
ブルーアーカイブをアーカイブする

信じがたい事実です。ブルーアーカイブのストーリーをテキストとしてまとめたサイトがございません。これが何を意味するかといえば、ブルーアーカイブのストーリーや設定を確認するためにわざわざゲームを起動してあのテンポが悪い幕間劇を眺めて該当箇所を虱潰しに探さなければならないということでございます。
いちおうアーカイブを試みた者は何人かいたようですが、どれもこれも道半ばで力尽きております。そこで私がまとめようと思います。
やることはシンプルです。順序立てて考えてその後細分化していきましょう。
必要なもの
まず「何があればブルーアーカイブのストーリーをテキストとしてまとめられるのか?」を洗い出します。今回はOCR(光学式文字認識)を使った文字起こしを利用したいので、
ブルーアーカイブのストーリーモードのすべてのダイアログのスクリーンショット
があればひとまずよろしいことになります。OCRの方は後からどうとでもなりますので、まずはここを詰めていきます。
真っ先に思いつくのは以下のような手法でございます。
ゲーム画面を録画・もしくはYouTubeに上がってるストーリー動画をスクレイピングし、各動画をn秒ごとに画像化する(すべてのテキストを認識できる程度の間隔で)
当然被る画像がたくさん出てくるので、それは重複画像を消すプログラムか何かでまとめて殺す
https://forest.watch.impress.co.jp/library/software/dupfileeli/
+スクショの過程で尻切れトンボになっているダイアログ画像は、右下の青いカーソルの色素を検出できたか否かで判定して削除する

これは文章が全て表示され切るまで出てこないのでうってつけのチェッカーになる
画像からダイアログ部分のみをクリッピングする
出来上がった画像群をOCRにかける
ブルーアーカイブのダイアログは画面下部分にウィンドウが表示されるという形式のまま基本的にブレませんので、その点は問題ないかと思います。
ただし例外もございます。そう、先生のセリフです。
先生のセリフは選択肢という形で現れるので(実際に選択の余地はないにもかかわらず)、画面下部分をオートで切り抜くというような処理にしてしまうとすべて振り落とされることになります。
また、先生のセリフ以外にも例えば百花繚乱編で見られたような特殊演出テキストの場合はウィンドウに収まりませんので、これらも取りこぼすことになります。とはいえこっちは数がさほど多くないので例外的に手動対応するという手もなくはないですが。
先生のセリフを内包する、表示形式がブレないテキスト確認方法といえば「ログモード」があります。あそこはすべてのテキストをSMSのような形式で振り返れるので安定はするでしょう。しかし如何せん面倒くさい。ログ画面だけをまとめた動画なんてございませんので、やるとすればiPadの画面をPCに映して手動でストーリーを進めて最後までいったらログを開いてすべてスクロールして……という七面倒臭いことになりますので現実的ではございません。
そこで次のような方法を思いつきました。
先生のセリフ選択肢は、数の変化こそあれどウィンドウ画像は変わりませんので、おおよそ選択肢が表示される部分を見張っておいて、「先生のセリフウィンドウに使われている色」が一定以上検出されれば先生のセリフとみなし、該当箇所を切り抜く、という処理でございます。

つまりまとめるとこうなります。
まずゲーム画面全体のスクリーンショットをとる
上記が詰まったフォルダ内でiterateし、先生のセリフ色素が一定以上検出された場合はその箇所を、さもなくばセリフウィンドウ箇所をクリッピングし保存する
そうして処理された画像に対して一括でOCRをかける
要件定義は出来ました。では早速コーディングにうつりましょう。
画像に対する前処理
動画のスクレイピングは済んでいるものとします。
先生判定機
from PIL import Image
def check_color(image_path, x, y, target_color, tolerance=20):
"""
Check if the color at the specified coordinates is within the specified tolerance.
:param image_path: path to the image
:param x: the x-coordinate of the pixel
:param y: the y-coordinate of the pixel
:param target_color: the target color(R, G, B)
:param tolerance: the tolerance value
:return:
"""
image = Image.open(image_path)
pixel = image.getpixel((x, y))
if (
abs(pixel[0] - target_color[0]) <= tolerance and
abs(pixel[1] - target_color[1]) <= tolerance and
abs(pixel[2] - target_color[2]) <= tolerance
):
return True
else:
return False
def calculate_equivalent_position(new_width, new_height, x=342, y=385, old_width=1920, old_height=1080):
width_ratio = new_width / old_width
height_ratio = new_height / old_height
x_new = int(x * width_ratio)
y_new = int(y * height_ratio)
return x_new, y_new
# Example usage
image_path = スクショ
x,y = calculate_equivalent_position(1280, 720) # スクショ画像の画像サイズを入れれば自動で先生ウィンドウポジションを検出する
print(x,y)
target_color = (202, 222, 233) # ウィンドウの端の暗い青色
tolerance = 5 # 許容する色ズレ範囲。狭めるほど誤検出が減る
print(check_color(image_path, x, y, target_color, tolerance))こんなところで十分かと思います。そんな凝った処理は必要ございませんので。
OCR
from PIL import Image # バージョン: 9.5.0
import pytesseract # バージョン: 0.3.10
import cv2
import numpy as np
pytesseract.pytesseract.tesseract_cmd = r"Tesseract-OCR\tesseract.exe"
def preprocess_image(file_path):
# Define the tone curve points
# Replace these values with the coordinates of the points in your image
tone_curve_points = np.array([[0.0, 0.0], [0.65, 0.1], [0.7, 0.9], [1.0, 1.0]])
# Interpolate the tone curve points to create a LUT with 256 entries
lut = np.interp(np.linspace(0, 1, 256), tone_curve_points[:, 0], tone_curve_points[:, 1])
# Load the image
def imread(filename, flags=cv2.IMREAD_COLOR, dtype=np.uint8):
try:
n = np.fromfile(filename, dtype)
img = cv2.imdecode(n, flags)
return img
except Exception as e:
print(e)
return None
image = imread(file_path)
# grey scale
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply the LUT to the image
lutted_image = cv2.LUT(image, lut)
lutted_image *= 255
#cv2.imwrite("result.png", lutted_image)
return lutted_image
def extract_text(file_path):
# 画像を読み込む
image = preprocess_image(file_path)
im_pil = Image.fromarray(image.astype('uint8'))
# Tesseractを使って画像内のテキストを抽出する
text = pytesseract.image_to_string(im_pil, lang='jpn')
# 分かち書きされてるっぽいので治す
text = text.replace(" ", "")
return text
if __name__ == "__main__":
text = extract_text(r"11552f7-s.jpg")
print("Extracted text:", text)ブルーアーカイブのウィンドウ画像という前提下ですが、十分な精度が出ます。

ジュンコ美食研究会
また騙された!やっぱりインターネットは嘘の情報ばっかり!うわーん!
チナツ中紀委会
はい。温泉開発部は文字通り「温泉を開発すること」を主な活動としているのですが、
掘削機のような重機を使った大きな事故を争繋に起ことすので、ゲヘナの中でもかなり悪
名高い部類の部活です。常に100%とはいかないでしょうね。無論でございます。いかんせん無料のOCRでございますのでGoogleOCRにはかないません。ただGoogleの奴を使うとなると当然これだけの枚数を処理するとなればお金がかかりますので、私としてはそれを避けたいのでこうした次第でございます。
しかし十分内容が読み取れる精度だと思います。誤字脱字はAIで適当に修正できる範囲でしょう。
そんなこんなでブルーアーカイブをアーカイブすることが可能になりました。
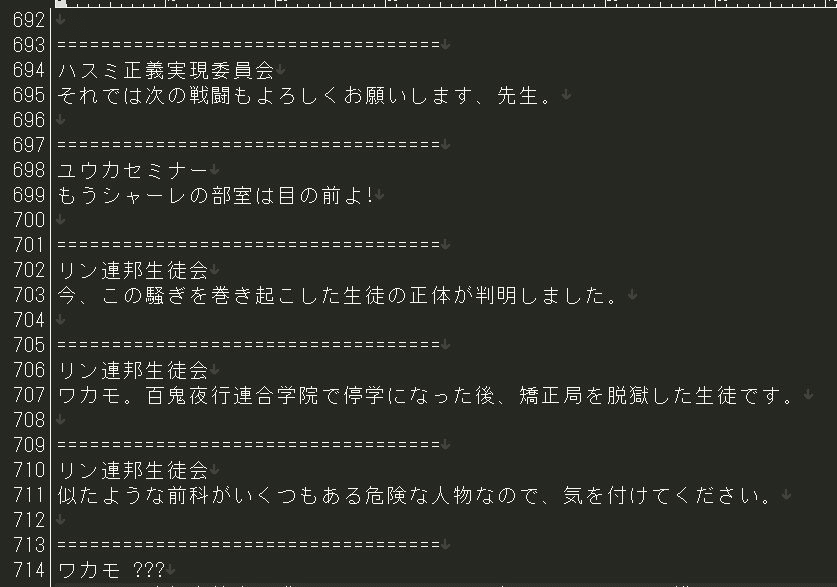
結果
ブルーアーカイブのストーリーをテキストファイル化できる!!!!!!!!!!!(ワザップ)
以上、ブルーアーカイブのストーリーをテキスト化する方法を紹介しました。ゲームを起動しなくても、テキストとしてストーリーや設定を確認できるようになりました。
今回の記事で学んだ方法を活用して、自分のお気に入りのゲームのストーリーもテキスト化してみてはいかがでしょうか。
さようなら。
この記事が気に入ったらサポートをしてみませんか?