を先頭から末尾(カッコ付き)に変更して,全て "バナナ" の形式に統一しています.
ツールの使い方(最初の '$' 文字以降を入力します)
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {print $1, gensub("^([^()]+産)(.+)$", "\\2(\\1)", "g", $2), $3}' 商品

3-8. (レコード)抽出
awk を使用してレコードの抽出が行えます.下の例では,販売データから "商品A" の販売レコードだけ取り出しています.
ツールの使い方(最初の '$' 文字以降を入力します)
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {if ($2 == "商品A") print}' 販売

3-9. (フィールド)抽出
awk を使用してフィールドの抽出が行えます.下の例では,先の横方向演算で作成した「販売_詳細」から,商品コード,販売個数,単価のフィールドだけを抽出します.
ツールの使い方(最初の '$' 文字以降を入力します)
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {print $1, $3, $5}' 販売_詳細

4. データ操作の組み合わせ(バケツリレー)
これまで説明した基本操作を行うごとに,その結果を ">" を使って保存し,さらにその結果に別の基本操作を行う…というやり方で基本操作を組み合わせていくと,業務に必要なデータを得ることができます.「データをバケツリレーにかけていく」とでも言いかえると,より雰囲気を掴んでいただけるかと思います.
バケツリレーの例として,これまでの説明で使用した「販売」「販売2」「商品」のフラットファイルデータから,「商品名を含んだ商品別売上金額データ」を作ってみます.
バケツリレーのやり方(最初の '$' 文字以降を入力します)
※ # で始まる行は,続く行のツールの使用について説明するために記入しているものです(システムには無視されます)
$ # 「販売」と「販売2」のデータを結合して「step1」というデータを作る
$ cat 販売 販売2 > step1
$ # 「step1」を,商品コードでソートして「step2」というデータを作る
$ sort -t $'\t' -k 2 step1 > step2
$ # 「step2」に「商品」データを横結合して,単価情報を加えた「step3」というデータを作る
$ join -t $'\t' -1 2 -2 1 step2 商品 > step3
$ # 売上個数と単価を掛算して,売上金額を加えた「step4」というデータを作る
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {print $0, $3 * $5}' step3 > step4
$ # awk での集計の手法を用いて,売上金額を商品コードごとに集計した「step5」というデータを作る(最初の集計例と異なり,「step4」が商品コードでソートされている場合に使える集計手法を使っています)
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} NR==1 {prev = $1; sum = $6} NR>1 {if ($1 != prev) {print prev, sum; prev = $1; sum = $6} else {sum += $6}} END {print prev, sum}' step4 > step5
$ # 商品名を付与したいので,再度「商品」データを横結合して「step6」というデータを作る
$ join -t $'\t' -1 1 -2 1 step5 商品 > step6
$ # step6 には不要な「単価」情報が入っているので,それを取り除き「商品コード」「商品名」「売上集計金額」の順に並び替える
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {print $1, $3, $2}' step6 > step7
$ # 最後に,商品名の産地情報の表示を変更する
$ awk 'BEGIN {FS = "\t"; OFS = "\t"} {print $1, gensub("^([^()]+産)(.+)$", "\\2(\\1)", "g", $2), $3}' step7

8ステップのバケツリレーで,所望の形で集計データを作成することができました.
この例は,商品ごとの売上金額集計を得るという単純なものでしたが,同じようなやり方で,
* 月別売上集計
* 卸元毎売上集計(←商品ごとに卸元のデータがあれば)
* 商品カテゴリ別売上集計(←商品ごとにカテゴリのデータがあれば)
…
いろんな側面で集計したデータを作れる!という想像が膨らみますね.
ただし,ここまでご紹介したツールは,日常的に Linux をお使いの方でなければ,普段使いするには少々無理がありますね(たとえば,join ツールの "-1 2 -2 1" なんていうのがなかなか馴染み難かったりしますし,awk ツールで指定する内容はそれよりもめんどくさいものが多いですね).また,ご紹介したようなことは Excel でもできますので,わざわざ Linux で,フラットファイルを使ってやる意味があるのか?という疑問が出てくるはずです.
次回は,そのあたりについて書いていきたいと思います.
この記事が気に入ったらサポートをしてみませんか?