
RでもKaggle Competitions Expertになれる

R Advent Calendar 2022の25日目の記事です。メリークリスマス。
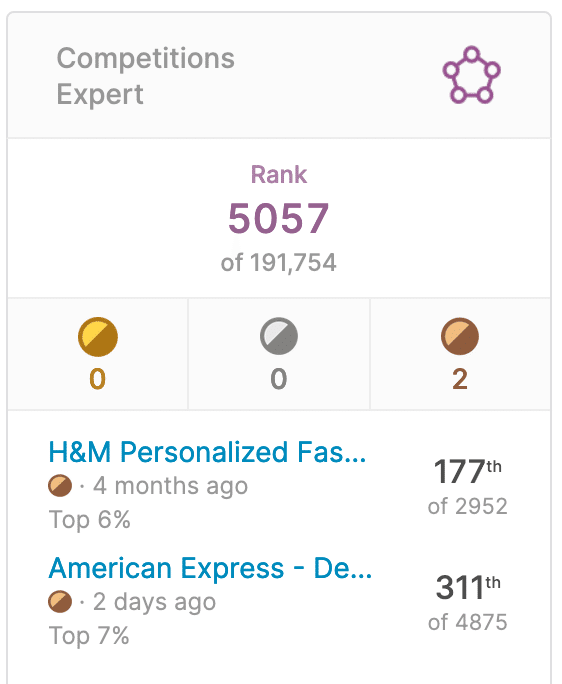
先日、Notebooks Expertに続き、RでKaggle Competitions Expertになれました。
(Notebooks Expertになる話はこちら: RでKaggleをやってたらいつのまにかNotebooks Expertになってた)
Competitions Expertになるまでにやったこと、Rで良かったことなどの話をしようと思います。
なお、実際にはCompetitions Expertは一人だけで獲得したものではありません。メダルを獲得した2つのコンペはどちらも個人ではメダル圏に達することはできませんでした。Competitions Expertになれたのはあくまでチームのアンサンブルの成果で、チームメイトはPythonも使っています。この記事は私がRで何をやったかの説明になります。
チームメイトのnoteは以下です。
Competitions Expertとは
Kaggleには、Novice、Contributor、Expert、Master、Grandmasterの5段階の称号があります。(Kaggle Progression System)
今回私が得たのはCompetitionsカテゴリに対するExpertの称号で、コンペで銅メダルを2つ獲得するともらえます。コンペの銅メダルは、1000チーム以上参加のコンペの場合は上位10%に入るともらえます。
なぜRなのか
なぜ私がRを使ったのか。それは私がRが好きだからなのと、Rでメダルを取れるか試したかったからです。
私はRが好きです。Rは関数型プログラミングを推奨していて、参照透明な関数の組み合わせで仕事をするスタイルが好みだし、NSE(non-standard evaluation)で構文木を読み書きできる柔軟性にわくわくします。
そして元々のRの柔軟性の上に作られたRの方言とも言えるtidyverseのパッケージ群。dplyrの関数をパイプでつなぎ合わせて息を吸って吐くようにデータを加工できる快適さを知ってしまったらもう元には戻れません。私にとって現時点でRはデータ分析をするのに最大火力を発揮できる言語なのです。
しかしRでKaggleをやる人は少ない。もしそれが言語そのものの問題だったら仕方ないけど多分そうじゃないだろう。単に現在RでKaggleをやっている人が少ないせいでRはKaggleに不向きだと勘違いされているならなんとかしたい。なのでタイトル通り「RでもKaggle Competitions Expertになれる」ことを示すためにRでチャレンジしました。
やったこと
H&Mコンペ
最初に挑戦したのはH&Mコンペという、ユーザーに対する服の推薦の精度を競うコンペでした。このコンペではルールベースの推薦をdplyrで実装しました。
コンペに参加した様子はTokyo.Rで発表したスライドにまとまっています。
Amexコンペ
次に挑戦したのはAmexコンペという、クレジットカードのデフォルト(支払いの極度な滞納)を予測するものです。
このコンペで私がやったことを、使ったRのパッケージを交えて紹介します。
前処理
このコンペで、188個の匿名のカラム×500万行の訓練データ(CSVファイル16GB)、という今までに扱ったことない巨大なデータと初めて対峙しました。
100個以上あるカラムを1つづつ指定して集計、とかやってられません。dplyrのacross()を使って複数のカラムに同じ処理を実行するようにしました。前処理を実行する関数はこんな感じ。
process_and_feature_engineer <- function(df) {
cat_features <- c("B_30", "B_38", "D_114", "D_116", "D_117", "D_120", "D_126", "D_63", "D_64", "D_66", "D_68")
num_features <- setdiff(colnames(df), c(cat_features, "customer_ID", "S_2"))
df %>%
group_by(customer_ID) %>%
summarise(across({{ cat_features }}, list(last = last, nd = n_distinct)),
across({{ num_features }}, list(mean = mean, sd = sd, min = min, max = max, last = last)))
}dplyr便利。
ところでこのコードは900個の特徴量を一気に生成しようとします。処理する行数が少ないうちは動くんですが、500万行を処理しようとするとメモリ不足で動きません。
Rで巨大なデータを高速に処理する方法はないのか…… と悩んでいたときに以下のチュートリアルを見つけました。
メモリより大きいデータをApache Arrowで扱う、これはいけるのでは!?
train_tbl %>%
process_and_feature_engineerこのコードが
train_tbl %>%
to_duckdb %>%
process_and_feature_engineer %>%
collectto_duckdbするだけで動くようになった!しかも速い!
コード全体はこちら:
このベンチマークだとDuckDBはtibbleの4倍以上速い結果になりました。
DuckDBすごい。
モデリング
モデリングには、tidymodelsという機械学習を整然とこなすためのフレームワークを使いました。機械学習に必要な典型的なワークフローを簡潔に記述できて良いです。
公式のGET STARTEDを読めばとりあえずtidymodelsを使い始められるはず。
年末に待望の「Rユーザのためのtidymodels[実践]入門」が発売されるので、今後はこれを読めば良さそう。読むの楽しみです。
思ったこと
ふたつのコンペにRで参加してみて思ったことを書いておきます。
前処理
dplyrによる前処理は快適の一言です。使えば使うほど手になじんで、思った処理を簡潔に記述できるようになる。データが巨大になっても、dplyrで書いたデータ処理の内容を書き換えずに、バックエンドをDuckDBやdata.tableに気軽に切り替えて対応できる。
前処理に関してはこれからもしばらくはdplyrを使い続けることになりそうです。
モデリング
tidymodelsに関しては、使い始めたばかりでもっと慣れが必要だなと感じています。
フレームワークは、よくある典型的な処理を簡潔に記述できるような工夫、みたいなものだと思っているのですが、これがコンペでやりたいことにフィットしてないと感じることがときどきありました。tidymodelsが想定しているワークフローに従っているうちは、ものすごく簡潔に機械学習のコードを書けるのですが、他のKaggleユーザーが公開している高スコアのPythonコードをtidymodelsで真似しようとすると途端にどうして良いかわからなくなる、みたいな。
また、tidymodelsでLightGBMを使うためにbonsaiというラッパーを使います。これはAmexコンペに参加した当時はリリースされたばかりで(v0.1.0)、まだ発展途上でした。
なので、tidymodelsが対応していない最新のアルゴリズムを使いたいケースではコンペでは不利になりそうです。機械学習アルゴリズムに関しては今後は状況に応じてPythonも併用することがあるかもしれません。
機械学習コンペはどんな汚い手を使ってもスコアを上げるゲームだと思っているのですが(偏見)、いつかtidymodelsできれいなコードで高いスコアを出せるようになりたいです。
これから
というわけでRでKaggle Competitions Expertになった話でした。
次に目指すのはKaggle Masterですが、そのためには金メダル1個、銀メダル2個獲得する必要があり、いまのところ全く達成できる気がしません!でも楽しみながらチームメイトと一緒にチャレンジしていきたいと思います。
今後も他の選択肢も視野に入れつつ、RでKaggleを楽しんでいきます。
この記事が気に入ったらサポートをしてみませんか?