
生成AIの本を執筆する者は一切の希望を捨てよ~2023年の生成AIと『生成AIで世界はこう変わる』執筆振り返り~

はじめに
東京大学 松尾研究室でAIの研究をしている今井翔太と申します.最近,『生成AIで世界はこう変わる』という本を出版させていただきました.
https://www.amazon.co.jp/dp/B0CM2YJ34N?ref_=cm_sw_r_cp_ud_dp_TRV649GZXZBTAPW2M0XB_1
本記事は,2024年1月7日に発売された生成AIに関する私の著書『生成AIで世界はこう変わる』の執筆(+発売後の動き)の振り返りと,その補強となる2023年(正確にはChatGPT登場の2022年後半〜です)の生成AIの展開に関するものです.実はnoteにおける初の記事になります.
AIの一般書の執筆というのは割とレア経験だと思われますので,読者層がイマイチわからない記事な気もしますが,本の性質上,生成AIという分野一般の2023年の展開と連動する部分があり,いくらかは参考になる部分があるでしょう.
本記事はもともと本の発売前の年明け直後に公開する予定でした.私は石川県出身で,年末〜年明けにかけて実家の石川県に帰省していたのですが,元日に石川県を襲った令和6年能登半島地震に被災し,しばらく実家で危険な状態が続いたことや,精神的な負担もあり公開が遅れることとなりました
本題に入る前に
本記事は,「本の振り返り」と言いつつ,私が本に書けなかったあれこれや,書いているうちに楽しくなってきた生成AI界隈の研究者視点での動向をひたすら書き殴ったものです.あんまりまとまった内容ではありません.少なくとも学術的なお作法は完全に無視しています.突然,長い解説が混じります.全体としても不必要に長いです.改行はほぼ気分で,誤字脱字が結構紛れている気がします.気になったところをつまみ読みしてください.noteのお作法はよくわかりませんが,大体話題ごとにブロックに分けています.また,ここに書いたことは私の主観・お気持ちで,私の周辺の人物や所属が同じ考えを持っていることを意味しません.
そのほか,「生成AI」というワードを強く意識した記事であることから,本来の研究における用語の使い方と若干ずれた表現が多くあります.例えば,ChatGPTなどを我々は普段「大規模言語モデル(LLM, Large Language Model)」と呼びんでいますが,本記事ではほとんどの部分で「言語生成AI」と呼びます.同様に拡散モデル系の手法はまとめて「画像生成AI」と表現しています.また,生成AIには言語,画像,音声など様々な分野がありますが,その影響の大きさから特に言語に関する話題が中心になります.
この記事は以下の3部構成+αです.
・2023年の生成AIの展開
・生成AIの本を執筆することの難しさ
・『生成AIで世界はこう変わる』執筆振り返り
・最後に
ほぼ独立していますので,気になった部分を読んでみてください.ChatGPT~2023年の生成AIの動向に興味がある方は1を,無謀にもこれから生成AIに関する書籍を書こうと思っている方は2,3を読むことをお勧めします.本の振り返り記事とはなんなのか.
なんでこんなに奇妙な記事になったのか
本の振り返り記事なのに,なんで生成AIの展開などという長ったらしい前置きがあるのか.これは,この記事で強調したい「生成AIの本を書くこと難しさ」に生成AI特有の事情が関わってきて,その辺の背景を知らないことにはうまく伝わらないと思ったためです.よって,既に生成AI界隈を追っている人はこの長い「前置き」を無視してもらっても構いません.
第一部:2023年の生成AIの展開
2022年:ChatGPTの登場と生成AIブームの始まり
2022年11月30日のChatGPT登場が全ての始まりでした.生成AIブームの始まりというだけでなく,世界中の人々が「本当にすごいAIが出てきた」,「我々人間と同じくらい賢いAIが出てきた」,「仕事が本当にAIが奪われるのでは」という意識を共有し,実際にそれが間違っていないことが証明され始める,まさに人類の歴史における超特大ビッグイベントの始まりです.研究者もChatGPTに触れたそれ以外の人も,この日とそれ以降の数日で「ステージが変わった」というのを実感していたことかと思います.
さて,ChatGPTは「Chat」が示すように,チャット,つまりユーザーとの対話形式のやりとりを行う,いわば対話AIサービスの一種の実装であり,そのベース技術には「GPT(Generative Pre-Trained Transformer)」が使用されています.GPTは,Transformerという元々はGoogleが「翻訳のために」開発したSelf-Attentionなる機構を持つちょっと変わったニューラルネットワークをWebから集めた大量のテキストで学習した言語モデルです.今でこそChatGPTの成功もあって,GPTとは自然言語による対話を行うAIである,という認識が常識ですが,実はGPTを使って対話形式のサービスを作るという発想は,そこまで自明のものではありません.詳しくは私の本や自然言語の教科書を読んでもらいたいのですが,言語モデルというは,なんらかの文章があった場合に次の単語の確率を求めるようなモデルを指します.端的にいうと,文章の続きを予測・出力していくモデルということになり,それをTransformerで実装して学習したものがGPTなのですが,文章の続きを出力することは,ユーザーの入力文に対していい感じに回答することとは別の処理のはずです.本当に文章の続きを出力するモデルをそのままの使い方でサービスに落とし込んだのであれば,以下のようなやりとりは発生しないでしょう.

さらに,AI分野の研究者はともかく,現在でも一般的には割と知られていない事実として,Transformerそのものには記憶能力はありません.プロンプトを1回入力して出力し,次に別のプロンプトを入れても前の出力は覚えていません.おや,ChatGPTではユーザーと何回ものプロンプトのやりとりで対話が続いているはずなのにおかしいですね.実は,ChatGPTのような対話サービスでは,毎回,過去のプロンプトの入力とChatGPTの出力を全て入力しているのです.つまり,ChatGPTが過去の対話を覚えているように見えるのは,毎回の1度の会話で,今現在のプロンプトだけでなく,今までの全てのプロンプトをまとめて入力しているからなのです.
ここまで考えると,GPTというのは意外と対話サービスに落とし込むのが面倒臭いものであると思えてくるのではないでしょうか.もちろんChatGPT以前にも言語モデルを使った対話サービスは存在したのですが,言語モデル(GPT)=対話という認識はそこまで強いものではなかったはずです.例えば,ChatGPT登場以前に日本で一番よく知られていた言語モデルの応用サービスは小説の文章を書いてくれる執筆支援だったと記憶しています.
ChatGPT実現には,強化学習(私の専門でもあります)の役割が大きかったとされています.はっきり言って,ChatGPT以前のGPTは,言語の性能はともかくとして,大規模なサービスに適用できるものではありませんでした.文法的には正しいし,質問にも答えているのに,非常に危ないことや,事実と異なることを頻繁に出力してきます.これをそのまま対話サービスなどに利用しようものなら,暴言拡散マシンになってしまいます.この手のAI対話サービスは,過去にいくつか登場していましたが,例えば,マイクロソフトのTayなどは「不適切な発言をした」として停止に追い込まれています.このようなサービスで高頻度で危ない発言をするAIは,どれだけ研究上は高い性能が出ていようとも,なかなか実装が難しいところでした.
ChatGPTはRLHF(人間からのフィードバックによる強化学習,Reinforcement Learning from Human Feedback)によってこの問題を解決しました.端的に言うと,人間がAIの複数出力に対して「この回答はダメ
.この回答はいい感じ.この回答は最高だ」とランクづけし,このランクづけされたデータから,いわばChatGPTのようなAIを学習するときに「回答の採点」を自動的にしてくれる報酬モデルを学習します.つまり,とあるプロンプトに対しては,複数の回答が考えられるわけですが,それらの回答のどれが「人間の価値観から見て好ましいか」を基準にランクがつけられ,報酬モデルは ChatGPTの出力の好ましさを判定するモデルになるわけです.そして,ChatGPTは,自分の出力に対して報酬モデルがどのような評価を返すのかを参考に学習することで,出力が人間にとって好ましくなるように調整されます.このようにして「AIを人間の価値観から見て好ましいように学習させること」行為を総称して,「アライメント(AIアライメント)」と言います.これはChatGPT以前に広く注目されていた概念とは言い難いですが,ChatGPTという人間の知能に匹敵するレベルのAIが出現するに至り,非常に重要になってきました.最近の言語生成AIや,さらにその先にある,人間と同等の知能を持つ汎用人工知能(AGI,Artificial General Intelligence),人間を遥かに超えた知能を持つ超知能(SuperIntelligence)を見据え,このアライメントをいかにうまく行っていくかは,研究者の主要な議論の一つです.
Galacticaの悲劇
ここで,以降の生成AIの展開について語る前に,それに関連した騒動を紹介します.
実はChatGPT公開のほんの少し前,研究者の中ではある一つの高性能な言語生成AI(大規模言語モデル)が話題になっていたのをご存知でしょうか.Galacticaというモデルで,Meta社が「科学技術の出力に強い」として,張り切って公開したモデルです.これはMeta社も相当気合を入れていたようで,パラメータ数は現在の基準でも大きい120B(1200億),実際研究者の視点でもかなりの性能を持っていました.ChatGPTレベルと言えるかは微妙ですが,当時の基準で言えばほぼ最先端レベル,当時のOpenAIのGPT-3が2020年の公開からだいぶ経ち,かなりクローズドだったことを考えると,これが生成AIブームのきっかけになって一番有名な言語生成AIになってもおかしくなかったはずです.
しかし,2024年現在を生きるほとんどの人間は,一部の研究者を除き,その名前を覚えている人はまずいません.なぜか.
先ほど,このGalacticaは「科学技術の出力に強い」モデルとして公開されたと言いました.科学知識は(少なくとも理工系においては)まずその知識が事実に基づいたものであるかどうかが最大の問題です.いくらそれっぽい回答であろうが,事実に基づかない生成された科学知識はガラクタ同然です.思想やアイディア,意見,あるいは生活知識などの言語生成と異なり,これを欠いた時点で試合終了です.ここまで聞けば,この記事に辿り着くような読者は何を言いたいのか察したことでしょう.そうです,ハルシネーションです.このGalactica,確かに科学知識に関して「それっぽい」出力をするのですが,この「それっぽさ」が本当に致命的でした.「強化学習は,ヘーゲルが提唱した自由意志を追求する学習手法です」くらいにめちゃくちゃな出力であれば,まだ良かったのです.実際,私はだいぶ昔からGPTを始めとした言語モデルを触っていましたが,大体出てくる主張はめちゃくちゃ,余程プロンプトを工夫しなければまともなやりとりは難しいと考えていたので,出力もさほど信用していなかったのです.しかし,Galactica本当に絶妙に「そ,そうだったのかぁ!!」と唸ってしまうハルシネーションをひたすら超自然に出力する困ったモデルでした(最近,Twitterで「カスの嘘」というのが話題になりましたが,アレに近いです).正確に言うと,これは科学知識を「Wikipediaっぽく」出力してくれるモデルだったのですが,この形式も相まって,ハルシネーションの威力が高かったのです.
以下はGalacticaの実際の出力です.記念すべき,今井が本格的に騙された初代ハルシネーションです.

「Attention Is All You Need」はTransformerが提案された,おそらくAI界隈で一番有名な論文のタイトルです.この論文について語ってくれと,私はプロンプトを投げたのですが,その出力は「実はこの"Attention Is All You Need"と言う文言は,1963年に公開されたHouse of the Rising Sunと言う楽曲の歌詞が元ネタなんだぜ!」というもので,私はこのトリビアに感動して,完全に騙されてしまいました.当時のこの出力を見た感動は大変大きく,MTG中だったのですが,その元ネタの実物を探し始めました.はい,これがとんでもない大嘘で,こんな元ネタは存在しませんでした.この案件は研究室内でも笑いのネタになり,最終的には翌年の人工知能学会でも,松尾研の人間が行ったチュートリアルの資料に収録されています.そして,この騙された悔しさを押し込んだ今井の渾身のツイートが以下です.

幸いなことに(?)このGalacticaに騙された人間は私だけではなかったらしく,Galacticaは研究者コミュニティで炎上することになりました.最終的にMetaはGalacticaの公開停止を決定しています(日本でこの炎上の片棒を意識せず担いだのが私なのですが・・・).この騒動はMeta視点では本当に悔しかったらしく,MetaのAI部門のトップであるルカン先生はChatGPT流行後に色々と噛み付いたり,言語モデルに関して物申したりと,ちょっと厄介キャラが加速してしまいました.
しかし,これが影響したのかどうかはわかりませんが,MetaはOpenAIのクローズド戦略からは離れて,Llamaを中心としたオープンモデル勢力を引っ張るようになりました.これは本当に大きく,これから記載する大規模言語モデルのオープンモデル開発に多大な影響を与えます.
Galacticaは犠牲になったのだ・・・.
2023年1月〜3月:生成AIブームの本格化と主要プレイヤーの競争の激化
年が明けて2023年になる頃には,ChatGPTの噂は研究者コミュティを超えて,一般人も含めて大きく広がっていました.メディアもこの騒ぎを聞きつけ,連日AIの凄さを報道するようになっています.私はこの段階に至って,これは「第4次AIブーム」であると考えるようになっていました.私に限らず,松尾先生などもいくつかの記事で似たようなことを発言しています.

実は,「生成AI(Generative AI)」という単語が本格的に使われ始めたのはこの時期になってからです.本にも書いていますが,「生成AI」という単語は,研究者が元々使っていた単語ではありません.もう少し具体的には,生成AIという単語は元々「画像生成AI」や「文章生成AI」のように「〇〇生成AI」という形で,特定の分野の生成的な動作をするモデルに対して使われており,「生成AI」という単語が単体で使われることはかなり稀でした(例えばTwitterやGoogle検索で時期を指定して「生成AI」と検索すると,2023年以前はこの用法ばかり出てきます).機械学習の分野で厳密に定義されている大きな分類として「識別モデル」と「生成モデル」というものがありますが,生成AIはこの生成モデルとも異なる概念です.識別モデルであるにも関わらず,その最終的な出力が生成っぽいという理由で生成AIと呼ばれているものまで存在します.
日本において「生成AI」という単語が単体で本格的に用いられ始めたのは,年明け直後くらい,1月半ばを過ぎたぐらいの時期です.この用法は,研究者コミュニティからではなく,少なくとも日本ではマスコミ,大手新聞社の報道を起点に広まったと考えています.以下は,最初期に「生成AI」という単語が利用されているメディアの記事の一例ですが,この時期以前に「生成AI」と検索しても,出てくるのは大体が先行して有名になっていた「画像生成AI」です.
既に2022年夏頃には有名になっていた画像生成AIと, ChatGPTによって注目され始めた言語生成AIの騒動をひとまとめにして扱う場合に,この「生成AI」という単語は非常に都合がよかったのでしょう.研究者は,私の周りも含めて「生成AIってなにwww」などと当初は反応していたのを記憶していますが,結局これが定着し,私も「生成AI」に関する本を書くことになりました.
参考に,英語での生成AI関連ワードのGoogleトレンドを見てみましょう.海外でも大体事情は同じようです.
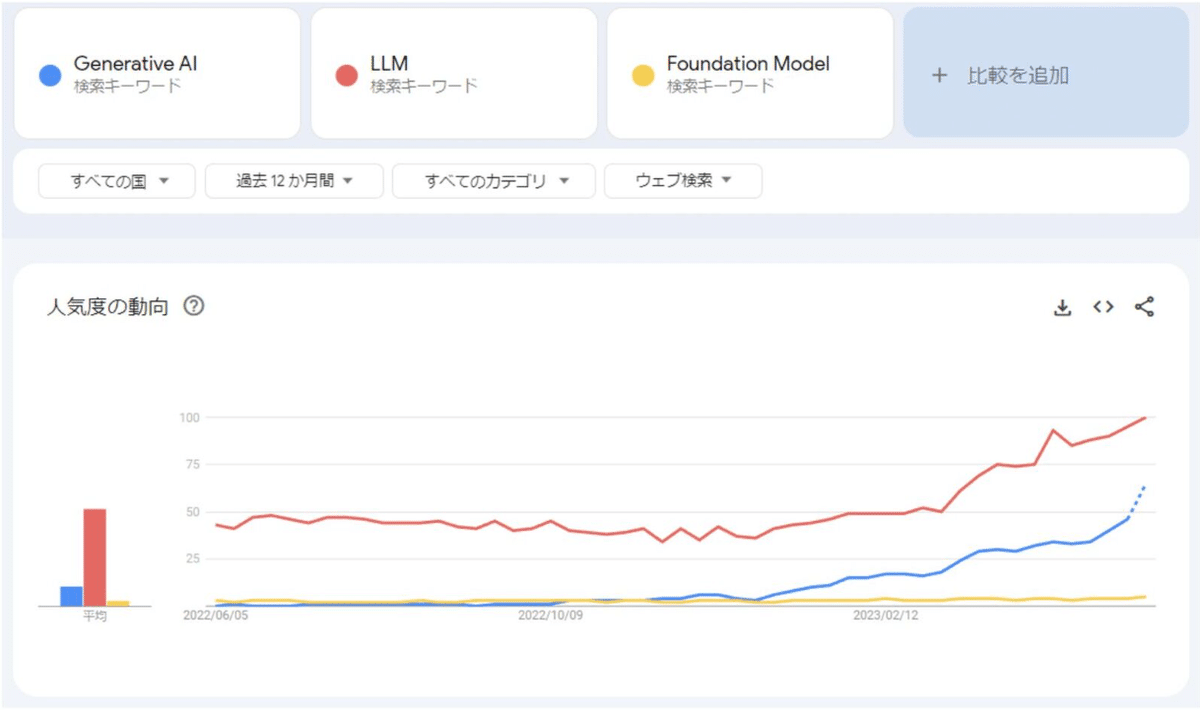
このように,この時期から画像,言語の両分野の生成的な動作を行うAIの急速な発展を受けて,世間一般を巻き込んだ「生成AIブーム」の動きが始まります.2月7日くらいには,GoogleがChatGPTに対抗して,対話AIサービスのBardを発表,翌日くらいにはマイクロソフトがChatGPTを組み込んだ新型BingとEdgeを公開して,現在まで続く生成AI覇権を目指したビッグテック同士の大戦争も本格化しています.2月の後半にはイーロン・マスクも研究者を集めてオレオレ言語モデル開発に乗り出しているという報道が出てきました.2月最終日くらいにはMeta社が初の本格的なオープンモデルであるLlamaを公開するのですが,流石にこの時点ではChatGPTに追いつけるとは誰も考えておらず,このオープンモデルのコミュニティの活動が本格的に活発化するのはもうちょっと後です.
さて,2023年の3月ですが,この月は後には人類史上においてコンピュータ技術に最も発展があった「奇跡の1ヶ月」として記録されるかもしれません.いや既に記録されていてもいい気がします.それくらい,とてつもない革新が生成AI界隈に連続して起こりました.
当時の私は,今から解説する生成AI関連の発表を受けて,興奮のあまり,以下のツイートをしているのですが,これが1000RTくらいされたことを考えると,同じような意識をみんな共有していたのでしょう.
(これはちょっと興奮し過ぎて,驚き仕草がすぎたなぁと,今では反省しています)
この1週間,もしかしたら人類史上で一番,技術の発展の加速が感じられる1週間だったのでは?
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) March 17, 2023
・ OpenAIからGPT-4の発表
・GoogleからPaLM API,製品への生成AI搭載の発表
・マイクロソフトからOfficeへのGPT-4搭載の発表
・手軽に扱える超高性能な言語モデルAlpaca
・PyTorch2.0
まず,3月2日には,ChatGPTが満を辞してAPIを公開しました.元々,OpenAIはChatGPTの前身となるGPT-3.5シリーズのAPIを公開していて,それを利用したアプリケーションは元々存在したのですが,ChatGPTの圧倒的な性能をベースにしたAPI公開の恩恵は凄まじいものでした.以前のAPIから利用されていた,GPT-Index(後にLlama-Indexへと改称),Langchainなどの周辺ライブラリも即座に対応し,まさに言語生成AIアプリ・サービスの大開発時代が始まりました.私自身や,私の所属する松尾研,その周辺でもみんなChatGPTのAPIを利用して次々とアプリを開発し始めました.
ほぼ同時期には,VALL-E Xというモデルがマイクロソフトから公開されています,これは音声の生成AIなのですが,いわばドラえもんに出てくる「ほんやくコンニャク」とも言える代物で,自分の声と意味を維持したまま,喋った声を別の言語に変換できます.また,順番は少し前後しますが,この時期には,数秒の音声からその人物の声を自由に生成せきるSo-Vits-SVCやRVCなどといった技術も公開されており,音声方面でもAIの性能が徐々に認知されていった時期です.
日本時間の3月14日〜15日くらいが,この伝説的な3月のピークでした,まず14日夜にGoogleが当時最大のパラメータ数を持つ言語生成AIであったPaLMのAPIを公開し,Gmailなどの既存アプリにその機能を組み込むと発表しました.当時は(厳密にいうと,リーク情報を除けば現在も公開されてはいないのですが)ChatGPTのパラメータ数は公開されておらず,最大のパラメータ数をもつとされたPaLMの性能が解放されるということで,これはGoogleがOpenAI/マイクロソフト陣営に追いつくのもすぐという期待が高まりました.しかし騒ぎは数時間くらいで更新されます.
その3時間後(15日深夜2時)くらいに,OpenAIが突然,最新の言語生成AIであるGPT-4を公開しました.GPT-4の噂は以前から流れており,「言語だけでなく画像も入力できるマルチモーダルモデルだ」,「既にすごい今のChatGPTよりも圧倒的な性能を持つらしい」との話がまことしやかに流れていましたが,発表されたGPT-4はその噂通りの圧倒的な性能を持つマルチモーダルモデルでした.この時点で,GoogleのPaLMの発表はほとんど忘れ去られ,日本時間で言えば,GPT-4の発表から数時間後,朝を迎える頃には,ほとんどみんなGPT-4の話ばかりしていたと記憶しています.これは完全に余談ですが,おそらく時差の関係で,生成AIの重大な発表は日本時間では深夜に行われることが多く(アメリカとは約15時間差.日本の深夜は,アメリカではお昼前後),生成AI関連の発表が噂されている時期は,起きているのが辛いです.
GPT-4発表後,マイクロソフトは即座にGPT-4を自社のOffice製品に搭載すると発表しました.事務作業の生産性を劇的に向上させるとの期待が大きくなり,いよいよ産業革命か,という雰囲気だったと記憶しています.
そのほか,GPT-4の発表には及ばないものの,この時期にはLlamaに続く高性能オープンモデルとして,LlamaをファインチューニングしたAlpacaが公開されました.このあたりでオープンモデル界隈も強気になってきて「GPT-3.5に匹敵する」という宣伝が出ています.いわゆる野良の開発者コミュニティでもGPT-3.5くらいなら・・・という考えが広まり,オープンモデルの開発がさらに活発化する契機になっています.
あまりにもこの時期の発表が多すぎて,全部説明しきれないのですが,他にもChatGPTからさまざまなアプリを呼び出せるChatGPT Plugin,Bingで画像生成できるBing Image Creator,Copilot X,さらに技術の他にも「GPT-4などは汎用技術であり,ホワイトカラーのほとんどの仕事は多大な影響を受ける」とそのタイトルで話題になった『GPTSs are GPTs』論文など,とにかく2023年3月の生成AI界隈勢いは凄まじいものがありました.どこで見たのか忘れてしまったのですが「毎週が新型iPhoneの発表会」という表現を見た時には妙な納得感で笑ってしまいました.この3月の最終盤には,話題のトドメと言わんばかりに,イーロン・マスクや有名なAI研究者など1000人が署名した「安全性を考慮し,半年間AI開発を中断せよ」と主張する書簡が発表されています.今から考えても,ほとんどSFの世界のような出来事でした.
(なお,イーロン・マスクはこのような書簡に署名する一方で,同時期にAI学習のためのGPUをこっそりかき集めていたことが後に明らかになっています.)
研究者視点で,この時期に決定的になってしまった,とある傾向について強調したいことがあります.生成AIコミュニティの2極化,具体的にはオープン派とクローズド派の分断です.今でこそ当たり前になってしまいますがChatGPTのベースになっているGPT-3.5やGPT-4の学習手法やパラメータ数などが一切公開されていないのは,AI研究の歴史を踏まえるとかなり異常なことです.そもそも,ChatGPTが登場してからGPT-4の登場までは,私も含めて「OpenAIさん,まぁ今は忙しいやろうけど,いつかChatGPTの論文も公開してくれるやろ.arXivかな?それともNatureとかScience掲載になるのかな?楽しみやなぁ」という意識が研究コミュニティでは少なからずあったと思います.しかし,この考えは,GPT-4発表と同時に公開された「GPT-4 Technical Report」の存在により消え去りました.このTechninical Reportと称した論文っぽいものは,当時の研究者から見るとだいぶヘンテコなもので,普通は論文に記載されていて当たり前のはずの「提案手法(Method)」やハイパーパラメータ(人間側で設定する,学習に関連する値.モデルのサイズも含む)など,GPT-4を他の研究者が再現するのに必要な事項が一切乗っていません.この論文(?)の序論には以下のような文言が書かれています.
原文
Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
日本語訳
GPT-4のような大規模モデルの競争環境と安全への影響の両方を考慮し、本レポートでは、アーキテクチャ(モデルサイズを含む)、ハードウェア、トレーニング計算、データセット構築、トレーニング方法、または類似の詳細については記載していません。
つまり,「このGPT-4はあんまりにも強力なので,競合が出てきたら困るから,この論文(?)ではモデルの再現に必要な情報は一切公開しません!!」と言っているわけです.何度も強調しますが,これはAI研究の歴史で見ると結構異常なことです.OpenAIは,今までのGPTシリーズの論文はパラメータ数を含めて,再現に必要な情報はとりあえず公開していました(最も,それらの情報があったとして,必要な計算資源やデータを用意するのが物理的に不可能で,実質的には再現しようとするものがいなかったという状況ではありました.).これはOpenAI以外の研究機関でも同様です.そもそも,新しい手法が開発されたとして,それが公開されなければ人類全体としての知識が積み上がらないのです.例えば,以下のGPT-3の論文などはアブストの段階で,この辺の情報を丁寧に書いてくれています.とは言え,GPT-3も学習済みパラメータは公開されなかったので,この傾向はこの時期から始まっていたとも言えます.
OpenAIは,その設立の理念の一つは「安全で透明性のある人工知能の開発を目的とする」ことだったはずです.まさにその透明性を体現するかのように「Open」という単語を掲げているわけですが,皮肉なことに,OpenAIはこの後,オープンAIなのに生成AIコミュニティの「クローズド」派の筆頭になり,それが現在まで続いています.「奴らはOpenAIではなくClosedAIだ」というジョークを何度も耳にしています.さらに悪いことには,このOpenAIの傾向を踏襲する形で,ビッグテックの大規模な生成AIはクロースドであることが半ば常識となってしまい,以前はPaLMの詳細を公開していたGoogleなどもPaLM2や最近公開されたGeminiなどの詳細情報は公開していません.

Galacticaが失敗した後にChatGPTで成り上がったOpenAIに一矢報いたくてこれに対抗するかのようにMeta社はLlamaという言語生成AIをオープン化,つまり論文で詳細を公開するとともに,誰でもダウンロード可能にして調整・利用できる形にする,いわばオープン戦略をとっています.なお,オープン"ソース"モデルというのは厳密な定義があるので,ここでは使用せず,本記事では一貫してこのように公開されているモデルをオープンモデルと呼びます.3月まででビッグテックからの生成AIに関する大型発表ラッシュが終わって以降は,野良コミュニティでこのオープンモデルを使った開発が活発化していきます.
2023年4月〜6月 オープンモデルと生成AIユーザーコミュニティの活性化
4月~6月は,Llamaベースのモデルや,非Llamaベースの様々なオープンモデル,機能特化型のオープンモデル,日本では日本語に特化したオープンモデルの公開が多くなりました.3月までの野良コミュニティの生成AIアプリケーション開発は,GPT-3.5やChatGPTのAPIを使って,周辺のシステム開発に終始していましたが,この時期になると自前で学習・調整したオリジナルのモデルを組み込んだサービスが出てきます.
ちょっと流れを切りますが,この時期は新年度を迎えるタイミングということで,生成AIに対する社会の反応のお話からになります.
2023年にChatGPTが登場した時点で,近いうちに何らかの形で企業の業務,あるいは教育におけるレポートなどに生成AIが使われるようになることは,ほぼ誰でも予測していたでしょう.新年度に新しい所属者を迎えるということもあって,様々な機関が「この組織においては生成AIをどのように使うか/使うべきでないか」を発表しました.私は大学の研究者ですので,大学の対応に限った話になりますが,これは大学によってかなり差がありました.まず,生成AIを積極的に使うことを表明したのは,私も所属する東京大学です.4月に入った直後,副学長名で以下のような声明が発表されました.
https://utelecon.adm.u-tokyo.ac.jp/docs/20230403-generative-ai
この声明における「人類はこの数ヶ月でもうすでにルビコン川を渡ってしまったのかもしれないのです」という表現は大変にインパクトがあるもので,東大の声明が記憶に残っている方も多いと思われます.この声明における「どのようにしたら問題を生じないようにできるのか、その方向性を見出すべく行動することが重要」という文言が端的に示していますが,東大はとにかく生成AIを積極的に使い,その利用法を社会の変化を先取りして把握するとともに,その原理の研究も進めるという姿勢でした.その上で,その利用はあくまで作業のサポートにとどめること,使いこなすには専門的な知識が必要であり,今後も勉強や研究を怠ることはできないということが強調されています.だいぶ後になりますが,東大は総理大臣を招いた生成AIのシンポジウムを開催したり,構成員にGPT-4が無料で使えるように計らったりと,生成AIに対する好意的な姿勢は一貫しています.
一方で,生成AIの利用に関してかなり否定的な声明を出したのは上智大学です.その声明は東大と比べて簡潔ですが,生成AIの利用に関してかなり慎重な姿勢が読み取れます.以下にその声明(成績評価における対応方針)を引用します.
リアクションペーパー、レポート、小論文、学位論文等の課題への取り組みにおいて、 ChatGPT 等の AI チャットボットが生成した文章、プログラムソースコード、計算結果等 は本人が作成したものではないので、使用を認めない。検出ツール等で使用が確認された場 合は、本学の不正行為に関する処分規程に則り、厳格な対応を行う。ただし、試験における 「持ち込み可」と同様に、教員の許可があればその指示の範囲内で使うことは可とする。
これが「生成AIを使ってレポートやコードの全てを出力するような利用は認めない」などであればまだしも,声明をそのまま受け取れば,課題への取り組みで少しでも生成AIの出力に頼ったらアウトということになります.また,生成AIの検出ツールはこの記事を執筆している段階でも決定的なものは存在せず,むしろ検出可能と謳うツールによって無用な混乱がもたらされているのですが,このような検出ツールも積極的に利用するような姿勢が出ています.最も,最終的には教員の判断に任せるなど,完全に利用を禁止するのは不可能という認識はあったと思われます.ともあれ,東大の声明と比較すると,同じ大学であっても明らかに対応が違うことがわかるでしょう.
(なお,上智大学は10月くらいにもう少しマイルドな声明も出しています)
大学以外の組織の対応についても色々と聞いています.残念ながら内情をよく知らない私がここで議論することはできませんが,とにかくいろんな機関で生成AIのとりあえずの方針が決定されたのはこのタイミングでした.
また,これは研究者間では大変話題になった事件ですが,Google傘下のAIの2大研究組織,つまりGoogleAIとDeepMindが統合されてGoogle DeepMindになることも4月に発表されました.現在の生成AIブームにおいて,研究開発をさらに加速させるのが目的だということです.実はこの2者,研究者コミュニティではあまり仲がよろしくないという噂が結構昔から流れていました(本当かどうかは知りません).その二つを合体させる決断をさせた生成AIのインパクトの大きさを感じるところです.また,Google関連では,現在の生成AI技術の基盤になっている深層学習の生みの親ジェフリー・ヒントン先生が,長年務めたGoogleを突如退社しました.生成AIブームから入ってきた人で,それ以前のAI研究の歴史に関してあまり知識がない人のために補足すると,ヒントン先生は上記の業績が示すように,最も有名で尊敬されている,まさにAI研究者の頂点に立つ人物で,ヒントン先生のAIに関する行動は一つ一つが大きな意味を持ちます.そのヒントン先生がGoogleを退社した理由もまた生成AIでした.そのあまりの発展速度は,基盤技術の生みの親であるヒントン先生の想像すら超えていたということで,「霧の中にいるようだ.これから何が起きるかわからない」,「ニューラルネットワークでは脳で起きていることよりもすごいことが起きているかもしれない」などと発言し,自由な立場からAI発展を見守りたくなったのが理由のようです.
さて,話をオープンモデルに戻します.
オープンモデルコミュニティから,多くのモデルの発表が続き,5月くらいには英語性能だけを見れば,ChatGPTの初期の性能に迫るものが出てきました.StableLMやVicuna,MPTなどと例を挙げれば,「あったあったそんなやつ」と,生成AIの動向を追っていた人ならこの時期に大量に出てきたオープンモデルの数々を思い出せるのではないでしょうか.ちょうどこのオープンモデルが盛り上がっていた時期のど真ん中に,私は理化学研究所で言語生成AIに関する招待講演を行いました.ここでは,オープンモデルの盛り上がりについて力を込めて話しました.以下は実際に講演で使った資料のスライドの一部です(資料自体はいつか公開するといいつつ,整理が追いつかず非公開です).


この時期にオープンモデルに関係して特筆べき出来事は,「Googleの関係者」によるものとされる,オープンモデルの発展とクローズドモデルに関する考察の文書が出回ったことです.この文書が本当にGoogle内部のものだったかどうかはともかくとして,述べられていることは根拠が説明されていて,示されている数値も研究者視点で妥当に見えるものでした.この文書の中では,以下の点が強調されていました.
・GoogleやOpenAIといえど,学習に関する秘密のテクニックはない
・そもそもGoogleやOpenAIが持つLLMは,再学習が困難で改善が難しい
・オープンソースではLoRAなどの安価で簡単なファインチューニングで誰もが自由に言語モデルの性能を追加していけるため,改善スピードが高速
・オープンソースの開発者自信がユーザーであり,言語モデルに必要な知識を追加できる
この文書の内容を受けて,オープンモデルコミュニティはさらに盛り上がりました.当時は,後数ヶ月でChatGPTに追いつける,何ならGPT-4ですら年内に追いつけるのでは,という雰囲気すらあったと思います.
ただ,これは現在から見るとちょっと楽観的すぎる考えでした.英語性能はともかく,ChatGPT/GPT-4の多言語性能やハルシネーションの少なさは凄まじいものがあり,GPT-4はこの記事を執筆している2024年の2月でも追いついたモデルが事実上は存在せず(Gemini Ultraは少し様子見です),ChatGPTのGPT-3.5版(GPT-3.5-turbo)に関してもようやく追いついたと認めてもいいかも,なオープンモデルが最近登場したところです.

そして,6月後半にはまた大きなリーク騒動がありました.これは開発者や研究者にとっては大変重要な情報を提供しているとともに,オープンモデルコミュニティにとっては「うへぇマジかよ」とある種の打撃を与えるものでした.GPT-4のアーキテクチャの詳細が出回ったのです.先ほどのGoogleの文書と違い,GPT-4の詳細はまさに生成AI界隈最大の謎とも言えるものです.常識的にはこの文書がすぐに信じてもらえるわけがなかったのですが,このリークの発信源が人物が比較的信用できる人物であったこと,シリコンバレーの一部コミュニティではこのリークとほぼ一致する情報が以前から流れており,矛盾がほぼなかったことなどが原因で,ほぼ当日中にこのリークは真だと受け止められました.
このリークによると,GPT-4は,複数のエキスパートモデルを組み合わせたMoE(Mixture of Expert)モデルであり,各モデルのパラメータ数は220B(2200億),エキスパートモデルの個数は8個で総パラメータ数が1.76兆,つまり前代未聞の1兆パラメータ超えモデルであるということでした.実際に言語生成AIを研究している立場からすると,この情報は斬新であるとともに,気が遠くなるような衝撃的な内容でした.当時公開されているモデルの最大サイズが5000億程度だったところ(なお,後述するようなMoEアーキテクチャは少々特殊な構造なのでこのパラメータ数レースでは当時番外扱いされることも多かったです),それの3倍のモデルだというのですから,それはもうびっくりです.私自身はどれだけ大きくても1兆ギリギリだと考えていました.ここまでのサイズになると,学習はおろか運用コストも尋常ではないことは容易に想像でき,当時GPT-4の機能解放が全く進んでいなかったのも,さもありなん・・・と考えていました.私の驚きはともかく,このリークの特に重要な点は,以下の2点に集約されます.
・とにかくパラメータ数が大きいモデルが強い.GPT-4は単純に現在最大のモデルであることに強みの核があり,スケーリング則 Is All You Need
・このレベルのパラメータ数になると通常のアーキテクチャで学習・運用を行うのはまず不可能.MoEを採用したOpenAIは賢く,これからはMoEを学習する手法が主流になるかもしれない.

この記事でスケーリング則を知った人もいるかもしれないので,簡単に説明します.スケーリング則によると,言語生成AIの最終的な性能は,モデルサイズ(パラメータ数),データの量,計算量の3つの変数に依存して決定します.3つの変数を単純に増やすためにはお金が必要であり,生成AIの話題でGPUや金銭の話題が多く出てくるのは,この辺が関係しています.まさにMoney Is All You Needです.先ほどからやたらパラメータ数にこだわった説明をしているのは,このスケーリング則を意識したものです.参考に,主要な言語生成AIのパラメータ数がどうなっているのかを以下に示します.以下の図を見れば,GPT-4の1.76兆(1760B)という総パラメータ数がどれだけ異常かがわかると思います.

なお,この図ではGPT-4は不明となっている.
さらに,このMoEについて補足します.MoE自体はGPT-4が初めて採用した手法ではなく,言語モデルのアーキテクチャとしてはChatGPT以前から一部で採用され,その性能が明らかになっていたものです.何が利点なのかというと,MoEは複数モデルがそれぞれ特定のタスクに特化した役割分担を行なっています.つまり,モデル全体としては膨大なパラメータを持っていながらも,実質的にはタスクによって学習するモデルが一部で済むことから,最小限のコストで学習できるということです(が,実は各モデルが役割分担をしているという点については割と最近別の説が出ていることにも注意です).ChatGPT以前の有名なMoEモデルとしてはSwitch Transformerがあります.これは名前の通り,入力トークンに応じてRouterと呼ばれる気候で内部処理がスイッチ(各エキスパートにトークンを割り当てる)する性質を持ちます.Switch Transformerの総パラメータ数は当時としては破格の1兆超えで,まさにMoEアーキテクチャはパラメータ数がひたすら大きいモデルを学習するのに打ってつけの手法だったと言えます.とはいえ,この段階ではChatGPTに追いつこうとしている主要モデルにMoEを採用していたものは,少なくとも私が記憶している限りは皆無で,このリークを機にMoEへの注目は割と久しぶりに高まりました.このリークについては続きがあり,7月前半にはさらに文書の形でGPT-4の詳細が発表されました.このリークは,以前のリークをほぼ裏付けるような形であったことや,一応記事が有料だったので,ここでは詳細は書きません.

ともあれ,GPT-4があんまりにも巨大なモデルだったことが,確定ではないものの明らかになったことで,「オープンモデルであれに追いつくのは無理では?」,「スケーリング則はやっぱり正義やったんやなぁ」という雰囲気が出てきました.実際,現在までGPT-3.5はともかくGPT-4に比肩するオープンなモデルは存在しておらず,とにかく巨大なモデルを学習しなければGPT-4には勝てそうにないという懸念は間違ってなかったことになります.
5月以降には,世界の生成AIコミュニティ全体と並走する形で,日本においても日本語に特化したオープンモデルの公開が相次いでいました.5月にはサイバーエージェントがOpenCalm(70億パラメータ),rinna社がjapanese-GPT-neox(36億パラメータ)を出しています
以下は余談です.前述の私の理研における講演は5月17日で,先ほどの2つの日本語特化モデルの公開は5月16日,17日に行われています.この講演では先ほど書いたようにオープンモデルの動向について力を入れて解説していたのですが,私のまさに講演中(スマホなどで情報を見ることもできない)に裏ではjapanese-GPT-neoxが発表されていました.色々と講演で喋った後に「あのー,こんなのが公開されているのですが,これについてはいかがですか?」と質問され「!??」となったのをよく覚えています.個人的に,生成AI界隈の展開の早さを実感した出来事です.
ところで,なんで「日本語特化」のモデルが必要なのでしょうか.例えば,ChatGPT/GPT-4にはGPT-4-japaneseのようなモデルは存在しません.なんでわざわざ日本語に特化したモデルを苦労して単体で作る必要があるのか.この理由は簡単で,オープンなモデルクローズドなモデル問わず,世界の言語生成AIはほぼ全てが,日本語がとても下手だからです(開発のノウハウを蓄積するのに良い取っ掛かりという事情もあるかもしれません).日本語に限った話ではなく,英語以外はほとんど下手です.世界における英語話者の分布を考えると開発者視点ではこれでも十分なのですが,残念なことに,我々日本人はあまりにも恵まれた(教育や生活のほとんどが日本語で完結する)日本語環境にいる(+比較言語学的な分類で日本語が英語のようなインド・ヨーロッパ語族から離れている)ために,英語の読み書きがあまり上手ではありません.日本語がうまく扱えるオープンモデルを作ることは,日本国内における生成AIの開発と利用を飛躍的に加速させるものであり,産業上の恩恵は計り知れません.国内でスタンダードになるようなモデルを作れれば,まさに覇権です.
ChatGPTやGPT-4の日本語ペラペラっぷりは,現在の感覚でもかなり異常です.普通の言語モデルが英語ばかり得意で他の言語はうーんというのは,データセットの元になるWeb上の言語の分布を考えると自然なことです.Web上の文章・情報はほとんど英語で書かれています.例えば,InstructGPTの論文では,データセットに占める英語の割合は96%と書かれています.普通にデータセットを集めて学習すれば英語だけ超うまいモデルになるのは必然です.実際,現在でもほとんどのモデルはそうです.GPT-4に匹敵するとされるGemini Ultraですらその傾向があり,日本語だと,たまに頓珍漢な回答をしてきたり,日本語の解答中に別の言語が混じったりします(なお,GPT-4は日本語が得意でも英語でプロンプトを入力したときの方が性能は大きく上がります).OpenAIのモデルだけ日本語が異常にうまい(日本語特化モデルでも超えるハードルが高い),正確にはあれほど多言語をうまく扱えるのは,私が把握している限りでは今でも研究上の謎です.単に全ての言語の量が多かったという話なのか,それともデータ上の言語の割合なのか,それとも学習上の工夫なのか.
(この辺,私が詳しくないだけで詳細な研究が出ている可能性もあるので,完全理解者はご一報を)
2023年7月〜9月 オープンモデルの発展や生成AIの社会実装が進む
この時期には,生成AIの技術研究そのものよりは,社会実装の方が進んでいたように思います.オープンモデルの盛り上がりも相変わらずでした.
まず一番反応が大きかったのは,ChatGPTに搭載されたCodeInterpreterです.それまでのChatGPTはコード生成が得意と言っても,そのコードにエラーがないかどうかを確かめてはくれないし,実行もできない,出力されるコードは一部で,完結させるには長い対話が必要などという弱点があったのですが,CodeInterpreterでは,用件をプロンプトで伝えれば,コードを完成させ,コードの実行,エラーの検出,データをついでに入力すればデータの解析まで自動でやってくれます.特にデータ分析を行う人からはこの機能は好評だったようで,Advanced data analysisなどの名前を変えながら,現在も多く使われるChatGPTの主要機能になっています.Open Interpreterという,この機能のオープン実装も後に出てきました.
GPT-4のAPIはこの時期まで抽選だったのですが,7月前半に全体公開されました.最もGPT-4のAPIはgpt-3.5-turboと比べると非常に高額で,現在に至っても,余程高度な言語性能が要求されない限りはそこまで使われている訳ではない気がします.同時期にOpenAIはChatGPTのファインチューニング機能が後に解放されると発表しています.
ここで,長らく生成AIの表舞台からは姿を消していた(…わけではないのですがChatGPTがあまりにも高機能すぎて影が薄かった)GoogleのBardにマルチモーダル機能(?)が実装され話題になります.「?」なのは,これがBardに搭載されている言語モデルが本格的なマルチモーダルモデルになったのか,既存のGoogleレンズとの組み合わせだったのかよくわからないためです.とりあえず,性能については良好で,例えば紙切れに適当にWebサイトの外形を書いて写真を撮って読み込ませればそのサイトのコードが出てくる,といったマルチモーダルモデルの十八番運用は,限定的ではありますが可能でした.GPT-4のマルチモーダル機能は3月時点で「可能である」ことは公開されていましたが,おそらくは運用コストの問題などもあって,この時点では解放されていませんでした.この点についてはGoogleが先行したと言えます.
オープンモデル界隈で大きかったのはMetaによるLlama2の公開です.最大のモデルが70B(700億パラメータ)とかなり巨大で,Meta自身が「ChatGPTに匹敵する」と宣伝する通り,オープンモデルとしては破格の性能でした.これはこの記事を執筆している2024年現在でもオープンモデルの調整元になっている,業界標準モデルとして長く君臨しています.現在高性能なモデルのベースの多くはこのLlama2でしょう.
7月後半には大変面白い論文が出てきます.なんとChatGPT/GPT-4の性能がどんどん下がっている主張するものです.以下の論文です.
この論文における以下の図は衝撃でした.

つまり,3月と6月のChatGPT/GPT-4の性能を比較すると,多くの分野で6月版の方が馬鹿だったというのです.OpenAIはChatGPTなどのAPIを更新し続けており,各APIは更新日に対応したものが存在するのですが,より昔のものの方が性能が良いという,逆転現象が起こっている訳です.実はこの時期に「最近ChatGPTの様子なんかおかしくないか?」という反応は,この論文が公開される前からコミュニティで増加していました.以前は答えてくれた質問に最近は答えてくれない,出力が完結すぎる,数学ができなくなった,など機能低下を示す兆候がユーザーからも多く報告されていた中,この論文はChatGPT/GPT-4の機能低下を裏付けるものでした.
これについては色々と仮説があり,運用コストの問題でモデルサイズを小さくしようとしたこと,あるいは不適切な出力を抑えるためにアライメントをやりすぎた結果などと言われています.この傾向はどうも今も続いているようで,性能低下とはいかないまでもChatGPTの出力性能は時期によって異なり不安定です.
そのほか,LongNetと呼ばれるトークン制限が10億トークンを超える脅威的な言語生成AIの手法も出てきました.ChatGPTのような言語生成AIにはトークン制限(これはちょっと馴染みが薄いと思われるので,単純にトークン数=文字数と考えてください)と呼ばれるものがあり,例えばChatGPTでは3万字程度しか入力できません.前述したように,ChatGPTは毎回今までの会話を全て入力するのですが,この方式だと会話の文字数が3万を超えた段階で入力に入りきらず,新しい会話に区切る必要が出てきます.例えば,記憶能力を持つChatGPTのキャラクターなどを作りたい場合には,何らかの対応をしない限り,3万字程度の会話は記憶できず,圧縮,あるいは記憶消去などの対応をとる必要が出てきます.もう少し現実的な欠点では,ある組織が持つ社内文書やコードベースは多くの有益な情報を含み,丸ごと入力してChatGPTから有益な知見を引き出したいところですが,トークン制限の小ささからこれはまず不可能です.書籍の内容も入りきりません.LongNetのような圧倒的な数のトークンを入力できる手法は,まさにこれを解決する聖杯なのです.
2023年10月〜11月 マルチモーダルモデルの本格的な登場,AIエージェントの注目や動画生成AIの発展
2023年最終盤では,マルチモーダルモデルが本格的に表舞台に登場することになりました.以前から期待されていたGPT-4のマルチモーダル機能の公開,そして12月のGemini公開など,今後はマルチモーダルモデルが主流になっていくことを予感させるイベントがいくつもありました.
また,GPT-4の発表からだいぶ時間が経っていることもあり,「OpenAIが裏でやばいAIを作っているらしいぞ」と色々な噂が流れました.一番注目されたのはQ*というAIで,曰くそれは「強化学習のQ学習が使われたGPTベースのエージェントであり,もう汎用人工知能と言えるレベルに達しているらしい」とのこと.このQ*は結局謎のままで,現在は「そういやそんなものも話題になったなぁ」となっているのですが,とにかくこのような噂によって,生成AIxエージェントがさらに注目されるようになりました.この記事では書くのを忘れていたのですが,2023年の中盤くらいにはAutoGPTやAgentGPTなどといったAIエージェントが流行っており,期待はその時期からあったのものが再び盛り上がった感じです.
なお,既に「AIエージェント」という名前が定着しており,私の本でもAIエージェントという語を用いているところに恐縮ですが,私はこの「AIエージェント」という呼称があんまり好きではありません.まず前提として,私の専門は強化学習とマルチエージェントで,まさにAI分野におけるエージェントを主に扱うもので,私にとってエージェントは大変馴染み深い概念です.AI分野において「エージェント」は何を意味するのか.私の博士論文でも採用したスチュアート・ラッセルの有名な定義では,エージェントは「環境から何かを知覚し,環境に対して何らかの働きかけ(行動)を行う主体」とされています.さらに,同じラッセルが「AIとエージェントは同一視されることもある」と言っているように,一部では人工知能そのものと変わらない概念でもあります.よって,「AIエージェント」という呼称はほぼ同じ意味を持つものを二つ同時に並べているように見えて,ちょっと見栄えが悪いのです.うーんみが深い.最も,画像認識などのニューラルネットワークや翻訳モデルもAIのはずですが,これらをエージェントということは通常ありません.よって,もう少し範囲を限定すると,エージェントと呼ばれているAIは,一定の行動の自由が許された(行動の選択肢が多い)「環境」というものの存在が前提で,その中でニューラルネットワークなどの出力をもとに行動を選択しながらよしなに色々やってくれるもの,ということになります.これに従えば,AIとエージェントは割とスパッと分けられる概念の気がはしますし,並べて「AIエージェント」でも問題ないのでは・・・?とも思えます.いやしかし,今からでも「生成AIエージェント」や「LLMエージェント」などが標準になってはくれないものか.
話が逸れましたが,とりあえずエージェントが意味するものはわかっていただけたと思います.生成AIの文脈で出てくるAIエージェントとは,プロンプトで指示を出すと,そのプロンプトで指定された目的を達成するために,言語出力,ツールの使用などを自律的に実行しながら動いてくれる手法を指します.広義にはCahtGPTプラグインやCodeInterpreterなども該当します.現在の生成AIはそのままでは,言語出力ができるだけで,単体でそれ以上の何かができる訳ではないのですが,このAIエージェントはさらに外部ツールを使うなどして,人間の作業をほとんど実行できる訳です.確かに高性能なAIエージェントが実現すれば,それは汎用人工知能と呼んでもいいかもしれません.Q*はそれの親玉的な期待を持って噂されたのですが,これが本当に裏で開発されているのかどうかは今でも謎です.しかし,AIエージェントが今後の生成AI研究の中心になることは間違いなく,ChatGPT初期のようなブームを巻き起こすAIエージェントが出てくるのは時間の問題である気はします.ちなみにQ学習は強化学習界隈において大変基本的な概念で,ドラクエでいえばメラや薬草,ポケモンであれば体当たりや傷薬に相当するくらい,最初に学ぶものですが,これがQ*の件で突如話題になり,だいぶ不思議なことも結構起こりました.昔作ったQ学習の資料が500RTくらいされたり,マディアから「Q学習とはなんぞ?」という問い合わせがきたり,生成AI界隈の盛り上がりは恐ろしいものです.
11月後半〜12月くらいには,動画像生成AIの分野でも大きな発展がありました.静止画があれば,それをボーンなどを使って自由に動かすことができるとする Animate Anyoneの衝撃は特に大きく,研究者や開発者の枠を超えて一般人にも注目された結果,日本のSNSにおける「全体トレンド」でも上位に躍り出ました.
最近動画生成AI周りの発展が続いていますが,トドメとばかりに凄いのがでてきました.
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) November 30, 2023
アリババなどが発表したAnimate Anyoneでは,静止画を用意してボーンを動かせばそのキャラクターが動く映像が生成できるようです.
キャラクターの一貫性保持もほとんど完璧.https://t.co/KEtLw7A5Z8 pic.twitter.com/VUXJTzuxSL

そのほかにも,Magic Animateなど色んな手法の発表が続き,界隈は沸騰しました.なお,この時期にこの辺の分野で革新的な発表が続いた背景として,コンピュータビジョン分野のトップ国際会議CVPRの締切がこの周辺にあったのが大きいと思います.
先ほどマルチモーダルモデルの部分で触れましたが,この時期最大にして,2023年におけるGPT-4に次ぐ大きなイベントはGoogleによるGeminiの発表です.Geminiの開発は以前からGoogleが公式に発言しており,公開は年末から,ちょっと遅れるのではないかとされていました.「GPT-4を超える」,「最高性能のマルチモーダルモデルである」,「AlphaGoと合体した汎用人工知能である」など色々と噂が流れており,その公開は人工知能界隈にとって最大の関心の的でした.私の近くにいるGoogleの関係者から,Googleの内情については色々と聞いていたのですが(ただ,Geminiの技術そのものについてはもちろん全く教えてくれませんでした),Gemini開発にかけるGoogleの熱意は凄まじいもので,膨大な社内リソースをGemini開発に注いでいた様子があります.12月に発表されたGeminiの論文によるとGeminiはUltra,Pro,Nanoという3つのモデルが存在し,この時点での公開は中間性能のProのでした.Ultraが最大性能のモデルでNanoはスマホなどのエッジデバイスで機能する小型モデルということになります.特に論文上の評価では確かにUltraの性能はGPT-4に勝っているようにみえ,界隈の関心の中心はそれでした.最初に公開されたProも初期のChatGPT,GPT-3.5の強いモデルには勝っているという評価ではあったのですが・・・これは正直なところユーザー視点では怪しく,公開後には割と辛辣な評価が続きました.研究でも「Gemini Proの性能はGPT-3.5-turbo以下だ」というかなり定量的で詳細な分析が公開されており,初動が成功したかどうかは微妙なところです.個人的には,Geminiの強みはRAGとの組み合わせ,音声認識機能(未公開),OCRなどにあると思っています.
生成AI本執筆の難しさと,その難しさへの対応
ここまで,ChatGPT〜2023年終盤までの生成AIの展開を,長々と振り返ってきました.私はこの時期に生成AIの本を執筆することになったのですが,執筆しつつ「生成AIと書籍の相性は最悪」だと常々感じていました.これから生成AIの本の執筆をしようと検討している方のため,本の執筆がだいぶ遅くなった言い訳のため,この辺の難しさを書いてみようと思います.1つ目が特に重要なので長いです.それ以外はついでです.
生成AI技術の発展スピード
先ほどまで書いてきた生成AIの展開を読んでもらえればわかると思いますが,生成AIはたった一年の間で,かなり多くの革新的な手法・技術が登場しています.数ヶ月おきというレベルではなく,下手すれば数週間おき,ひどい時は数日で,分野の常識がひっくり返ることも起きています.これは生成AI分野に限った話でもありません.2012年に深層学習が登場して以降のAI分野は重要な論文が出るスピードが他の分野と比較しても著しく早く,「数ヶ月前の論文は古典」という,他の分野の常識からするとジョークとしか思えない言葉があります(これは流石に私も言い過ぎ感がありますが).私は深層学習登場以降に,東京大学大学院の研究室で人工知能を学び始めた身ですが,当時入ることを検討していた研究室の一つが,ホームページに「この分野をやるなら他の2倍か3倍は頑張って研究するという覚悟がないとやっていけない」「1ヶ月,1週間で技術革新が起きる」と書いており,戦慄しました.これを考慮しても生成AIの発展スピードは異常で,例えば2023年の3月などは,何か技術が出てきてすぐにその技術に手を出しても,既存技術ですごいものを開発しても,運が悪ければ数日後か数時間後には,時代遅れになっていたでしょう.研究ではなく,生成AIを使ったサービスの企業でも話は同様で,OpenAIが何かを発表するたびに「この発表でスタートアップがいくつか終わったのでは」と言われる始末です.
さて,生成AIの書籍を執筆する時には,この分野の発展スピードが最大の敵です.書籍というのは大変面倒くさいもので,初稿が終わってからも,校正,印刷を経て書店に売り出されるまでに数ヶ月を要します.生成AIを対象にして執筆するとどうなるか.先ほどの生成AIの展開を思いだせばわかると思うのですが,大体どのタイミングで書いても,数週間後には革新的な技術が登場して脱稿〜出版までのタイミングで生成AI界隈の潮流が大きく変化し,せっかく頑張って書いた内容の旨味が減ってしまうのです.例えばChatGPTが登場して張り切った今井がそのままの勢いで2022年の11月〜1月くらいの間で,2022年夏に登場したStableDiffusionなどの技術も併せて『生成AIはここがすごい』という本を執筆し,3月前半に出版されたとしましょう.しかし,3月に出てきたGPT-4の性能はChatGPTと比べても圧倒的に上で,それ以降はGPT-4の性能を基準に進んでいたこと,この頃には声の生成AIが著しい発展を見せていたこと,マルチモーダルモデルが注目されていたこと,生成AIが本格的にホワイトカラーの仕事に影響を与えることになったこと,これらは執筆の段階では起きていなかった事象でありながら,2023年の生成AIの展開では常識となっていた出来事であり,これについて触れていない本はあまり旨味がありません.これは私の執筆に関しても,最終的には運に任せるしかないという部分が多く,実際に後述するような脱稿から出版までの間の「想定外」がいくつかありました.「運に任せるしかないという部分が多く」と書いたように,運に頼らず回避できる要素もあります.「何が長期的に重要な技術(話題)で何がそうではないのか.また,ある技術が重要になってくるまでにはどれくらいかかるのか」をうまく判断することです.
先ほどの生成AIの展開でLongNetというトークン制限が10億を超える手法が出てきました.とても重要な技術に見えます.しかし,本の中では直接的には取り上げていません.また,トークン制限という話題自体,本の5章で「将来的にはものすごく大きくなるかもね」と小さく夢を語っているのみです.ところで,このLongNetの登場から半年以上たった現在,主要な言語生成AIのトークン制限はどれくらいなのでしょうか.7月には10億可能という手法が出ていたのだから今は15億?いや,流石に計算コストの問題があるので1億程度か.残念ながらどっちも掠ってすらいません.現在まともに利用されている言語生成AIのトークン制限は最大のものでも20万トークン程度です(Claude 2.x).比較的最近登場したGeminiなどはいまだに3万程度です.LongNetというすごい技術があったはずなのになぜなのか.このような話は別にトークン制限に限った話ではありません.私自身を含めて,Twitterでは大変重要そうな技術論文の情報を発信して/されていますが,その発表から数ヶ月経って本当に主要技術として使われている例は稀です.どれだけ凄そうな技術でも,それが本当に長期的に見て重要な技術になるかどうかは色々な条件に左右されるものであり,さらに長期的に重要な技術であってもそれが身を結ぶには多大な時間を要する,ということです.逆に言えば,「何が現在は重要な技術であるか」を見極められさえすれば,先ほど説明したような生成AIの激動の中でも,情報が古くならない有益な本を書くことができます.これは色々な基準があり私はそもそもそんなにこの能力が高くはないと思っているのですが,以下はその基準の一部に関する話です.
本の中ではTransformerや拡散モデルなどの技術に力を入れて解説しています.Transformerが提案されたのは2017年,拡散モデルの原型は2020年初頭くらいです.AI研究の感覚では「古典」と言われてもおかしくない時期の手法です.Transformerを超えるとされるモデルはHyenaやMambaなど最近いくつも提案されています.これらのモデルを使って大規模な言語生成AIを学習する組織があれば,生成AIの本を書いてから出版されるまでにTransformerに取って代わる可能性があったのではないか.Transformerの解説が意味をなくしてしまうのではないか.私はまずあり得ないと考えていました.これは別に私の眼力が優れていたというわけではなく,エンジニアリングやAI研究における常識・経験則から判断していました.
Adamという非常に有名なニューラルネットワークの最適化手法があります.これは2014年という,AI研究の感覚ではもはや古代と扱ってもいい時期に登場した手法なのですが,現在も非常に広く使われています.「Adamより性能が上だ!」と主張する手法が数十,下手すれば数百個は出ているにも関わらずです.これらの手法がAdamより上の手法であることを全て否定することはできません.実際に使ってみればいくつかの分野では良い性能なのだと思います.しかし,本当に重要なモデルの学習では大体Adamが使われているはずです.なぜか.これは単純に性能のお話ではなく,エンジニアリングの文脈でよく出てくる「枯れた技術」という概念に通ずる話です.
「枯れた技術」とは何だか響きが悪い言葉です.しかしこれは一般的にはエンジニアリングの世界で良い意味で使われており,Wikipediaの表現を借りると「広く使われることで信頼性が高くなった技術」を指します.この枯れた技術というのは,確かに最新技術と比べると派手なピーク性能は出ないかもしれませんが,メンテナンスの容易さ,トラブルが起きた時の対応,誰もが理解できる実装など非常に利点が多いものです.AIの研究でもこの「枯れた技術」の感覚が非常に重要になります.大規模なAIの学習というのは,散々強調したように莫大な計算資源と時間を要します.「ちょっと失敗しちゃった」のノリで何度もやり直せるものではありません.どれだけ性能が高い手法であろうと,実装が理解困難であったり,特殊な状況に対応できないものであったりするものを,AI開発のメインに据えることは大変怖いのです.
Adamの例のように,AI研究の中ではある種の「枯れた技術」となって,どれだけ重要な手法が登場しても相当期間継続して使われるものが多くあります.私は執筆の際に本に収録する対象としてまず選んだのはこれらの技術です.あるいは,まだ「枯れた技術」に相当するものが当該分野に存在せず,新しい手法が出てきたらすぐにそれが標準として使われそうな技術です.私は目はだいぶ節穴ですが,この判断基準は生成AIのようなものを対象とした技術書を書く場合に参考になるのではないかと思います.
生成AIという分野の広さ
ここで衝撃の告白をしますが,私は生成AIの専門家ではありません.
何でそんな奴が生成AIの本を書いているのか.補足すると,「私は(広い意味での)生成AIの専門家」であると主張する研究者はおそらく存在しません.狭い意味では,例えば昔から言語モデルを扱ってきた自然言語処理分野の人やGAN,VAEを扱ってきたコンピュータビジョンの分野の人,音声合成の分野の人は確かに生成AIの専門家です.ただ,研究者の枠を超えて一般の人が考えているような「言語も画像も音声もプログラムも3D構造も何でもできる生成AI」全体を全て専門とする方はおそらく存在しません.
生成AIは多くの分野にまたがっていることから,これの単なる活用ではなく
,学術的な観点も交えた本を書くとなると,全ての分野を横断する知識が必要です.多分これは一般的には難しいはずですが,私はなぜか書いています.私が本当にこれらの分野を極めたからなのか?そうではありません.
私自身は,ChatGPT登場以前までは強化学習という,一見生成とは全く異なる分野をやっていました.私がこの生成AIに強く関わることになったのはほとんど偶然で,①ChatGPTという生成AIブームのきっかけとなったAIの基幹技術が強化学習であったこと,②それを見た私がかなり初期の時点でChatGPTの包括的な資料を作成して多くの領域から解説を求められるようになってしまったこと,③松尾研究室という社会実装も含めてAIのほぼ全ての領域を扱う場で色んな分野の知識を得やすかったこと,などが理由です.
強化学習が専門だったのはある意味幸いで,この強化学習がChatGPT以降,様々な生成AIに適用されることになりました.必然,強化学習分野の人はそれらの分野の知識のアップデートを求められ,私もその波に乗っかりました.つまり,この本は,偶然にも生成AI全体の知識を広く浅く知ることになってしまった奴が少し調子に乗って書いた,ということになります.
ここまで書いておいてアレですが,「生成AIは広い分野にまたがっているので本の執筆は難しい」と言う問題に対して,ここでは根本的な問題解決を提示していない気がします・・・.
法的な議論
これについては,第三部の本の執筆の経過の部分で詳しく見ていくことになりますが,生成AIに関する法的な議論は大変激しいものです.あまりにも急速に技術が発展したため,「法が技術に追いついていない」とも言われています.これは一部に関しては私も同意します.間違いなく今後議論が進んで,何らかの規制などは出てくるでしょう.
これは本を執筆する場合には大変難しいところで,執筆しながらリアルタイムで,「この技術は規制されるかもしれない」,「この技術は一般的に受けが悪い」,「このAIに関して裁判が始まった」などと状況が目まぐるしく変わります.何かある技術を本に書いて,出版される頃には規制の対象になっていたという状況は避けたいものです.
私が心掛けたのは,とにかくまずは法律の基礎の基礎をお勉強することでした.控えめに言って当初の私は法律に詳しい方ではなく,とある企業の方との会食の最中,「著作権侵害というのは創作的な表現が類似していた場合に起こるのであって,事実を記述するのみでは,いくら同じ記述であったとしても侵害にならない」と聞いて「はえー,そうなんですね!」と感心するレベルでした.この程度の知識ではお話になりません.
1週間程度,例えば弁護士が公開した資料やTwitter上での議論,文化庁が公開している資料,そのほか著作権の有名なテキスト(例えば,[茶園成樹,『著作権法』]など)をざっと読むことになりました.生成AI界隈は,この後に見ていくように,もはや研究者,技術者だけの問題ではなくなっており,本を書くにしろ,開発するにしろ,思わぬところから弾が飛んできたり放火されます.生成AIの本を書くことになった人はもちろんのこと,生成AIの開発者もこの辺を勉強すると,後々力を発揮する心強いお守りになると思います.
本の執筆の経過
本の執筆前 ChatGPTの登場後の筆者の反応と行動
先ほども申し上げた通り,私の専門分野は強化学習であり,本来は画像や言語の生成を行うような研究分野とはあまり関係がありません.しかし,ChatGPT公開当日の OpenAIのブログに, ChatGPTの使用技術として強化学習の一種(人間からのフィードバックに基づく強化学習)が載っていたことから,技術的にも当事者となり,即座にChatGPTの技術詳細を調べ,その資料を東大松尾研内で共有,その後一般公開するに至りました.おそらく日本では最も早期に公開されたChatGPTの包括的な技術資料だと思われます.
上記の資料を公開した時点で,自身の専門と関係していることもあり,既に書籍のようなものの執筆を検討していた記憶があります.また,「『AIが書いたAIの教科書』的なものを書いたらバズりそう」などという,かなり雑な案もありました.(余談ですが,この「AIが書いた〜」みたいな本については,実際に『AIが書いたAIについての本』という書籍が出ています.)
2月くらいに,研究室関連で国会議員の方と話す機会があり,当時はChatGPTの技術的な説明をできる人間が少なかったこともあって,私が直接永田町に行って,国会議員にChatGPTの技術を説明することが決定しました.実際には日程の調整が結構難しかったこともあって,永田町訪問は4月になり,それに先行して発表されていたGPT-4の解説も合わせて行うことになりました.ボスの松尾先生はともかく,私のような下っ端が政治家のような大物相手に技術解説する機会が回ってくるのは,ChatGPT登場以前では考えられなかったことです.ChatGPT発表からまもないこの時期に「ChatGPTってやつを使えばなんでもできるんやろ」程度のフワッとした理解ではなく,中身の技術まで含めて詳細を理解しようとする動きが政府にあったことは特筆すべきことです.日本政府はこと生成AIに関しては,研究者視点で現在までほぼ完璧に近い対応をしてくれていますが,この時期には技術の可能性と限界の理解をほとんど終えていたことを考えると,それも当然という気がします.当日に出た質問はかなり本質をついたもので,例えば「今のインターネット上には,〇〇という概念と△△という概念が同時に記述されている文章は見当たらない.しかも意味もだいぶ違うはずだ.しかし,ChatGPTはこの概念同士の関係を適切に把握し,出力も既存文章にはないようなアイディアのように見える.これはなぜか.」というものがありました.実際のところ,ChatGPTのような大規模言語モデルが「文章の穴埋め問題」を大量に学習するだけでこれほど驚異的な性能になることは,現在でも研究者が「うーん,それは多分・・・」と微妙に歯切れの悪い返事を返事をしてしまうくらいには本質的な謎なのですが(本当にこれが自明であれば,OpenAIがChatGPTを出す前にGoogleなどの企業が圧倒的な予算でChatGPTのようなサービスを作っていたはずです),議員の方はこれくらいの疑問を持つ程度には技術に深い理解を示していました.
この時点で,日本においてはこれから政府が主導して生成AIの本格的な社会実装が行われていくという確信を持ちました.同時に,「研究者以外,それも技術にある程度敏感な政府や産業界のみならず,今後生成AIの波に巻き込まれていく一般の人にも生成AIの技術を説明できる本が欲しい.」という思いを強くしました.
「AIに関する本」の企画書と執筆決定まで
4月後半くらいに,出版社の人(最終的にこの本の担当編集になった方です)からAIに関する新書執筆の企画書が送られてきました.
本書は最終的に『生成AIで世界はこう変わる』というタイトルで出版されており,まさに生成AIど真ん中な内容ですが,実はこの企画書の段階では「生成AI」に関する本ではありませんでした.この当初の企画書の内容ですが,結構センシティブというか「確かに一般ウケ狙いならこうなるのかもなぁ・・・」となってしまうものでした.その衝撃の内容はこちらです.

当初のタイトルは『人間が人工知能のしもべになる日』です.もちろん,ChatGPTなどの生成AIが盛り上がっていることを前提としての「人工知能」に関する書籍ではあるのですが,生成AIに焦点を当てたのものではなく,ChatGPT以前から市場には溢れていたAI解説・脅威論的な内容です.例えば,この時点での内容の案は以下の通りです.

生成AI以前に,従来の識別モデルなどの基本的な話題や,それは昔から結構あるのでは・・・?という応用例をとりあえず解説するといったトピックが多いことがわかるでしょう.この企画書の内容をそのまま書けという話だったら断っていたと思います.
しかし,とりあえず「AIの本を書いてくれという依頼が出版社から来ている」という状況が起こっているのはチャンスと見ました.テーマが少しずれてもAIという括りで一緒であれば,こちらからの要望もある程度反映してくれそうと思い,早速「生成AIの技術に特化した本にできませんか?」と,持ちかけてみました.その後MTGで直接やりとりをし,とりあえず「生成AIにテーマを絞る」ことと,こちらから章立て案を送り,最終的に向こうの会議
で決定することを合意しました.
教訓:
本の企画が出版社からやってきた人は,自分が書きたいテーマと違っていても,説得のチャンスは大いにある.
しかしながら,この「生成AIの技術に特化した本」という案もそのまま通ったわけではありませんでした.既に本を読んでいただいた方はわかるように,この本は生成AIの技術解説書などではなく,生成AIの影響と技術を一般向けに解説する本です.例えば3章の「労働と生成AI」や4章の「創作と生成AI」のような内容は明らかに技術解説だけでは完結せず,どちらかというと経済学や芸術・文化的な側面が強い内容です.
私が当初考えた章立ての案は,あまりにも技術に特化しすぎており,編集の方から「技術に関する内容は1つの章にまとめる」,「本の骨組みは未来予測にする」という返事が返ってきました.「生成AIをテーマにした本を書く」というところまでは漕ぎ着けたのですが,ここからが1番の悩みどころでした.私はあくまで技術の研究者であり,例えば労働の未来予測,現在大きな議論になっている文化芸術の方にまで意見を表明すべきでないという考えがあったためです.個人的には「このままAIが進化を続けるとどうなるか」という話題は大変好きなものではあるのですが,私の普段のこれは少し未来方向の線が長すぎるのと,経済や文化といった身近な話題とは少しずれた知能論的なものです.何より,先ほどあげた12月公開のChatGPTの資料をそのまま書籍化すれば執筆がすぐに終わるというのもありました.
ここからメールでのやりとりが一旦止まって,しばらく思索に耽ることになります.とりあえず,執筆の材料になりそうな論文を漁ってみたのですが,よくよく見ると,AIの研究者が書いた技術以外の未来予測的な論文は多く存在していました.例えば,新しいものだと本でも取り上げた有名な「GPTs are GPTs」論文.これはChatGPTのような言語生成AIが電気やトランジスタのような「汎用技術(GPT, General Purpose Technology)である」とした上で,労働に与える影響を論じたものですが,著者はOpenAIなどのAI研究者です.そのほかにも,ChatGPTの強化学習における「アライメント」などは技術というよりは,人間とAIが共生する上での価値観の問題を論じていますし,「汎用人工知能とは何で,これが実現したら何が起こるのか」という話はこの頃には頻繁に研究者が頻繁にしていました.部屋に置いてあった『人工知能大事典』という人工知能に関する話題が網羅されている超絶鈍器を開いてみると,最初の100ページ以上はほとんど「哲学」や「労働」の話をしており,後半では文化芸術・創作について50ページ以上を割いています.そして私がAIを本格的に学んだ最初の本にして,師の代表作『人工知能は人間を超えるか』を読んでみると,技術の話以外にも,大変興味深い思想や社会実装の議論が大量に出てきます.ここに至って,「AI研究者,昔から技術以外のこと語りまくっているじゃないか.これは自分もやっていいのでは」などと謎の自信が出てきました.また,生成AIブームによって,人工知能研究は研究者ごとではなく人類ごとになり,これからの研究者は直近でAIによって発生する事象に説明と対応の責任が求められるようになるだろうとも思っていました.当時の私は控えめに言ってもそれができる領域に達しているとは言い難く,本の執筆を機にこの辺の修行するのも良さそうだ,こう考えた記憶もあります.
生成AIの技術を中心に書くということについては,他にも以下のような現実的な懸念がありました.
まず,前述のように,生成AI技術の進展が早すぎて,脱稿と出版までのタイムラグで内容が陳腐化する恐れがありました.これは技術の記述を控えめにしたところで,完全に回避できる問題でもないのですが(当然技術が新しくなれば,その未来への影響も変わる),未来への影響は技術の変更により「程度」が変わるのみでその影響の大枠は固定されるのに対し,技術の場合は過去の技術を解説することの意味がどれだけ残るのか不明です.
第2に,そもそも技術解説の本は版元が対象にしている一般層には大変ウケが悪いという事実です.本書はIT技術のコーナーに並ぶような技術書ではなく,SBクリエイティブという一般層を対象にした版元から出る新書です.
これは出版社側からも「無味乾燥な技術の話題は・・・」などと,かなり強い表現で牽制されました.
以上のことを考慮し,編集と章立て案を練り直しました.以下が版元の会議を通過した時の案になります.

各章のタイトルは微妙に変わっている部分もありますが,この時に決定した構成から脱稿まで,大きいズレは発生しませんでした.
この構成決定時のメールで編集から以下のアドバイスをもらいました.研究者(あるいはエンジニアなどの技術者)が書く一般書にのみ適用される,だいぶ限定的なアドバイスですが,この記事を読んでいる人の多くはそれに該当しそうなので丸ごと引用します.
「読者にとって、学術書寄りの難解な本は、硬い石を使いづらいナイフとフォークで食べようとする行為に近い」
今まで専門書しか書いたことがなかった研究者にとっては,大変刺さるお言葉です.この表現があんまりにもしっくりきたので,執筆中は常に文章が「硬い石」になっていないことを意識しました.本が出版されてから,内容はともかく妙に文体や文のわかりやすさを賞賛されることが多かったのですが,最初のこのアドバイスの影響が大きかったように思います.
何はともあれ,こうして初の単著にして初の「一般書」の執筆が始まりました.
執筆開始から1,2章まで
『生成AIで世界はこう変わる』は2024年の1月7日に発売されました.先ほどの構成決定のメールを受け取ったのは5月末日です.
では,当初の執筆スケジュールはどうだったのか.以下が当初想定されていた執筆スケジュールでした.
6月前半:第1章初稿,編集からのフィードバック
6月中盤〜6月後半:2章,3章,4章,5章の執筆,フィードバック,初稿脱稿(!?)
7月前半:再校完全脱稿(!?)
9月:刊行(!!?)
なお,本全体の文字数は大体7~8万字で,最大10万字程度です.
今考えてもだいぶ無理があるスケジュールです.流石にこれはということで,編集とMTGを行い,11月刊行ということで話がまとまりました.これでも,脱稿は7月末ということでハードスケジュールです.ちなみに1章の初稿が完成したのは6月23日くらいでした.この時期には既に生成AIブームが本格化しており,本業以外で外部の予定が大量に降ってきたこともあって,執筆前半から苦しい展開になりました.
・・・なのですが,実は7月前半くらいには,もう5万字,ちょっと頑張ればすぐに7万字程度になりそうな勢いで原稿が出来上がっていたのです.素晴らしい!!余裕で11月出版に間に合いそうです.が,そうはなりませんでした.では,この素晴らしい原稿はどこに行ったのか.実は,この時点で1章に先行して「書きやすいから」という理由で2章の「生成AIの技術」について執筆を進めていたのですが,これが研究者のノリで筆が進みすぎてしまい,ノリノリのイケイケのワクワクで思いついたことを詰めていった結果,2章だけでとんでもない文字数の原稿ができてしまいました.言語生成AIだけで3万字,画像と音声で1万字ずつくらいです.しかも,マルチモーダルやエージェント,RAGなどの発展・周辺技術も含めればまだまだモリモリ書ける.あとは3章と4章,5章をちょろっと付け足せばあっという間に脱稿です.しかし悲しいかな,2章の指定文字数は全体で最も少なく,1万5千字程度ということに気づきました.素晴らしい原稿ができたと思った喜びも束の間,むしろこれをどうやって圧縮するかの作業に頭を悩ませることになりました.最終的には言語生成AIだけで1万3千字くらいにまで削り,「すいません,やっぱり2章はちょっと長く書かせてほしい」とお願いしつつ,原稿を共有しました.圧縮したことでもう一つ難しかったのは,前述したように「何が重要で何が重要でない技術なのか」の選定基準がよりキツくなってしまったことです.言語モデルやTransformer,拡散モデルなどは確定として,それ以外の技術や理論に関してはかなり厳しい基準で選ぶことになってしまいました.校正の途中ではスケーリング則やプロンプトエンジニアリングすら削除の対象として検討されるすらありました.松尾研の周辺には GoogleやOpenAIの事情に詳しい,あるいは現在も関係を持っている人が複数いますが,それらの方やTwitterの事情通らしき人から断片的に聞こえてきたのは,1. 総合的に考えると年末から年始にかけて出てくる生成AIの技術で最大のものはGeminiでありそれ以上の技術は登場しなさそう,2. GeminiはTransformerベースのマルチモーダルモデルでありBardに統合される,3. OpenAIは最近エージェント技術に注目している,というものです.1と2に関して,本の執筆時点で裏で進んでいる生成AI技術プロジェクトの中でGeminiを超えるものはないと判断し,考えられる限りのGeminiの最高性能と,使用技術を盛り込めば足りると判断しました.つまり,Transformer,言語モデル,マルチモーダルモデル,検索機能のRAG,プロンプトエンジニアリング,スケーリング則などです.そして3に関しては正直なところ確度はイマイチだったのですが,既にChatGPTに搭載されているプラグインやCode Interpreterがエージェント技術に関連すること,AutoGPTなどの生成AIエージェントが人気だったこと,何より私自身の専門の一つが「マルチエージェント」だったことを踏まえ,最終的に記述する技術を厳選しました.結果的に,この本の告知日に発表されることとなったGeminiの性能を踏まえと,これは大体正しい判断でした.
なお,この2章の原稿については,手元に圧縮前のものが残っており,削った内容のいくつかは現在でも通用する内容が書いてあるので,機会があれば「未公開原稿」ということで公開しようと思います.
3章の執筆
色々と大変さを強調しているところですが,3章の「労働・暮らしと生成AI」に関する話題は,割とすんなり書けました(それでも,編集が求めるスピードには達していなかったのですが).「労働とAI」,「AIに仕事を奪われる」という議論は,昔からAI,経済学の分野で繰り返し話題にされていたものであり,資料も多かったのです.いわゆる「オズボーン論文」とも呼ばれる,深層学習登場直後に出てきた超有名論文『雇用の未来』の存在や,それとはほとんど結果がひっくり返ったOpenAIなどが言語生成AIによる仕事への影響を論じた『GPTs are GPTs』論文の存在など,一般層が好きそうな話題には事欠きません.他にも,AIにできる作業の難易度を端的に表す「ポランニーのパラドックス」,「モラベックのパラドックス」の存在など,アイディアはいくらでも転がっていました.とは言え,読者が気になるであろう「で,生成AIは結局我々の仕事を奪うの?奪わないの?」,「どれくらい経済に影響を与えるのか?」という問題にズバッと結論を出すのは難しいところでした.この話題に限った話ではありませんが,研究において,外の視点から見てわかりやすい「AなのかBなのか」という大雑把な問題に対して「Aである」と結論を出せる場面はほとんどありません.研究者が普段取り組んでいる問題は,個々の例を見れば地味で泥臭いものです.そこから導かれる結論も「〇〇という条件で,△△という手法を組み合わせるならA,それ以外にはBになるが,Cという状況が発生することもある.その理由はおそらく・・・」などと,いくつかの前提や条件分岐(この前提や条件分岐の切り出しがうまいものが良い研究です)を考慮したもので,研究分野の外から見て,その意義を判断することが難しいものも多くあります.
なんなら,研究者同士であっても,その条件と導かれた結論が良いものなのかどうか判断するのは難しく,史上有名なAIの手法が当初は査読で落とされた話題という話題も多く存在します.しかし,基本的にはこれらの研究が積み重なって,最終的に大きな問題に対する結論が出てきます.残念なことに生成AIはあまりにも急にブームになったせいで,この辺りを決定づける研究が揃っていません.そもそも問題の性質的に歴史的な評価を待つしかないという側面もありそうです.強いて言えば「AIを使いこなす人に,AIを使わない人が仕事を奪われる」というのは概ね事実であるように思います.
4章の執筆と苦難
3章の執筆が終わって,4章の執筆に取り掛かることになったのですが,これが一番キツかったです.執筆に一番時間がかかったのもここで,初稿までに1ヶ月丸ごと使っています.校正の段階でも,前半丸ごと書き換えるくらいの修正要望をしたり,ものすごく細かい表現までチェックしました.4章の主題を変える,あるいは4章丸ごと無くして2章と3章の内容を増やすというという方向すら考えていました.
なぜ,ここまで4章の執筆だけは慎重になったのか.4章の章題は,「AIが問い直す「創作」の価値」です.これは,普段あまりTwitterなどで活動していない人には伝わりにくいかもしれませんが,Twitter上では特にイラストレーターの方から,生成AIに対して広く反対の運動が起きています.
この辺については最近,Twitterユーザーの職業を分けて,各職業の集団が生成AIに対してどのような感情を持っているのか分析した論文が出ています.あまりピンとこない人のためにこの論文を利用して解説します.この論文はかなり面白いので,少し本記事の流れを切ってしまう形にはなりますが,長めに説明してみます.
この論文では,生成AI全般(ALL),言語生成AIの中でもChatGPTのような対話型AI,画像生成AI(Image),Copilotなどのコード生成やGPT-4・3.5などの言語モデルそのもの(Code and Model)等に関するツイートを各職業ごとに収集,そのツイートがポジティブなものか,ネガティブなものかを分析しています.そして,その職業の生成AIに対する感情と,生成AI以外の普段のツイート全般の感情を比較し,特に生成AIに対してどう考えている傾向があるのか分析しています.論文中では様々な実験結果が示されていますが,以下の図が一番わかりやすいでしょう.

簡単に図の見方を解説すると,横軸は生成AI以外も含むその職業のツイート全体からランダムサンプリングした感情を,縦軸は生成AIに関するツイートの感情を示しています.横軸の右にプロットされている職業は,大体普段からポジティブなツイートをしており,左の方にある職業は普段からローテンション気味と言ったところです.縦軸の上にプロットされている職業は生成AIに対してポジティブなツイートをしており,下の方にある職業は否定的ということになります.赤線は横軸の値と縦軸の値が一致している部分なので,この赤線より上の方にある職業は「特に生成AIに関しては好意的な反応をしている職業」,下の方にある職業は「特に生成AIに関しては否定的な反応をしている職業」になります.まず全体的な傾向ですが,生成AIに対してはほとんどの職業で好意的です.研究者やソフトウェア開発に関わる人間以外も含めてです.「AIに仕事が奪われるかもしれない」という話題は特に最近よく耳にするところですが,少なくとも現時点では,AIのあまりにも急速な発展に驚いて,超高性能なおもちゃとして捉えている人が多いのかもしれません.実際,Twitterやメディアでは「ChatGPTがこんなに面白い出力をしてきたwww」のようなツイートが,様々な属性のユーザーからみられます.面白いのは法律家の反応で,普段はローテンションなツイートながら,生成AIに関してはかなり好意的になっています.「生成AIは法律的に問題があり否定されるべき」という声が特定集団のユーザーから発せられていますが,当の法律家は事態を冷静に見て,むしろ使いこなす方向で議論しているようです.
一方で図を見れば一目でわかるように,全職種の中でイラストレータだけは生成AIに対して特異的に否定的な感情を示しています.これは全体的に見てもかなり特殊な反応で,いわゆる「アーティスト」として広くまとめられた職業ですら,全体的に見れば(a)のように好意的になっている中,イラストレータはほぼ孤立して否定的な感情を示しています.
生成AIに関する話題を数日追えばわかると思いますが,特にイラストレータの方を中心とする,生成AIへの反対運動は凄まじいものです,むしろ生成AIに関する炎上が起きていない日の方が少ないレベルです.クリスタやアイビスペイントなど,いくつかのペイントツールが生成AI機能を追加した時には,いずれもイラストレータを中心としたユーザーの反対運動により撤回に追い込まれています.また,有名人が生成AIを使えば引用RTで批判が行われ,AI研究者と法律家,政府に対して毎日バッシングの声が上がっています.このような状況で,文化芸術・創作と生成AIに関してAI研究者の側が意見表明を行うのは,自殺行為に等しいと考えていました.
例えば,その8月前半に,執筆の材料を集めようと思ってした資料募集ツイートが以下です.
・いらすとやの登場による絵師の仕事の経済的損失の定量的分析
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) August 7, 2023
・シンセサイザー,デジタルペイントツール,ワープロ等,文化芸術コンテンツ作成に関わる技術が登場した時のクリエイターの生の反応
この辺詳しい資料ってあるのでしょうか
「AIと創作」みたいな文章を書いていて参考にしたいのですが…
このツイートが生成AIに反対するユーザーに拡散され,プチ炎上を起こしました.その意見をまとめると,「なぜAIと創作が共存するのが前提なのか」,「生成AIはそれらのツールとは違い,比較することがおかしい」といったものです.このツイート自体は,客観的に見ても特定のコミュニティに対して否定的な発言を行うものではなかったと考えており,実際多くの方が資料提供をしてくれました(その中にレジェンド漫画家も含まれており,交流が始まったのはびっくりしました).このツイートを行う前後に,あるAI関連の機関の人から「最近うちに怪文書見たいのが届きまして.AI開発をやめろとかなんとか言っているんだが.」みたいな会話があったのですが,この時期には生成AIに反対するコミュニティの運動がかなり大きく過激なものになっていたようです.そして,このツイートを境に,現在まで私の元には継続的に怪文書が届くようになりました.「AI開発を続ければ永遠に罪を背負うことになる」,「計算機を神にするな」と言った具合です.4章の執筆はこのような状況の中で行われました.
4章(と5章の一部)の執筆にあたって,私がとったスタンスは次のようなものです.
・イラストレータたちが現在の状況に不快感を示し,反対の声を上げるのはむしろ妥当な反応である(本の最後にも書きましたが,むしろ現在声を上げた人によってAIと人間の良い共生関係が築かれるとも考えています).
・生成AIは単なるツールで,それを使うかどうかはクリエイターの判断であり,押し付けるべきではない.ただし,研究者の視点から生成AIを使ってできることの可能性や実例は示す.
・自分はAIによって生成されたイラストが基本的にはあまり好きではなく,同じ声をあげる人も多い.この現象は興味深く,この辺りの反応を実際の研究によって説明できれば,クリエイターにとっても意義がありそう
・生成AI登場によって開かれる可能性のある創作の可能性,生成AIの登場によって敷居が低くなったことで創作への一歩を踏み出した人々や,従来の創作に生成AIを組み込んで新しい領域を目指す人を否定すべきではない,
Twitterではたびたび触れていますが,私は元々学問とはあまり縁がない人間で,ポケモンなどのゲームの大会プレイヤーでした(「でした」と言うのはあまり妥当ではなく,大会にこそ出れなくなったもののゲームは継続しています).同時に,ゲームに関連した二次創作作品なども好きで,むしろ研究者というよりは向こうの界隈に共感することも多くあります.4章に微妙に滲みている,少し研究者らしくないお気持ち(これは反省ですが,他の章と比べ主観的な表現が多いです)は,その辺を反映しています.
初稿が終わった後も,書き直し,細かい表現のチェック,一部の削除など,とにかく4章の執筆は大変でした.
喜びの5章執筆
5章の執筆は(一部を除いて)大変楽しかったところです.4章の執筆終了は8月後半ですが,5章は9月6日くらいには終わっていました.AIによって長期的な視点で社会がどう変わりそうか,AIは今後どのように発展するか,人間とAIの知能の関係など,私の考えをぶちまけました.この中で,一つだけ慎重になって書いたトピックがあります.現在の生成AIと著作権に関する問題です.これはまさに現在進行形で議論が続いているところで,最終的にどう転ぶかわからない部分もありました.一方で,生成AIによってこの問題に関する関心が高まっており,本の読者層にも興味を持つ人が多そうなこと,AIに関する議論が激化しすぎてそもそも著作権の基本的な考えについて誤解が広まっていることなどの事情を考えると,AIの研究者が本当に基本的な考え方を述べておくことは意義があると判断し,執筆に至りました.特に法律が技術に与える影響について,現行のAIサービスの仕組みを知っている技術者の視点から論じた資料はおそらく少数で,この辺の技術者・研究者だからこそ書ける内容には力を入れています.「法律によってAIによる学習は何でも合法だ」とするAI擁護側の意見,「無断学習を禁止すれば全てうまくいく」とするAI規制側の意見など,ネット上では極端な意見が目立ちますが,著作権の基本的な考え方や現在のインターネット上の基本的なサービスの性質(翻訳AI,検索,文字起こしなど)を考慮すると,議論はかなり複雑で,一筋縄ではいかないものです.この部分の記述は私だけの判断で妥当性を判断するのは不可能だと思い,最終的に弁護士の方に監修を頼んでいます.
図の作成,校正
実は文章の執筆の段階では,図をほとんど入れていませんでした.文章を書き終わってから,後世と同時に気合いを入れて図を作り始めたのですが,実際に本に掲載された図は一部です.掲載されなかった図は本以外の講演などで供養することになりました.
初稿が書き終わったのが,9月前半です.何とか11月刊行はいけそうか・・・と思ったのですが,私は校正という作業をなめていました.赤字が入った原稿が帰ってきて,それを全て確認して返す・・・という作業がひたすら繰り返されます.特に本書は議論が激しい生成AIを主題にしていることから誤った記述は許されません.全体的な校正が完了してゲラが返ってきても,念校など,ひたすら本の全体を隈なくチェックして返す作業が繰り返されます.この段階で怖かったのは,生成AI界隈の大きなイベントです.既に原稿がほとんど仕上がっている以上,もし生成AIの技術に大きな変更があったとしても,記述変更が困難です.この段階になると,何か追加したい内容があったとしても分量にして1ページ程度に収まる程度のものしか反映できません.
11月前半には,OpenAIの DevDayの発表などがあり,もしかしたら本の内容に大きな変更がありそうかと注視していたのですが,あくまでサービスの発表で生成AIの技術自体に革新があったわけではなく,記述に変更はありませんでした.GoogleのGeminiは年末発表とされており,時期的に原稿が私の手を離れていて対応のしようがないので,一応Geminiが最大限にすごいことをやってきても耐えうる記述を2章と5章にしました.
脱稿に向けて順調に進んでいると思っている中,生成AI界隈だけでなく世界を揺るがした例の事件が起こりました.
OpenAI CEOのアルトマン解任騒動です.
この騒動が起こったのが日本時間で11月18日ごろ.私の作業は念校チェックに差し掛かっており,確認期間も1日程度.もう基本的に記述の変更は致命的なミスを除いてできない段階です.
この騒動により,本に書かれている生成AIの中心企業であるOpenAIという企業が消滅する,最悪の場合には生成AIブームの主人公ChatGPTのサービス停止が考えられる状況になりました.本の中で何度も取り上げている核が翌日にはこの世から消えている可能性が,よりにもよって執筆最終盤に起きたことで,私の精神もだいぶアレになっていたと記憶しています.本当に最悪の状況が発生しても原稿に可能な限り反映して被害を最小限に食い止められるよう,騒動時には起きている時間のほぼ全てをOpenAIとアルトマンの情報を追うことに使っていました.当時は所用で東京を離れていて,少しリラックスできる時間のはずだったのですが,心の中では完全に臨戦状態でした.当時の私のツイートを見ると,ほとんど日本におけるアルトマン解任騒動の広報官と化しています.間違いなく,日本で一番騒動の情報を追っていた人間だったと思います.幸運なことに,アルトマン解任騒動は無事にアルトマンがOpenAIに戻るというハッピーエンドを迎え,私の原稿もハッピーエンドの脱稿,あとは印刷所に入って出版を待つだけの状況になりました.
少し順番が前後しますが,校正の段階で本の「帯」の文言を考える作業も進んでいました.帯の文言に関しては,出版後にも一部の知り合いや研究者の人から意見があったので,ここでその決定過程を取り上げます.
まず前提ですが,本書は研究者や技術者ではない,一般向けの本です.かつ,出版社による刊行である以上は,その成果は純粋に金銭的な売上によって測られます.帯は一般層に対して売上を最適化するように決定されるわけですが,これが研究者の考えとは致命的に相性が悪いのです.
執筆過程で,私と編集の「衝突」があったとすればこの部分です.まず最初に編集の本から「こんな感じの帯でいいか」という提案が来たのですが,これは全てNGにしました.具体的な内容は書けませんが,あまりにも不安を煽るもので,本の内容をかなり強引に解釈すればそのような文言を引き出せる可能性はあるものの,それは私の思想とも相反するものだったからです.そこで,私の方からかなり長文の返信を行い,文言の決定に関する研究者としての基本的な考え方と,10個程度の案を出しました.しかし,これについても編集からは反対があり,もう一歩踏み込んだ内容にできないかという打診がありました.そして,これも一部は私の方でNGを出しました.ただ,時間的な問題もあり,最終的には私の方が折れ,向こうの提案の一部を骨組みに,本の内容と決定と矛盾しないように配慮しつつ,最終的な文言が完成しました.
これが正しかったのかどうかは今も判断がつきかねています.少なくとも研究者界隈からは,この帯の評判が良かったとは言い難く,一部の人には私の方から事情を説明させていただきました.ただ,研究者の視点からは残念なことにこの帯のフレーズは一般層からは実際にウケが良かったようです.研究者以外の人と私の本について話す機会が何度かあったのですが,「帯の文言が目を引いた」という声が多かったのです.何なら,生成AIに否定的な立場の方からすら「この文言を見て気になった」という意見もいただきました.
ちなみに本の最終的なタイトルについても,執筆の最終盤になってようやく確定しました.私の方の案では『世界を変える生成AI』や,師の著書『人工知能は人間を超えるか』の表現を継ぐ形で『生成AIは世界を変えるか』というものがありました.最終的には編集での会議を経て『生成AIで世界はこう変わる』に決定しましたが,タイトルの決定というのは出版社の意思が反映されるところが大きく著者の意思が反映されるとされる中,ほとんど私の案をそのまま採用する形になったのはびっくりでした.これは実際にかなり稀な出来事らしく,私の編集者も「私の担当では初めてです」と言っていました.
一方で,既にいくつかツッコミをもらっているのですが,この本は研究者視点で理性的に語りすぎたが故に「こう変わる!!」と断言している部分は非常に少ないのです.私が『世界を変える生成AI』という案を出しているのは,「生成AIで世界が変わることは間違いないものの,最終的な形まではわからない」という意図があったのですが,「こう変わる」というタイトルになったことで,私が完全な未来予測をしている雰囲気が出てしまいました.
教訓:
一般書を書く場合には,一般層への売上の最大化を目的に決定される部分が多くあり,研究者の思想とは相反する場面が発生する
5章が仕上がった段階で9月の前半,この時点で11月の出版も日程的に不可能ということになり,刊行は1月に伸びました.
『生成AIで世界はこう変わる』出版の告知〜出版まで
11月後半に原稿が私の手を離れた後も,帯の文言やカバーデザインの決定などが微妙に遅れており,本の発表は12月にまでずれ込みました.私が生成AIに関する本を書いていることは,松尾研究室のメンバーや家族,外部イベントでの対談相手などには伝えていましたが,Twitterでは「なんか書いている」程度のことをたまに呟く程度で,大々的に告知するのはこれが初めてでした.自身初の単著だったこともあり,「この告知の反響で売上が決まる」と大いに気合を入れて,万全の準備で告知は行いました.とにかく,告知のツイートに界隈の注意を向けたかったので,当日の午後には以下のようなツイートをしてみました.
【お知らせ】
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) December 6, 2023
本日の19時頃に,生成AIに関して半年くらいかけてやってきたことに関する重要告知を行います.
拡散・反応いただければ幸いです.
これは後日聞いた話ですが,界隈の人はこれをみて「松尾研がなんかすげぇ生成AIサービスでも発表するのか」と思ったそうです.とはいえ,界隈の注意を向けるという目的に関して言えばこれは大成功で,このツイート自体が40万インプレッション稼ぐというまさかの事態になりました.
その後,当日の午後,告知ツイートの3時間前くらいからは告知ツイート本体の内容を考えることに集中していました.長年Twitterをやってきた経験則を全て詰め込んで考えた渾身の告知ツイートが以下です.
【重要告知】生成AIの本を出版します!
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) December 6, 2023
"生成AIで世界はこう変わる"
https://t.co/SRqzzLpfZz
東大での活動で得たChatGPT等の言語モデル,拡散モデル,マルチモーダル,エージェント,活用,労働/文化の影響の全知見を載せました!
更に,師であり政府AI戦略会議座長の松尾豊教授との「師弟対談」も収録!… pic.twitter.com/0OFxals17o
この告知は結果的に大成功でした.
当日のAmazonランキングでは,この本の登録カテゴリーほぼ全て(唯一「新書」カテゴリーでは,なぜか新書に居座るフリーレンに負けました)において,この本の物理版と電子版で1位と2位を独占,本全体カテゴリーにおいても9位にまで浮上しました(ちなみに,本書は物理版と電子版で集計が独立しているのですが,これがなく単体の集計で合算していれば天下を取れたのではないかと今でも思っています).

告知のツイートに関しても凄まじい勢いで拡散され,インプレッションは当日で100万超え,界隈の多くの人からコメントをいただきました.
余談ですが,この私の出版の告知ツイートのパターンがあんまりにも成功しすぎたせいで,その後の技術書を発表する方達の中で一種のテンプレとして再利用されることになりました.これは私もみていて面白かったです.どんどん使ってください.
告知から発売までの時間には個人的な「想定外」が2つありました.
まず,1つ目は告知の日と実質的に同日(日本時間だと告知の翌日)に「GPT-4を超える」という噂すらあるGoogleのマルチモーダルモデル「Gemini」が公開されたことです.これはGeminiの採用している技術や性能によっては告知日に一発ゲームオーバーすら考えられる緊急事態だったのですが,これは過去の自分を褒めるべきか,Geminiの技術や到達点については本に書いたものとほぼ一致しており,特に本のダメージとはなりませんでした.むしろGeminiの出現によって生成AI界隈がさらに盛り上がり,本の売上に寄与してくれた気すらします.
2つ目は,音楽生成AIのSunoAIが,AIや音楽関係者のみならず,一般人も含めて広く話題となり,ChatGPTや画像生成AIレベルで当たり前に使われる技術になったことです.SunoAIのメイン機能は,テキストで歌詞を入力,曲の属性などをプロンプトで指定すると,伴奏と歌唱を生成し,プロの音楽家と同レベルっぽい(「ぽい」と言っているのは,正直現時点ではまだまだプロの音楽家に匹敵するレベルではないと私が考えているためです.)曲を生成してくれます.この「歌詞を入力するだけ」で,外見上は高クオリティの曲が生成できるという手軽さもあって,一般ユーザーからも広く支持を集めたようです.しかし,これが12月の時点でここまで広く流行することは私にとってはかなり意外でした.また,このSunoAIの流行が発生すること自体が想定外だったのですが,SunoAIの流行の中身に関してもいわば「サブ想定外」がありました.
まず,SunoAIのような音楽生成AIが流行することが想定外だったという話についてです.そもそもSunoAIが表世界に出てきたのはこれが初ではありませんでした.正確な日付は覚えていませんが,この12月のSunoAI流行の数ヶ月前,とある有名なボカロPがSunoAIを使い,それをきっかけに一般的な注目を集めたことがありました.この時点で既にSunoAIはそれなりのレベルに達しており,流行なるか・・・と思っていたのですが,この話題は特に長続きせず,後続して使うユーザーもそんなにいませんでした.当時の時点でまぁまぁ手軽に利用でき,生成される音楽のクオリティも後の12月の流行時とそんなに変わらない領域に達していたにも関わらずです.音楽界隈でも特に大きな話題にはなってなかったと記憶しています.少なくとも私が記憶している限りでは,この時点から12月までにSunoAIに劇的なアップデートが入った様子はなく,もっと前の時点で流行らなかったのであれば,今更流行るわけがないと考えていました.もう少し背景を書くと,音楽の生成AIは,Stability.aiによるStableAudioや,Metaが発表したAudioCraftのように2023年中にもそれなりに多くのモデルが発表されていたのです.性能もなかなかでした.しかもユーザーがローカルで気軽に試せるオープンなモデルが多くあり,これらの条件だけ見れば音楽生成AIが流行る土壌は2023年12月以前の段階で十分にあったと言えます.最も,SunoAI以外のモデルはプロンプトが少々厄介でした.実物を見てみましょう.以下はMetaのAudioCraftの一部「MusicGen」のデモページで実際に紹介されているプロンプトです.
reggaeton track, with a booming 808 kick, synth melodies layered with Latin percussion elements, uplifting and energizing
さて,皆さんはこのようなプロンプトを自在に入力して,いい感じの音楽を生成できる自信はあるでしょうか.音楽関係者にとっては簡単かもしれませんが,普通の人はどうか.少なくとも,義務教育の音楽の授業で習う知識だけだと,このプロンプトを書くには知識が足りない気がします.実際にはもうちょっと簡単なプロンプトでもそれっぽい曲は出せますが,とにかく,音楽のほとんどの生成AIは,確かにプロンプトを入れれば生成できるとはいえ,プロンプトを書くのにそれなりの知識が求められるものがほとんどでした.ChatGPTが,普段の日常的な自然言語の文章や疑問を素直に入力すれば,かなり有益な出力を,画像生成AIが適当に絵に欲しい概念を数個入力するだけで高クオリティな画像を出力してくれるのとは対象的です.ともあれ,音楽生成AIは,既存のものはちょっと扱いが難しい,かと言ってそれより遥かなSunoAIが出てきても以前は流行らなかった,これらの背景があったことから,私が原稿を書いている段階では「おそらく音楽生成AIは当分は流行らないだろう」という認識でした.実は圧縮前の2章には元々音楽生成AIの技術が出版されたものの数倍は書かれており,4章の創作xAIの部分でもSynthesizerV以外に音楽生成AIに関する議論がもっと含まれていました.しかし,「音楽がそもそも本という媒体では生えにくい」と編集カットをくらったことと,前述のように私が当分は流行らないと判断していたことから,本に書かれた音楽関連の情報はわずかです.これは本当にやらかしで,カットした原稿などをどこかで公開したいとずっと考えています.
ところで,先ほどSunoAIの流行に関してサブ想定外があると書きました.これは執筆には直接関係ないことなのですが,ついでに触れておきます.大変長いので興味がない人は飛ばしてください.
1つ目は,このSunoAIを使って一般ユーザーが生成していた曲の内容です.曲のほとんどがいわば「ネタ」に走った笑える曲でした.おそらく一番人気のジャンルは,ネット上の2ちゃんねる,な◯Jなどで有名なコピペなどをそのままSunoAIに入力して楽曲を生成するものです.次に人気だったのは,これもネタに走ったもので,とにかく今の感情や言いたいことを,曲のバランスも構成も何もかも無視して適当に歌詞に起こしたものです.魂の叫び的なやつです.画像生成AIの例を思い出して欲しいのですが,こちらでは元々プロのイラストレータがSNS上で頻繁に挙げていたようなアニメ調の美少女イラストなどを,画像生成AIを利用する非イラストレータのユーザーの多くが生成していました.つまり,生成AIを使う側も,その界隈の正統派(という言い方が正しいのかどうかはわかりませんが)に追従する形の生成が主だったわけです.SunoAIの場合はどうだったかというと,前述のように生成AIユーザーがいわゆる「正統派」の曲を生成しているとは言い難い状況で,バズっていたツイートもほとんどネタ曲です.
2つ目は,音楽界隈からのSunoAIに対する反応が当初は大きかったとは言えど,鋭い対立感情が表面化したものは少数で,むしろ「使い倒してやろう」という好意的な反応すらあったこと,さらに1週間も経つ頃には「ほな,作業に戻ろか・・・」と言わんばかりに,音楽界隈においてはメインの話題から消失したことです.この記事を読んでいる方は,ためしに今からTwitterのなどで「SunoAI」や「音楽生成AI」などと検索してみてください.そのツイートのほとんどは音楽界隈のユーザーではなく,稀に見かける音楽界隈の人も特に否定的な感情がある様子はないと思います.ただ,ツイートの数はそれなりで,多くの人がSunoAIを使って今も曲を生成しています(強いて言えばJASRACが声明を出していますが,これはこの団体の役割を考えると妥当でしょう).次に「画像生成AI」,何なら「生成AI」などを検索してみるとどうか.こちらは地獄と言ってもいい状況で,先ほど触れたように,特にイラスト界隈から凄まじいバッシングが起きています.
しかし,SunoAIと音楽界隈のこの状況は,イラスト界隈と併せてよく考えると奇妙なことです.まず,前提として技術的な説明をすると,SunoAIの基盤技術はおそらくはSunoAIの開発企業Sunoが公開している別の音楽生成AI「Bark」と同様だと思われます.これはChatGPTのようなTransformerの言語モデルと技術的にはかなりの部分で一致している音の生成モデルです.学習データについては,確かな情報がないのですが,研究者の視点から見ても,多くの音楽データをスクレイピングするなどして利用していることはほぼ疑いようがありません.ここまで書けば分かるように,このSunoAIは,生成AIに反対する立場の人間の言葉を借りて最大限に悪い言い方をすれば「アーティストが苦労して作った音楽データの無断学習によって作られた,他の生成AIと技術的には同じの悪き生成AI」です.
ところで,先ほど検索してもらった方は分かると思いますが,今も現在進行形で「音楽界隈の人ではない」いわば部外者の人がこの悪きSunoAIによって音楽を生成しています.イラスト界隈ではまさに同じ状況で炎上している訳で,同じ文化芸術に属する界隈ということで類推して考えるなら,音楽界隈の人間からすればまさに地獄のような状況のはず.しかし,見たところ,音楽界隈の人間が大きな集団で特別に声を上げている様子はありません.ちょっとコアな知識が必要ですが,たまに音楽生成AIに対して批判的なツイートが伸びているのをよく見ると,発信者や拡散者はほとんどが画像生成AIで騒いでいるユーザと一致しています.何より,SunoAIが流行った当時のツイートを見ると,まさに生成AIに反対の立場の人が「なんで音楽界隈はもっと反対しないのか」と言っています.繰り返しますが,悪き無断学習をおこなった悪きSunoAIを一般ユーザーが使い倒し,色んな曲が生成されている状況は,イラスト界隈で起こっている地獄と同じ状況のはずなのです.実際,いくつかの曲を聴いてみると,「おや,どこかで聴いたような」というコード進行が混じっています.これはいわば「作風」が生成AIによって学習されて第三者によって利用されている状況でもあり,音楽のクリエイターからは耐え難い状況なのではないか.まとめると,「音楽」という文化芸術に属するものが生成AIに関してイラスト界隈で起きていることと本質的には同じ状況になっているにも関わらず,後者と同じような反応が起きていない,これが「想定外」だということです.私の当初の考えは,音楽の生成AIが本格的に登場した時点で,イラスト界隈で起きたことと同様の騒動が長期にわたって起こるというものでした.これが起こらなかった理由は,「音楽界隈は既にDAWに搭載されたAIツールを多く使用している」,「ボーカロイドやSynthesizerVなどがそもそもAI技術の産物である」,「音楽は昔から技術の影響を受けまくってきたので,今更動じない.面構えが違う」など色々な考察を見ています.これについて,私も色々と考察しましたが,現在ではある程度納得のいく仮説を持っています.この仮説をもとに,仮に音楽の分野で,ボーカロイドというものが登場していなくても,AIを積極的に利用していない世界線があったとしても,おそらく音楽分野から大きな反対は起こりにくいのだろうと現在は考えています.これは別ところで詳細を書くことになると思いますが,単純に人間の脳の情報処理の時間的,物理的な制約が関係しているという仮説です.人間はイラストなどの視覚情報をコンマ数秒で知覚できるが,音楽はそうはいかない,という考えがベースにあります.この話はこの記事ではここまでです.
告知日が12月6日,出版が1月7日ということで,1ヶ月の期間があったことから,発売前の宣伝活動も行っていました.この宣伝活動は当然,発売が近づくにつれて活発にする予定だったのですが,まさかの事態が起きて,発売当日まで宣伝活動が停止しました.既に冒頭でも述べましたが,地元石川県に年末年始に帰省していた時に怒った能登半島地震に被災しました.本当はこの記事には,この部分や,後述の「出版後の反響」などはなく,宣伝活動の最後の一押しとして発売前日1月6日に公開する予定で書いており,一部は石川で地震発生前の地元で年末に書かれたものです.
出版当日,出版後の反響
1月7日,自らも被災した能登半島地震に対する不安が世間ではおさまらない中に発売されました.地元で自分の著書が並ぶ様子を当時に見れることを楽しみにしていたのですが,当然のように地震で北陸周辺の搬送網が壊滅しており,発売日には置いていなかったようです.
ともあれ,全国的には無事に出版され,東京でも当日朝に書店(書泉ブックタワー)で実物を確認,後は読者からの反応を待つだけになりました.
【重要告知】 本日1月7日,『生成AIで世界はこう変わる』発売ですhttps://t.co/YCij1Rd73u
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) January 7, 2024
私自身,帰省先の地元石川で能登地震の被災をし,宣伝もできない状況でしたが,いよいよこの日を迎えました.
2024年最初の生成AI本として是非どうぞ!
売上の一部は被災地の地元石川に寄付します.… pic.twitter.com/tUSncFgpH5
ここまで色々と書いてきた苦労は報われ,『生成AIで世界はこう変わる』は,筆者の想像も超える勢いで売れに売れてくれました!
告知日と同じく,本書のAmazon登録カテゴリーでは,告知時に1位を逃した新書全体部門を含めて全て一位を獲得,都内の主要書店でも新書ランキングえほぼ上位に居座ることになりました.発売から1週間も経たない5日目で重版が決定,その後も発売1ヶ月を迎える前に第三刷が決定しています.本の反響に合わせ,ありがたいことに講演・相談依頼なども物凄い量いただいています.単著の本が売れた時の反響というのは凄いもので,ほぼ毎日のように本に関して何らかの連絡が入ることになりました.

個人的に嬉しかったことは,東京大学の本郷キャンパスにある書籍部の売上ランキングにおいて,1月の新書部門1位を取ったことです.この書籍部は私の東大における居室から割と近いところにあり,頻繁に利用しているのですが,そこで「ベストセラー」の棚にドンっと置かれているのは大変な感動でした.本の発売後には,書店などに置かれて本の紹介を行う著者POPを書いたのですが,記念すべき初代POPはこの書籍部の入り口付近に置かれています.

本が売れたことで「めちゃくちゃ売れて儲かってるんだろ」とも結構言われています.ちょっと夢がないことを言いますと,実は金銭的な面を考えると,本の執筆に対して印税などが釣り合っているとは言い難いです.私の所属とも少し関連する部分があるのですが,多分本を書くよりは,その時間を使って別の金銭が発生する作業をやっていた方が,金銭的には得をしていたと思います,余程の大大ベストセラー作家でない限りは,他の売れているように見える人も本の売上で入る金銭は大したものではないのかもしれません.特に技術に関する本は,常識的には購入層が多いとは言い難く,受け取る金銭的な報酬が執筆の苦労の割にあうことはかなり稀でしょう.
本の出版で得た最大の報酬は,それによって舞い込んでくる縁やチャンスだと考えています.これについては,「そんなところから声がかかるとは・・・」と言うものが多数発生しており,これだけでも十分に本を書く動機にはなり得ると思います.
本に書けなかったこと
『生成AIで世界はこう変わる』では,生成AIに関する話題のほとんどを詰め込んだつもりではありますが,事情により意図的に載せていない話題も多く存在します.
まず最初に「私が書くのをうっかり忘れていた」話題です.これは事情があったという訳ではなく,私のやらかしです.特に以下2つが致命的でした.
・基盤モデル(Foundation Model)の言及
・「アライメント」という概念の説明
基盤モデルは,「大量で多様なデータを用いて訓練され, 様々なタスクに適応(ファインチューニングなど)できる大規模モデル」(by 松尾研究室TRAL,https://trail.t.u-tokyo.ac.jp/ja/blog/22-12-01-foundation-model/)を指す用語で,一部では現在の生成AIと同一視されるくらいには基本的かつ重要な概念です.これを序章に追加しようと執筆中にずっと思っていたのですが,諸々の作業に追われて追加を忘れたままになってしまいました.
アライメントは2章のChatGPTの学習における強化学習の説明の流れで自然に出てきそうなのですが,ちょっと伝わりにくい語だと思って使用を避け,5章において「AIと人間の共生」みたいな文脈で回収しようと思っていました.しかし,これも色々とやっている間に脱稿し,アライメントという単語すら登場しないことに・・・.
次に自分としては書きたかったが,紙面の問題でカットされた部分です,これは本記事の別の部分でも触れましたが,2章の技術解説や,音楽生成AIに関するものです.何処かでカットされた原稿を公開したいとは思っています.
最後に,意図的に書くのを避けた話題です.これはたくさんあるのですが,主要なものは以下です.
・プロンプトエンジニアリングの具体的な方法論
・政治・安全保障と生成AI
・著作権における生成AIの侵害の基準
・人間の脳とAIの関係
ネット上でも大人気で,なんなら一般的にも一番人気だと思われるのが,プロンプロトのテクニック的な話題ですが,本書では記述を避けました.まず長くなってしまうという理由はあるのですが,これは研究者的にも微妙な問題です.ネット上で「プロンプトのテクニック」,「これがあれば最強プロンプト」として喧伝されているもののほとんどは,研究に基づいておらず,その性能は怪しいものです.確かに,ChatGPTでいい感じの出力をしてくれるプロンプトだが,研究になっていない手法がいくつか存在しているのは事実です.しかし,これらの大半は,ChatGPTという言語モデルの一実装に強く依存していたり,ちょっとしたチューニングで機能しなくなってしまうものであり,おそらく今後も発展が続く生成AIで恒久的に利用できるものではありません.本書は色々言いながらもできるだけ寿命が長い内容にしたかったこともあり,近視眼的な話題として避けました.
政治・安全保障は,私が永田町に出向いた時にも,多く聞かれたトピックで,最近の物騒な世界情勢を考えると関心を持つ人は多そうですが,これも避けました.政治に関しては,私の知識では平凡なことしか書けないというのが一点,安全保障に関しては知識はともかくとして私が所属する東京大学が慎重な姿勢をとっており,私がそれに大きく触れるべきではないと判断したことによります.
著作権と生成AIの話題は既に本に収録されていますが,これは学習に関するものだけで,生成AIの利用段階でどのようなことをすれば著作権侵害になるのかまでは触れていません.まず基本的な考え方として,生成AIと著作権を考える際には,学習時と生成時を分けて議論する必要があります.これは文化庁の資料などでも示されている基本的な考え方です.私の本では学習時のみを扱っています.生成されたコンテンツがどういう用件で侵害になるのかの基準は,文章にすれば割と簡単です.つまり依拠性と類似性の「両方が」満たされた場合にのみ,侵害になるということです.そして,これは生成AIによって生み出されたコンテンツに限らず,人間によって生み出されたコンテンツでも基準は同じです.文章にすると簡単なのですが,これが具体的にどのような場合に裁判などで著作権侵害と判定されるのかについては,まさに激論中とも言っていい状況で,法律関係者などからさまざまな解釈が出ています.この基準,判定について技術者が口を出せる部分は正直言ってほとんどなく,極端なことを言えば「何が著作権侵害なのかは裁判官にしかわからない」ということになります.よって,本ではこの部分に関しては特に触れませんでした.
人間の脳とAIの関係については,一般的にAI研究者は大好きな話題です.私も大好きです.しかし,現在の状況を鑑みると,おそらくここで私の考えを書いてしまうと,少しアレな反応を呼び起こすのではないかと思い,書きませんでした.5章の執筆段階では最後の方にチラッと書いてはいたのですが,編集に共有する前にセルフカットしています.
これから書きたいこと
・思想書?的なもの.AIが人間の知的能力全体を超えた社会で,人間は何をすべきか.『スーパーインテリジェンス』や『LIFE3.0』など類書はあるが,アレらは「AIは人間を超えるのか.超えるとすればどのような方法か」もかなり議論しているのに対して,こちらではAIが近いうちにこの領域に達することは前提に「経済的な影響」,「人間に残されたもの」などを論じたい.
・一般書.AIにおいて意思決定則を扱う強化学習の考え方(長期的な利益を考慮している,トレードオフを意識する,マルチエージェントであれば集団報酬を最大化する等)が,人間個人,あるいは社会の思考として非常に有益であるという話
・専門書.マルチエージェント強化学習,あるいは強化学習全体.私が東大松尾研の講義でやっているような内容.
思想書は,何年もかけたゆっくりと,一般書は時間が取れれば一気に,専門書は今までやったきたことをまとめる形でやってみたいです.
編集について
今まで共著しか書いてなかったこともあり,出版社の編集者と本格的に作業するのは初めてだったのですが,編集者の方達の能力の高さに感動しました.前述のように本の文体がやたら賞賛されているのですが,かなりの部分で編集者による修正が影響していると思います.また,編集によって異なるかもしれませんが,私の編集の場合には大変知識が豊富で,ロボットなどのAIについて「なんでそんなことまで知っているのか?」というものが多くありました.
また,私は長期間のスケジュール管理が大変下手くそで,本の執筆という作業を完了させられるかはかなり疑問だったのですが,この辺もいい感じに私に催促を入れてくれて,出版に至りました.それでもとの刊行予定に間に合わなかったのは私の力不足です.
本の出版後にも,編集者はかなりよく働いてくれています.むしろ,本の出版後の方がすごいように思います.本の宣伝に関して,「マジかよ」という案件を持ってきたり,施策を提案してくれています.これはこの記事を書いている今も続いていることです.
編集者については,私の執筆の同時期に「やばいのに当たった」という例も見ているので,いくらか版元ガシャの要素があるとは思います.ただ,この本の版元となったSBクリエイティブは自信を持って,良い版元だと断言できます.一般書を執筆したい人は掛け合ったみたり,向こうから企画があった場合には積極的に受けてみてください.
最後に
『生成AIで世界はこう変わる』の執筆には多くの苦労がありましたが,2月現在ではその苦労は報われ,今も多くの人に売れて高評価をいただいております.お買い上げいただいた皆さん,高評価をしてくれた皆さん,そして本の執筆に協力してくれた皆さん,本当にありがとうございました.
本の発売後にも生成AIの発展は続いています.例えば本記事の発表1週間ほど前にはGoogleからGPT-4を超えると噂されるGemini Ultra(サービス名としてはGemini Advanced)が公開されました.本書の最後にも書きましたが,この本の寿命は短くなってしまいそうです.本書で言いたかった結論は一言でまとめると「生成AIの発展スピードもその影響もやばいし,何が起こるかは研究者でもわからん!!」になります.本のタイトルの「こう変わる」を完全に無視しているような気もします.しかし,この結論に従えば,この本の寿命が短いことは,この本で言いたかったことの核をまさに証明しているとも言えます.
本の原稿が11月終盤に私の手を離れてから2ヶ月くらい,この間にもGeminiをはじめとして,生成AIに関する多くの面白い手法やサービスが誕生しています.
ここでお知らせがあります.2月15日に東京の青山ブックセンター本店にて,現 Turing社のCEOにして,かつては現役名人を人類史上初めて破った将棋AI Ponanzaの開発者でもあった山本一成さんと,『生成AIで世界はこう変わる』刊行記念イベントを行います.
ここでのトーク内容は私自身が自由に決められるのですが,そこで,本書の執筆完了後に生成AIで起こった出来事・誕生したサービスや技術についてお話ししようと思います!
(元々はお試しでnoteの有料記事にしようかと思ったのですが,上記イベントの方が金を取るイベントなので,そちら優先にしました)
また,研究室の内部とも相談した結果,会の終了後の時間で,松尾研に関する案件の投げ込みやプロジェクト(例えば最近採択された大規模言語モデルのプロジェクト https://weblab.t.u-tokyo.ac.jp/geniac_llm/),相談を私が受け付けて持ち帰っても良いということになったので,そのような目的の方でもぜひご来場いただければと思います.
※この記事はものすごい急ピッチで書かれたため,後日記述を変更する可能性があります.
この記事が気に入ったらサポートをしてみませんか?