
フルスクラッチ学習に必要な計算機リソース・時間・パブリックライセンスデータ入手先等の参考情報まとめ②

こんにちは!Hi君です。
前回は「参考になるリポトジ・記事」に関してご紹介しましたが、今回は「訓練にかかる時間の見積もり」に関してのまとめです。
訓練に掛かる時間の見積もりについて
まず最初に、Cool Japan Diffusionの「RTX3090で300時間学習に時間を要した」という情報を元に、RTX4090を使用した場合どの程度時間がかかるか、という点について目処を立てる際に有用な情報です。
gtx1070 → gtx1080ti → rtx3090ti → rtx4090で割とパフォーマンス(実際的な画像生成時間にほぼ半比例的な処理能力)が倍になっています。
関連する記事・動画等
イラスト生成AIのStable DiffusionはどのGPUで実行するのが最速か?
画像生成AI用のグラボを選ぶ 【RTX4070TIを買ってしまった!】
Estimating Training Compute of Deep Learning Models
- 一般的にGPUのどのカタログスペックと訓練時間が関連するかという点について言及がある。
- "Method 2: GPU time"あたりが参考になる(ただし、正確ではなく、Vrayベンチマーク等を参考にした方が比率的なオーダーとしては概ね近い)
Best GPUs for Deep Learning, AI, compute in 2022 2023. Recommended GPUs. Recommended hardware for deep learning, AI research

上の情報に紐づくNVIDIA GPUのカタログスペックを複数種類比較しながら検索できるようです。
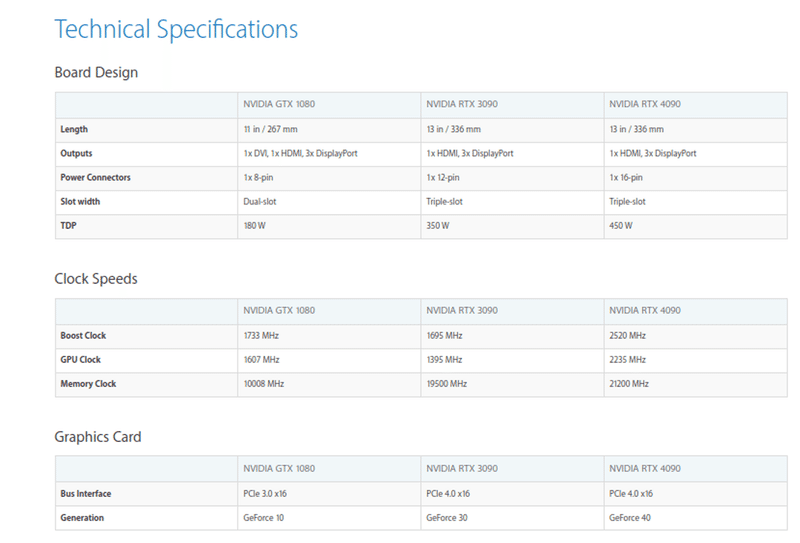
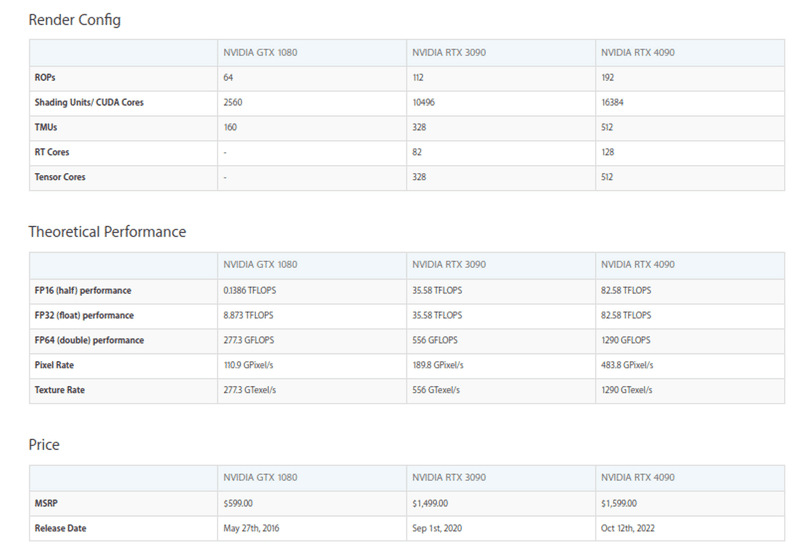
Deep Learning GPU Benchmarksも表示できますが、gtx 1080といった比較的古いモノに関しては情報があまりないのが現状です(恐らくfp16のベンチマークが古いモノだと取りにくい等が考えられます)。

Vray benchmark
こちらはレイトレーシングのベンチマーク結果についてGPUの種類毎に検索できます。
相対スコア比がDeep Learning GPU Benchmarksと近しいようです。
Accelerated Diffusers with PyTorch 2.0/STABLE DIFFUSION BENCHMARK
Accelerated Diffusers with PyTorch 2.0/STABLE DIFFUSION BENCHMARK
以下2つの視点から有用だと判断した情報を明記します。
実際の訓練時間は、対象のアーキテクチャや内部実装に依存する部分が大きい様子。
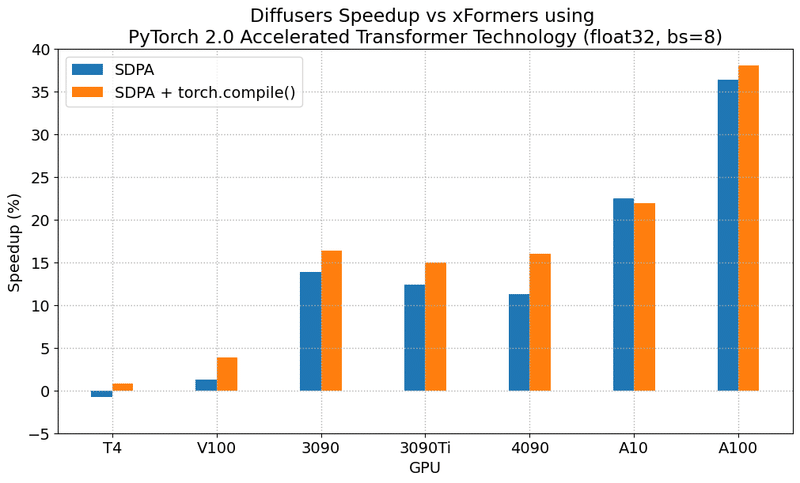
またpytorch 2.0では、attentionモジュールを持っているモデルについて、最近高速化が質良く行われるようになったので、上手く使えばCool Japan Diffusionの結果よりも高速に学習できる可能性があります。特にprecisionやbatch size毎のSpeedup率は参考になると思います。
Results in float32
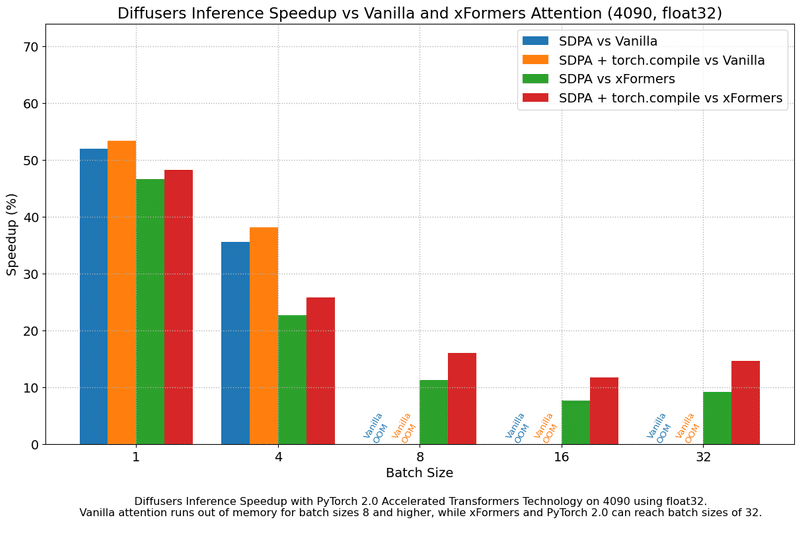
Results in float16
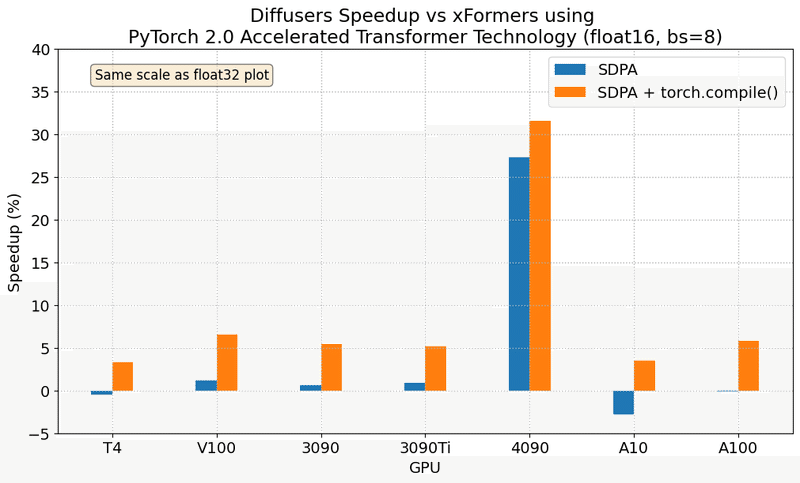
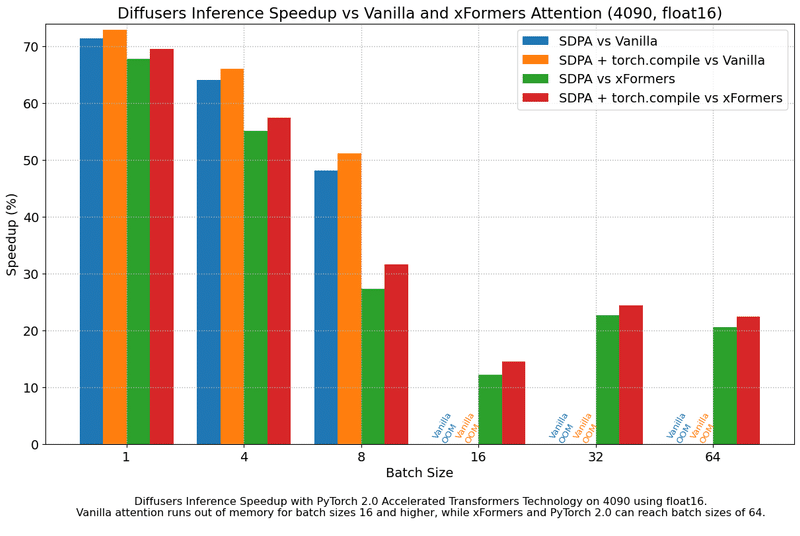
ControlNetやT2I-Adapter等も利用する場合は学習が必要です。また、こちらについてもデータセットを自前で用意する必要があるのでご注意ください。
さて、2回に渡ってフルスクラッチに必要なあれこれをご紹介してきました。
日々進化するAIに置いてかれないよう私も日々勉強していきたいと思います。
文:Hi君
協力:inaho株式会社
この記事が気に入ったらサポートをしてみませんか?