
なんとなくを全国へ

読む前に
※このnoteはノリで書いているため雑です。
※人によっては不快に感じるかもしれないですがノリなんで許してね☆
※コムレンジャーのほとんどの方は何を書いているかわからないかもしれません。
このnoteを書くきっかけ
ある日、なんとなくTwitterのタイムラインを見ているとコムドットがまた炎上していた。

コムドットといえば【地元ノリを全国へ】をモットーに掲げている登録者300万人越えの色んな意味で話題のYouTuber。今までも度々炎上してネットニュースなどで記事にされている。
炎上した動画
【賞金300万】24時間逆鬼ごっこ〜創造と破壊〜 https://t.co/hh6mTFFz3m
— コムドット (@Comyoutuber2) January 16, 2022
2022年1発目の動画🔥
お待たせしました!!!!!
過去1番壮大な企画と編集💪
みんな見てね🙏🤙 pic.twitter.com/b9rSjYlByA
詳しく調べてはないがどうやら街中をノーマスクで鬼ごっこしたらしい
まぁ個人的にはそれが真実かどうかは割とどうでもよかった。
そのとき「名前忘れたけど発言がとがってるやつがそういえば居たな~」と頭の中をよぎった。そして「そいつのツイートでなんかできるかも…」と思いノリであるプログラムを作った。
ノリでつくったプログラム
概要
ざっくりいうとツイートがコムドットのメンバーの誰かに似ているか判別するプログラムである
ツイートデータを集める
まずはTwitterのAPIを申請しようかと思ったがそんな力を入れて作るわけでもないのにわざわざ英語で申請するのもだるいなぁーと思いながらネットで探してたらあった。
最新のツイートから3200 or 800件のツイートをとれるっぽいのでこれでメンバー五人分のツイートを集める。
集めたcsvファイルがこちら
データ前処理編
まずは集めたデータを見てみる
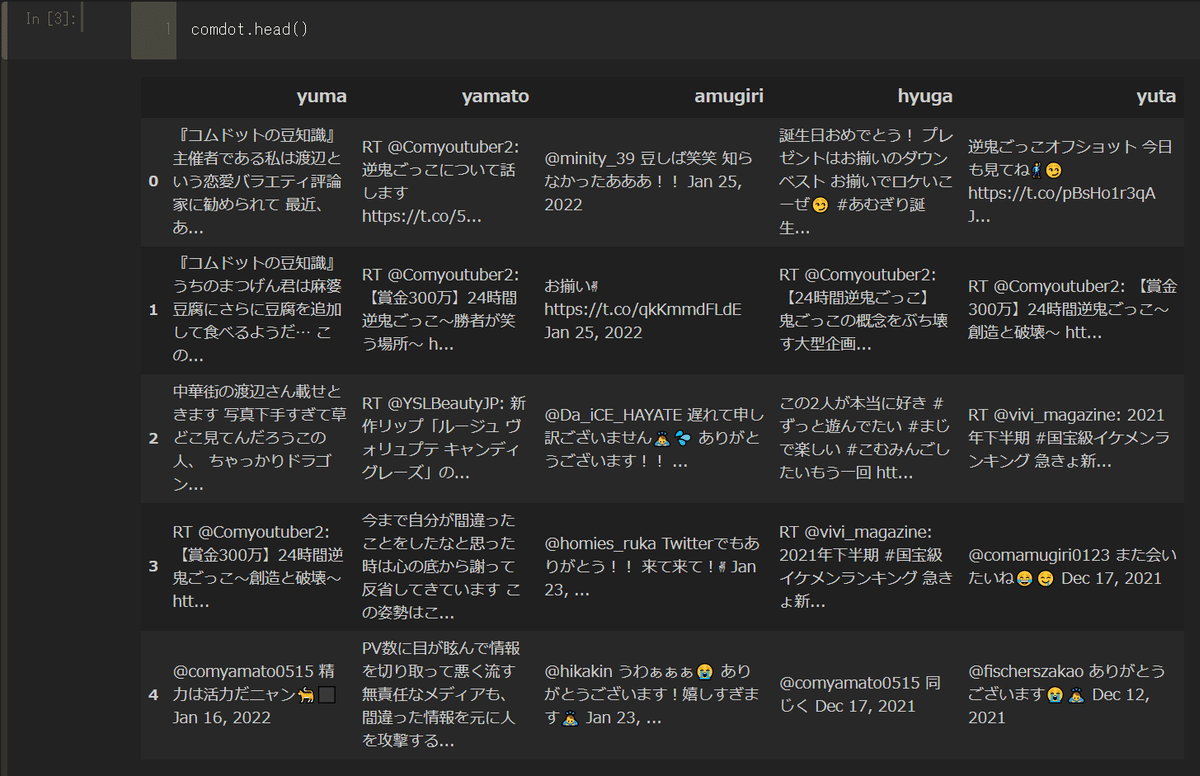
このままじゃ使えなさそうなのでデータを前処理する。
大雑把にしないといけなさそうなこと
先頭に「RT」が入っているツイートの除去
ツイートの後ろにある日付の除去
URLの除去
リプライ先のIDの除去
絵文字の除去
ほかにも突き詰めればやることは色々あるがめんどくさいので省略。
そんなわけでこんな感じの前処理用の関数を作りました。
ところどころエラーに対処するための後が残っており汚いですがお許しください。
#DataFrame渡したら前処理したものを返す
def memberTweet(df):
try:
df_member=pd.DataFrame(columns=['index','tweet','target'])
for target,member in enumerate(df.columns):
df_member_tweet = df[member].dropna()
df_tweet = tweetClean(df_member_tweet,target)
df_member = df_member.append(df_tweet)
df_member = df_member.drop('index',axis=1).reset_index()
except Exception as e:
print(e)
return df_member
#tweetをきれいにする
def tweetClean(tweet_S,target):
try:
df = pd.DataFrame({'tweet':tweet_S,'target':target})
df = df.query('not tweet.str.startswith("RT")',engine='python').reset_index()
df['tweet'] = df['tweet'].replace(r"(https?|ftp)(:\/\/[-_\.!~*\'()a-zA-Z0-9;\/?:\@&=\+\$,%#]+)",
"",regex=True) #URL
df['tweet'] = df['tweet'].replace(r"\@[\w]+","",regex=True) #twitterID
df['tweet'] = df['tweet'].str[:-13] #日付
df['tweet'].astype(str)
df['tweet'] = df['tweet'].apply(lambda x:neologdn.normalize(x))#カタカナを全角、数字を半角など
df['tweet'] = df['tweet'].apply(demojitxt)#絵文字
df['tweet'] = df['tweet'].replace(r"[0-9]+","0",regex=True)#数字半角
df['tweet'] = df['tweet'].replace(r"[0-9]+","0",regex=True)#数字全角
df['tweet'] = df['tweet'].apply(lambda x: leaving_space_between_words_column(x,path)) #分かち書き
df['tweet'] = df['tweet'].str.replace('\n','')
df['target'].astype(int)
except Exception as e:
print(e)
return df
def demojitxt(txt):
try:
txt = demoji.replace(string=txt,repl="")
except Exception as e:
print(e)
print(txt)
return txt
def leaving_space_between_words_column(text,path):
tagger = MeCab.Tagger('-d {path}'.format(path=path))
splitted = ' '.join([x.split('\t')[0] for x in tagger.parse(text).splitlines()[:-1]
if x.split('\t')[1].split(',')[0] not in ['助詞','助動詞', '接続詞', '記号']])
return splittedモデル作成編
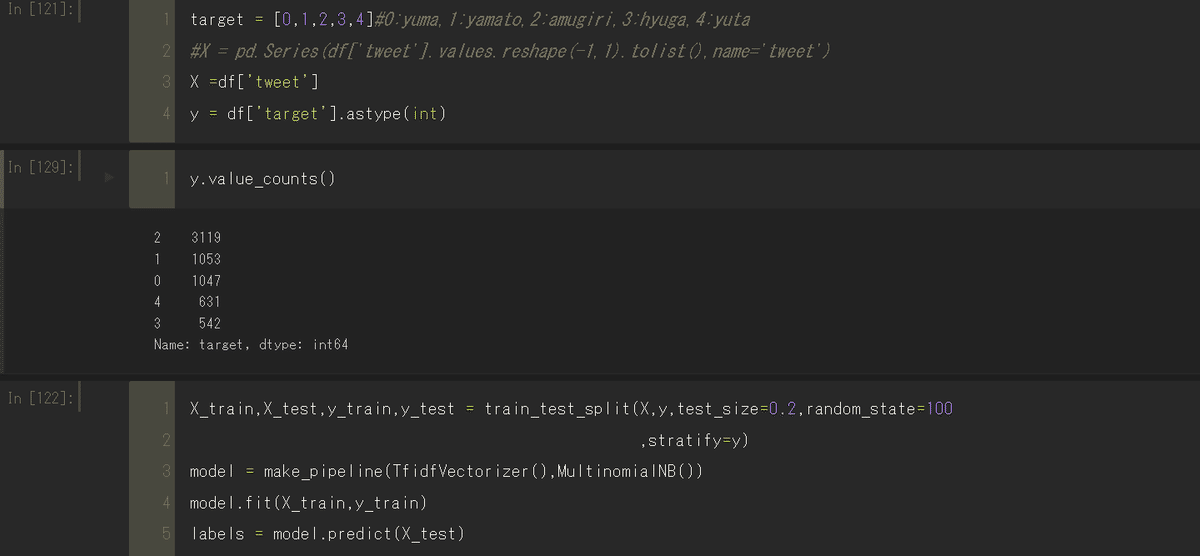
こんな感じでとりあえずパイプラインでtf-idfにわたして多項分布ナイーブベイズで学習。
結果

データに偏りがあったため大体の予想はついてた。
あむぎりさんのツイートがほかに比べ多いのが原因だと思われるので、データの偏りを減らせば多少精度が上がると思われる。
不均衡データの偏りをなくすサンプリングの主な手法は
アンダーサンプリング
オーバーサンプリング
があるがまずはアンダーサンプリングしてモデルを作成していく。
アンダーサンプリングした結果

正解率はアンダーサンプリングしてないモデルより低いけど混同行列を見た感じ前のモデルよりは良さそうかも。
各メンバーのツイート数とリプライ数を比較してみる

なんとなくの考察
アンダーサンプリングしたモデルはしてないモデルに比べて正解率は低いが混同行列を比較して見てみるとアンダーサンプリングしたモデルのほうが上手く特徴を捉えられていることがわかる。
上の画像を見るとあむぎりのリプライ割合は75%でおそらくファンに対して似たようなリプライを返しているため特徴がつかみにくく予測も分散したと考えられる。
ひゅうがとゆうたのリプライ割合は42%と60%でありあむぎりより低いが総ツイート数は542と631で少ないためうまく分類できてないように考えられる。
よくあるデータセットはデータに対して文量が十分あると思うが、ツイッターはリプライなど一言で終わるものが多いため今回のような結果になった可能性がある。
では次にオーバーサンプリングしたモデルを作成していkーー
しかしぬけぢに電流走るーー!

なんでこんなものに真面目にやろうとしているんだ・・・!
そもそもノリで作り始めたのでノリで終わってもいいよね。めんどくさくなったのでこれでひとまずいいかな!
実際に他のアカウントのデータを分類してみる
では実際に分類していくのだが、その前にこの動画を見てほしい
コムドット・やまとの迷名言と彼女のツイートが似ていると思いませんか?
本当はこの人のツイートを全部抽出して分類器にかけてどれぐらいの割合でコムドットのやまとなのか調べるところまでやろうとしたけど精度上げるのめんどくさいし精度が低いままやってもあまり意味ないかなと思いやめた。
やっぱりやる
やち!、キミにきめた!

分類した結果がこちら


なんとツイートの約6割がコムドットのやまとに分類された!
これはもう実質やまとと言っても過言ではないのではなかろうか
尖った発言をする人が無意識に選ぶ言葉があるのかもしれないですね^ ^
今回はめんどくさくてしてないですが自己啓発とかビジネス系のツイートしてる人とかのツイートを分類させてみても面白そう。
とりあえず満足したので次は「コムドット好きそうな人判別モデル」でも作ろうかな。
参考にさせていただいたサイト
自然言語処理における前処理とその威力
正規表現でURLを削除
参考にしようとしたサイト
量的不均衡データに対する学習精度改善のための文書かさ増し手法
感想
あるあるだと思うんですけど頭の中で「こんなの作れそうだな~」って妄想だけして終わることって多くないですか?
今回は妄想を少しでも形にしてみようと思い書いてみました。
ちなみにOSはwindowsでanacondaを使っているんですけど、自分の環境にMeCabのNEologd辞書を入れるのに沼って丸一日かかったのが一番やってて心が折れそうでした。
おそらくコムドット好きそうな人は多分このnoteの最後までは見てないことでしょう。
みんなはコムドット好きですか?ぼくはどうでもいいです。
最後まで見ていただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?