
ai castの性能評価 (vs Jetson Orin Nano)

みなさんこんにちは。Idein株式会社ソリューションアーキテクト部の新田です。今回は弊社が提供するエッジAIプラットフォーム「Actcast」に対応するエッジAIカメラ「ai cast(アイキャスト)」について、性能評価を行い、他デバイスとの比較を行います。
今回の評価に使用したコードはGithub上で公開しています。
https://github.com/Idein/aicast_jetson_benchmark

ai castの紹介
ai castはアイシン社が開発しているエッジAIカメラで、Raspberry Pi Compute Module4をベースにAIアクセラレータ・モジュールカメラを組み合わせたデバイスとなっています。
AIアクセラレータにはHailo-8プロセッサを採用し、低消費電力と高性能性を実現するAIカメラです。Haiilo-8プロセッサは最大26TOPSの演算能力をもっています。
ai castとActcastの詳しい紹介はこちらをご覧ください。
評価対象
今回は性能比較を行う対象として、エッジAI分野で広く使用されており、価格面もai castと近い範囲にある以下の2デバイスを選びました。
NVIDIA Jetson Nano
JetPack 4.6.1 TensorRT 8.2.1 CUDA 10.2
NVIDIA Jetson Orin Nano 8GB
JetPack 5.1.2 TensorRT 8.5.2 CUDA 11.4
Jetsonデバイスはいずれも電源設定をMAXNモードにして評価を行います。
性能評価を行うモデルには、物体検出モデルYOLOX-Sを選択しました。入出力サイズは(640, 640)とします。オリジナルのYOLOXでは活性化関数にHardSwishが使用されていますが、int8量子化を行うと精度が落ちやすいなどの理由から、今回は活性化関数をLeaky-Reluに変更したyolox_s_leakyを選択しました。学習済みのONNXモデルをHailo Model Zooからダウンロードすることができます。
wget https://hailo-model-zoo.s3.eu-west-2.amazonaws.com/ObjectDetection/Detection-COCO/yolo/yolox_s_leaky/pretrained/2023-05-31/yolox_s_leaky.zip
unzip yolox_s_leaky.zipまた、量子化キャリブレーション・精度評価用にCOCO 2017データセットのtest, valをダウンロードしておきます。
Jetson Orin Nanoでの評価手順
速度評価
速度評価にはTensorRTに含まれるtrtexecを使用してONNXモデルを実行します。
FP32, FP16
export PATH=/usr/src/tensorrt/bin:$PATH
# FP32
trtexec --onnx=./yolox_s_leaky.onnx --saveEngine=./default.trt
# FP16
trtexec --onnx=./yolox_s_leaky.onnx --saveEngine=./fp16.trt --fp16TensorRTでのビルドが行われ、以下のようなログが出力されます。
[02/26/2024-10:43:06] [I] === Performance summary ===
[02/26/2024-10:43:06] [I] Throughput: 97.8649 qps
[02/26/2024-10:43:06] [I] Latency: min = 10.642 ms, max = 10.9861 ms, mean = 10.7971 ms, median = 10.7972 ms, percentile(90%) = 10.9329 ms, percentile(95%) = 10.949 ms, percentile(99%) = 10.9744 ms
[02/26/2024-10:43:06] [I] Enqueue Time: min = 1.1098 ms, max = 2.30975 ms, mean = 1.36227 ms, median = 1.19873 ms, percentile(90%) = 1.9928 ms, percentile(95%) = 2.07275 ms, percentile(99%) = 2.15002 ms
[02/26/2024-10:43:06] [I] H2D Latency: min = 0.299072 ms, max = 0.373962 ms, mean = 0.316446 ms, median = 0.310486 ms, percentile(90%) = 0.332031 ms, percentile(95%) = 0.345398 ms, percentile(99%) = 0.354126 ms
[02/26/2024-10:43:06] [I] GPU Compute Time: min = 10.0343 ms, max = 10.3575 ms, mean = 10.1824 ms, median = 10.1851 ms, percentile(90%) = 10.3206 ms, percentile(95%) = 10.338 ms, percentile(99%) = 10.356 ms
[02/26/2024-10:43:06] [I] D2H Latency: min = 0.17041 ms, max = 0.312134 ms, mean = 0.29821 ms, median = 0.298584 ms, percentile(90%) = 0.302856 ms, percentile(95%) = 0.304077 ms, percentile(99%) = 0.310608 ms
[02/26/2024-10:43:06] [I] Total Host Walltime: 3.0348 s
[02/26/2024-10:43:06] [I] Total GPU Compute Time: 3.02418 s
[02/26/2024-10:43:06] [I] Explanations of the performance metrics are printed in the verbose logs.
[02/26/2024-10:43:06] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v8502] # trtexec --onnx=./yolox_s_leaky.onnx --saveEngine=./fp16.trt --fp16INT8
Jetson Orin Nanoにはint8演算精度に対応したTensorコアが搭載されており、モデルを量子化することで演算速度の高速化が見込めます。int8量子化の作業については、https://github.com/xuanandsix/Tensorrt-int8-quantization-pipline を参考に一部修正し、差分を公開しています。前処理の正規化の削除、TensorRT他パッケージを実験環境に合わせるための修正、実行オプションの追加などを行いました。また、CalibratorはIInt8MinMaxCalibratorベースに変更しています。 量子化キャリブレーション用にCOCO testデータセットをデバイス側にコピーしておき、量子化を行います。
git clone https://github.com/Idein/aicast_jetson_benchmark.git
cd aicast_jetson_benchmark/jetson
git clone git@github.com:xuanandsix/Tensorrt-int8-quantization-pipline.git
cd Tensorrt-int8-quantization-pipline
git apply patch ../0001-evaluate-yolox_s_leaky-on-jetson.patch
python3 ./sample.py --training_data_path ~/idein/coco/test2017/
python3 quantization.pymodelInt8.engineが量子化されたエンジンとして保存されます。trtexecにこれを読み込ませて実行します。
# INT8
trtexec --onnx=./yolox_s_leaky.onnx --loadEngine=./modelInt8.engine推論デモ・精度評価
FP32, FP16精度での推論デモにはonnxruntime-gpuを使用します。
Jetson Orin Nanoにはonnxruntime-gpu 1.16.0を使用しました。JetPackのバージョンに応じてビルド済みのwhlファイルをJetson Zooから入手することができます。
INT8精度での推論デモにはTensorRT pythonバインディングを使用します。
推論デモとしてyolov3でお馴染みのdog.jpgを読み込ませて物体検出を行います。正しく推論が行われていることが確認できます。
# FP32
python3 demo_onnx.py --model_path ./yolox_s_leaky.onnx --label_name_path ./coco.label --image_path ./dog.jpg --output_path ./result.jpg --mode trt --warmup
preprocess 0.01185154914855957
infer 0.02301931381225586
postprocess 0.009637117385864258
all 0.04450798034667969
FPS 22.467880865652454
# FP16
python3 demo_onnx.py --model_path ./yolox_s_leaky.onnx --label_name_path ./coco.label --image_path ./dog.jpg --output_path ./result.jpg --mode trt_fp16 --warmup
preprocess 0.011473894119262695
infer 0.01324462890625
postprocess 0.012219429016113281
all 0.03693795204162598
FPS 27.07242672449961
# INT8
python3 demo_trt.py --model_path ./modelInt8.engine --label_name_path ./coco.label --image_path ./dog.jpg --output_path ./result_int8.jpg
preprocess 0.012786388397216797
infer 0.014822721481323242
postprocess 0.008907318115234375
all 0.036516427993774414
FPS 27.384934807163702
精度評価には、Flaskを用いてエッジデバイスを推論サーバ化し、クライアント側から画像を送り推論結果を受け取ることにします。サーバ側のコードはあくまで実験用のため、単一クライアントによる逐次実行を前提としています。
python3 server.py --mode trt --model_path ./yolox_s_leaky.onnxホストPC側でクライアント側のコードを実行して、推論結果をjsonファイルで保存します。最後に、pycocotoolsを使用して精度評価を行います。
git clone https://github.com/Idein/aicast_jetson_benchmark.git
cd host
python3 client.py --host 192.168.0.20 --output ./jetson_orin_nano_trt.json
python3 eval.py --result_json ./jetson_orin_nano_trt.json
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.321
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.476
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.346
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.150
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.353
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.452
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.274
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.395
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.403
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.192
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.439
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.559Jetson Nanoでの評価手順
Jetson Orin Nanoでの評価手順と同じ手順で行いますが、Tensorコアが搭載されていないためINT8精度での評価は行なっていません。Jetson Nanoにはonnxruntime-gpu 1.10.0を使用しました。
python3 demo_onnx.py --model_path ./yolox_s_leaky.onnx --label_name_path ./coco.label --image_path ./dog.jpg --output_path ./result.jpg --mode trt --warmup
preprocess 0.022043943405151367
infer 0.16379547119140625
postprocess 0.03904414176940918
all 0.2248835563659668
FPS 4.446745756602313
python3 demo_onnx.py --model_path ./yolox_s_leaky.onnx --label_name_path ./coco.label --image_path ./dog.jpg --output_path ./result.jpg --mode trt_fp16 --warmup
preprocess 0.02203965187072754
infer 0.10640501976013184
postprocess 0.026060819625854492
all 0.15450549125671387
FPS 6.472261871511613ai castでの評価準備
モデルのコンパイル
Hailo-8でAIモデルを動作させるには、専用のHEF(Hailo Executable Format)ファイルにモデルをホストPC(GPU搭載推奨)上でコンパイルする必要があります。下図はHailo Dataflow Compilerユーザガイドからの引用です。
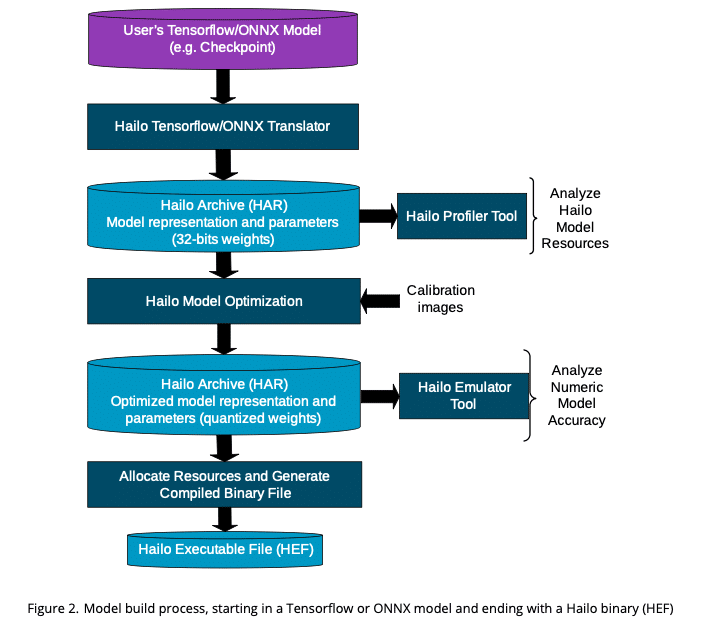
具体的に下記のステップに従ってモデルをコンパイルします。
hailo parser: ONNX/Tensorflowモデルを入力としてHAR(Hailo Archive)ファイルを作成する
hailo optimize: キャリブレーションデータを使用してHARファイルの量子化を行う
hailo compile: 量子化されたモデルをデバイス向けにコンパイル、デバイスのどのリソースで演算を行うかがマッピングされる
Hailo Dataflow CompilerをHailo Developer Zoneから入手します(会員登録が必要です)。今回はnvidia/cuda:11.2.2-cudnn8-runtime-ubuntu20.04 イメージを使用してDockerコンテナを起動した上でインストールしました。
pip install hailo_dataflow_compiler-3.24.0-py3-none-linux_x86_64.whlインストール後、hailoコマンドが使用できるようになります。
入力となるモデル内に非対応のオペレータが存在する場合は、Hailo-8上で動作させたい部分の開始/終端ノード名をHAR作成時に指定します。
ノード名の確認にはモデル可視化ツールのnetronを使用します。
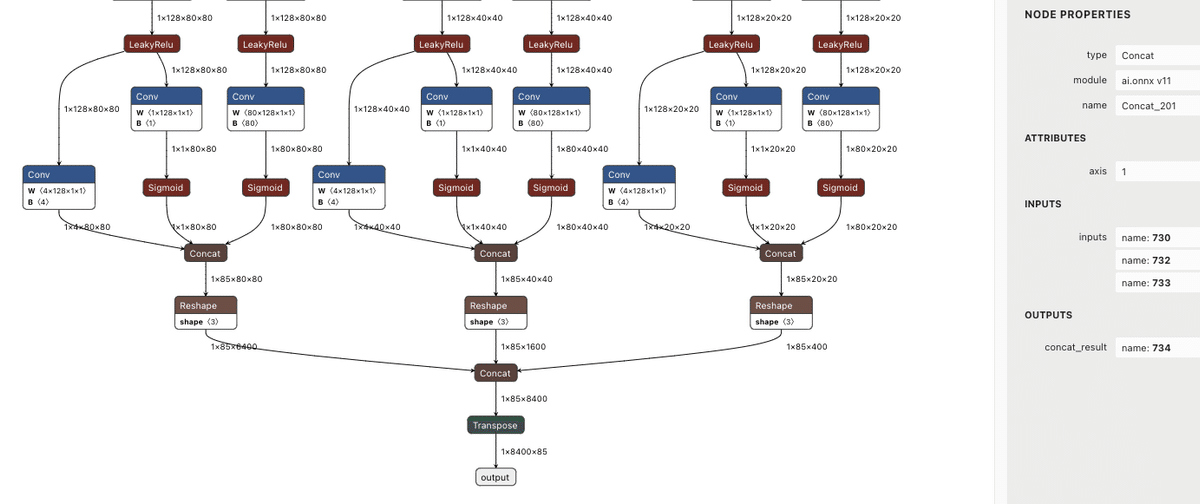
本記事で使用するyolox_s_leaky.onnxは全てのオペレータをHailo上で動作させることができますが、今回は実装の都合上、3つのConcatノードで処理を切ることにします。
hailo parser onnx yolox_s_leaky.onnx --start-node-names images --end-node-names Concat_201 Concat_217 Concat_233 --hw-arch hailo8
[info] Translation completed on ONNX model yolox_s_leaky
[info] Initialized runner for yolox_s_leaky
[info] Saved Hailo Archive file at yolox_s_leaky.haryolox_s_leaky.harファイルが作成されました。
次に、量子化キャリブレーションに使用するデータを作成します。入力となる画像データをnumpyで直列化して保存します。
import numpy as np
import glob
from PIL import Image
images = []
for i, f in enumerate(glob.glob('/data/dataset/coco/test2017/*.jpg', recursive=True)):
if i == 4000:
break
image = Image.open(f).convert('RGB').resize((640, 640))
npimg = np.asarray(image)
images.append(npimg)
np.save('calib_set.npy', np.stack(images, axis=0))次に、量子化・コンパイル時の指示ファイルを作成します。Hailo Dataflow Compilerではこれをalls(model script)ファイルと呼びます。今回作成したallsファイルは以下の通りです。
allocator_param(timeout=1800)
model_optimization_config(calibration, batch_size=4, calibset_size=4000)
post_quantization_optimization(finetune, policy=enabled, learning_rate=0.0001, epochs=8, batch_size=4, dataset_size=4000)
performance_param(fps=250)allocator_param: コンパイル時のリソース割り当て探索を30分でタイムアウトさせる
model_optimization_config post_quantization_optimization: 量子化キャリブレーション指定
performance_param: FPSを向上させるため、デフォルトのGreedyストラテジ(各レイヤが最高速で動作するように配置の最適化が行われ、その後デバイスに合わせてコンテキストを分割される)の代わりにPerformanceストラテジを使用します。これによりコンテキスト分割が小さくなり、FPSが向上します。
今回は行いませんでしたが、allsファイルでは、特定のレイヤを4/8/16bit量子化するといった指定や、前後処理をHEFファイルに内包するといった指定も可能です。キャリブレーションデータとallsファイルを指定してモデルの量子化を行います。
hailo optimize yolox_s_leaky.har --calib-set-path calib_set.npy --model-script model.alls --hw-arch hailo8今回は量子化に1時間弱かかりました。yolox_s_leaky_quantized.har ファイルが生成されます。最後に、モデルのコンパイルを行います。
hailo compiler yolox_s_leaky_quantized.har --hw-arch hailo8リソースの割り当てが行われている様子がログで確認できます。
yolox_s_leaky.hef ファイルがHailo上で動作するモデルとなります。このファイルをai cast上にコピーします。
なお、今回は行いませんが、yolox_s_leaky.har ,yolox_s_leaky_quantized.har ファイルはホストPC上でのEmulator実行が可能です。内部的にはTensorflowのグラフとして演算が行われ、量子化前後での出力比較などを行うことができます。精度に満足できない場合はallsファイルを調整し最適化を再度行います。
ai castのセットアップ
デバイス側のセットアップを行います。
ai castで使用するOSにはActcastアプリの開発環境であるactsimを使用します。Hailo-8アクセラレータを使用するには以下をインストールする必要があります。
ドライバ: https://github.com/hailo-ai/hailort-drivers
Actcast Documents: ai castでのactsimセットアップ を参考にインストール
Actcast Documentsのセットアップでランタイムのインストールを行っていないのは、ActcastアプリではランタイムがアプリのDockerイメージ内に含まれるためです。
今回の検証ではDockerイメージを使用しないため、ランタイムをai cast上にインストールする必要があります。
sudo apt-get install cmake
git clone https://github.com/hailo-ai/hailort.git -b v4.10.0
cd hailort
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
make -j 3
sudo make installHailoのランタイムライブラリとしてはC/C++/Pythonによる実装が提供されています。HailoのPythonライブラリはPython3.8が必要ですが、今回はPython3.7を使用するため、Cでランタイムを呼び出してcdll経由でPythonから実行します。
Hailo-8で動作するモデル一覧やその性能はHailo Model Zooで確認できます。ただし、ai castではこの通りの速度性能を出すことができません。これはHailo-8 M.2モジュールがPCIe Gen3.0 2-laneで接続されるのに対し、ai castではRaspberry Pi CM4の制約上PCIe Gen2.0 1-laneでしか接続されず、Raspi ↔ Hailo間のデータ転送速度が遅くなるためです。
ai castでの評価手順
速度評価
速度評価にはHailoランタイムに含まれるCLIツールhailortcliを使用します。
$ hailortcli benchmark --no-power true yolox_s_leaky.hef
Starting Measurements...
Measuring FPS in hw_only mode
Network yolox_s_leaky/yolox_s_leaky: 100% | 3762 | FPS: 250.78 | ETA: 00:00:00
Measuring FPS in streaming mode
Network yolox_s_leaky/yolox_s_leaky: 100% | 3539 | FPS: 235.89 | ETA: 00:00:00
Measuring HW Latency
Network yolox_s_leaky/yolox_s_leaky: 100% | 1092 | HW Latency: 8.61 ms | ETA: 00:00:00$ hailortcli run yolox_s_leaky.hef --measure-latency --measure-overall-latency
Running streaming inference (yolox_s_leaky.hef):
Transform data: true
Type: auto
Quantized: true
Network yolox_s_leaky/yolox_s_leaky: 100% | 456 | HW Latency: 8.61 ms | ETA: 00:00:00
> Inference result:
Network group: yolox_s_leaky
Frames count: 456
HW Latency: 8.61 ms
Overall Latency: 10.92 msここで、HW Latencyとは、Raspi上のメモリからデータ転送を開始してから、Hailo-8上で推論処理が行われ、出力をRaspi上のメモリにコピーが完了するまでの時間を指しています。Overall Latencyは、ランタイムによって推論前後で行われるCPU処理を含んだ時間となっています。実際にアプリケーションでの推論を行う際はOverall Latency分の時間がかかることになります。
推論デモ・精度評価
推論デモ・精度評価では前後処理はJetsonで使用したものと同じコードを使用しました。
git clone https://github.com/Idein/aicast_jetson_benchmark.git
cd aicast/edge
make #src/model.cのコンパイル
python3 demo_aicast.py --image_path dog.jpg --output_path result.jpg
preprocess 0.018979724248250326
infer 0.014112377166748047
postprocess 0.002598913510640462
all 0.035691014925638836前処理・推論・後処理にかかった時間を計測したところ、なんと前処理のほうが推論処理より遅いという結果になってしまいました。また推論時間がhailortcliの結果よりも遅くなっているのは、cdllの呼び出しにかかる時間が含まれているためだと予想されます。
精度評価ではJetsonと同様に、サーバプログラムを起動しホストPCから画像を送信して結果を保存します。
python3 server.pypython3 client.py --host 192.168.0.18 --output ./aicast.json
python3 eval.py --result_json ./aicast.json
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.343
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.518
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.371
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.170
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.378
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.460
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.275
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.407
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.418
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.213
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.458
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.547評価結果一覧
速度比較
$$
\begin{array}{|l|l|r|r|r|} \hline
\text{デバイス} & \text{ランタイム/精度} & \text{FPS} & \text{infer latency(ms)} & \text{all latency(ms)} \\ \hline
\text{Jetson Orin Nano} & \text{trtexec/FP32} & 49.0 & 20.9 & 44.5 \\ \hline \text{Jetson Orin Nano} & \text{trtexec/FP16} & 97.8 & 10.7 & 36.9 \\ \hline \text{Jetson Orin Nano} & \text{trtexec/INT8} & 126.3 & 8.6 & 36.5 \\ \hline \text{Jetson Nano} & \text{trtexec/FP32} & 6.5 & 153.3 & 224.8 \\ \hline \text{Jetson Nano} & \text{trtexec/FP16} & 10.6 & 93.7 & 154.5 \\ \hline \text{ai cast} & \text{Hailo8/INT8} & 250.5 & 8.6 & 35.6 \\ \hline \end{array}
$$
FPS, infer latencyはベンチマークツール(jetson:trtexec, ai cast:hailortcli)を用いて計測しました。infer latencyは推論単体の実行時間で、モデルの入力を与えてから推論結果をメモリ上にコピーするまでの時間を計測しています。
all latencyはpythonスクリプトを用いて計測しました。前後処理全てを含んだ実行時間です。
最もFPSが高いのはai castで、2番目はJetson Orin Nano(INT8)でした。ai castでのFPSが最も高いのは、Hailo-8がデータフローアーキテクチャを採用していることが寄与していると考えられます。
推論レイテンシはai castとJetson Orin Nano(INT8)がほぼ同じ結果となりました。これらのケースでは前処理がほぼ推論処理と同じ時間かかっているため、Python実装の前処理をC実装に移植する、JetsonではCUDA実装に移植するなど、高速化の余地は残されていると考えられます。
精度比較
$$
\begin{array}{|l|l|r|r|r|} \hline
\text{デバイス} & \text{ランタイム/精度} & \text{mAP@IoU0.50:0.95} & \text{mAP@IoU0.50} & \text{mAP@IoU0.75} \\ \hline
\text{Jetson Orin Nano} & \text{TensorRT/FP32} & 35.2 & 52.2 & 38.1 \\ \hline
\text{Jetson Orin Nano} & \text{TensorRT/FP16} & 35.2 & 52.2 & 38.0 \\ \hline
\text{Jetson Orin Nano} & \text{TensorRT/INT8} & 31.0 & 46.8 & 33.7 \\ \hline
\text{ai cast} & \text{Hailo8/INT8} & 34.3 & 51.8 & 37.1 \\ \hline
\end{array}
$$
COCO2017 valデータセットおよびpycocotoolsを用いて精度を検証しました。
一般にモデルの量子化を行うと、精度が劣化します。Jetson Orin Nano(FP32)とai cast(INT8)を比較すると、精度劣化はmAP@IoU0.50:0.95で35.2→34.3, mAP@IoU0.50で52.2→51.8と小さく抑えられていることがわかります。
TensorRT(INT8)の精度がai cast(INT8)に比べて低いのは、キャリブレーション方法に問題があったと考えています。今回はai castに焦点を当てているため深掘りはしませんが、キャリブレーション方法を工夫すれば精度は改善するものと考えられます。
消費電力比較
ACアダプタにサンワサプライ製ワットモニターを繋いで、以下の3つの状態で簡易的に消費電力を測定し比較を行います。
アイドル時
デモ推論時 (demo_onnx[trt].py/demo_aicast.py): シングルスレッドでの推論
ベンチマーク時(trtexec/hailortcli): 継続的にデータを送るため最も負荷がかかる
$$
\begin{array}{|l|r|r|r|} \hline
\text{デバイス} & \text{アイドル時(W)} & \text{デモ推論時(W)} & \text{ベンチマーク時平均(W)} \\ \hline
\text{Jetson Orin Nano (INT8)} & 6.8 & 8.8 & 12.7 \\ \hline
\text{Jetson Nano (FP16)} & 1.5 & 5.1 & 8.8 \\ \hline
\text{ai cast} & 3.7 & 4.5 & 7.8 \\ \hline
\end{array}
$$
アイドル時の消費電力はJetson Orin Nano > ai cast > Jetson Nanoとなりました。ベンチマーク時の消費電力は Jetson Orin Nano > Jetson Nano > ai castとなり、高負荷時でもai castが最も消費電力が低いことがわかりました。
まとめ
今回は、YOLOX-S-Leakyを題材に、ai castとJetson Orin Nano, Jetson Nanoとの比較を行いました。Hailo-8をAIアクセラレータに採用したai castが低消費電力かつ高性能であることを示すことができました。今回は比較的小さなモデルを動作させましたが、さらに大きなモデルであってもリアルタイム処理が可能であることが見込まれます。
Ideinでは現在、一緒に働く仲間を積極的に募集しています。
当社に興味を持たれた方は是非下記ページより詳細をご確認ください。 ▼Idein採用情報 https://bit.ly/3Ifv0aU
▼Idein採用デック(会社案内) https://bit.ly/3VcTHN1