
ポーズ・表情制御に関する手法を調べてみていた

こんにちは!Hi君です!
調べていたのに「古すぎるかな」と投稿を躊躇していたことを公開します。
それは、画像生成におけるポーズや表情制御に関する手法です。
既知という方も、そうでない方も基礎的な情報としてご覧いただけますと幸いです・・・!
memo
「表情制御」(facial expression control)というワードは、GAN系でface meshから画像生成するような手法においてキーワードとしてよく用いられているという印象です。
YouTube
3D POSE & HANDS INSIDE Stable Diffusion! Posex & Depth Map!
mediapipeを使ったfacial mesh認識とcontrolnetを組み合わせようとしている人はいるが、facial expression関連での方法論はまだまだ少ない?
https://www.reddit.com/r/StableDiffusion/comments/11jy7b7/controlnet_models_based_on_mediapipe_prototype/
https://www.reddit.com/r/StableDiffusion/comments/11hx3p1/new_controlnet_models_based_on_mediapipe/
issue
How to apply the OpenPose facial landmarks detection?
Twitterで見つけた参考例
toyxyz3 さん
This time, I tried to control the expressions of the openpose bones more precisely. #stablediffusion #AIイラスト #pose2image #canny2image #MultiControlnet pic.twitter.com/ioP9az9u0h
— toyxyz (@toyxyz3) March 8, 2023


・https://twitter.com/toyxyz3/status/1633569887577837568?s=20
└(おそらく)3Dモデル + Multi ControlNet(canny + openpose)で生成
・https://twitter.com/toyxyz3/status/1629620936537415682?s=20
└ポーズ制御 + 手など細部の描画を安定的に行うために試行錯誤しているツリー


関連記事
4-13. ControlNetのポーズ指定用棒人間アバターをBlenderで作ってみた

[アニメ 3D モデルをFaceBuilder でつくってみた](https://qiita.com/DeepMata/items/b2b325e9e56589a6b662)
関連リポジトリ

facial landmark用のControlNetのカスタムモードを作ったような印象
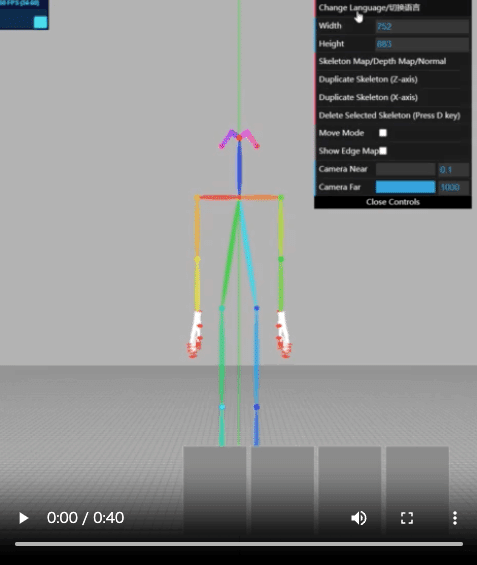
・試してみた動画はこちら。頭身もパラメタ入力できる (ジョイント等をクリックするとBody Parametersが出てくる)

・姿勢のパラメタについて、json形式で読み書きができる(つまり、jsonさえ作ってしまえば理論上外部のモーションデータも適用可能。ただし、各ジョイント情報についてどのようなマッピングになっているか等は要確認)
https://github.com/ZhUyU1997/open-pose-editor/commit/bb096fe1bb7c042336e1a24cfa7c91b87301ef52
現状のポーズ + 表情制御 (+ 細部の小物等の描画)周りについての所感
■リサーチ当初のメモ①
・ポーズモデルと表情(や手・足・細部)を制御する場合、直近で有望そうなのはMulti-ControlNetでのポーズスケルトンと顔等の輪郭についてのエッジ情報を入力するアプローチ
└例えば下に添付したtoyxyz3さんの出力結果
・ただし完全にポーズと表情情報を完全に一貫した形で、素朴にSD+ControlNet等に入力出来るようなプラグインは基本的は無さそう
└理想的には、(”白ハゲ”モデルよりも多少リッチな、ポーズと表情等の輪郭情報が取得できる)3Dモデルがあると良いが一般的には無い + モデル作成は一定の労力が必要
└例えば、スケルトン・手・足については下記のポーズエディタ等存在するが、顔部分の詳細や輪郭については省かれているので(一応耳・目・鼻等の3次元位置の情報は含まれているが)、そのようなエディタを使う場合には、ポーズ情報と表情情報等を後処理で上手くマッチさせる必要がある
▶イラスト用ツールでポーズ情報を見ながら輪郭エッジ部分を上手く位置合わせする等
▶表情情報とポーズ情報の自動マッチ部分については一応手持ちの道具で出来る
・顔についてはキャラごとにかなり個性が出る + ControlNet用のエッジ情報等について一定の精密さが求められる
└一方で、アニメ用途の場合は、ある程度時間的に細かい表情制御が求められる(のではないか)
└頭身や骨格と矛盾が無い形で、顔位置をある程度担保する必要がある。 ポーズ情報と表情情報を上手くマッチさせる必要がある(どの程度厳密性がいるかは場面によるにせよ)
▶例えば表情情報について完全に白紙からの手書き + 逐一ポーズ情報とのマッチングを手動で行うとそれなりに大変
・イラスト画像生成での表情制御については顔面のみfacebuilder等でテクスチャを取得して”白ハゲ”モデルの顔部分に貼り付けたようなモデル(案山子モデルのようなもの)を作るとポーズ + 表情制御 + 動画的生成の上では比較的労力がいらないのではないかと思っている
└ポーズと矛盾しない顔面位置・方向にあった表情情報が、ラフにでも取れれば色々やりやすいのではないか
└顔面の編集はリグを使ってinteractiveにできると思う + モデルのキーポイント情報さえあればポーズや表情についての時系列補完もできると思うので、 動画生成での質感等について時系列的に連続性のある形で適用・生成できる可能性があり、有用ではないか
└toyxyz3さんが取ってるのはおそらくこういったアプローチ
■リサーチ当初のメモ②
・ポーズ付きで一回画像生成する -> 顔部分について輪郭エッジを抜き出す -> 表情を輪郭エッジ画像でガイドしながらinpaintingモードで画像生成する(顔部分の細部を微調整する)
みたいな多段フローでのポーズ/表情指定画像生成のアプローチも一応ありそう?(+ 小物や細部の調整とかも同様の形でも一応できそう)
・適当な画像について線画変換 & 二値化 -> 顔部分のエッジ情報くり抜き(手動) -> ControlNet併用で画像生成を行う事ができる事を確認した。
└ただし、エッジ情報を詳細に描き込んだりControlNet上の重みパラメタを大きくしないと、それなりに生成画像は与えられたエッジ情報からは乖離した画像が生成されやすい(表情は意図したモノだが、微妙に画像上の指定位置に顔が描画されない、目の大きさがそれなりに違う等)
└また、表情的なコントロールの上で多少プロンプト編集が必要(目や口の位置は合っているが、意図した表情をしない場合は多少ある)

・また、SDのOpen Pose Editorやブラウザ上で利用できるopen-pose-editor上では、ポーズ指定を行う際に後段の処理で併用するエッジ画像等を背景にする事ができる。
└つまり、表情・輪郭情報に位置合わせしながらポーズ設定ができる
└逆にポーズ画像を固定して表情・輪郭情報を合わせるためには、現状他の画像編集ツール(gimp, krita等)が必要
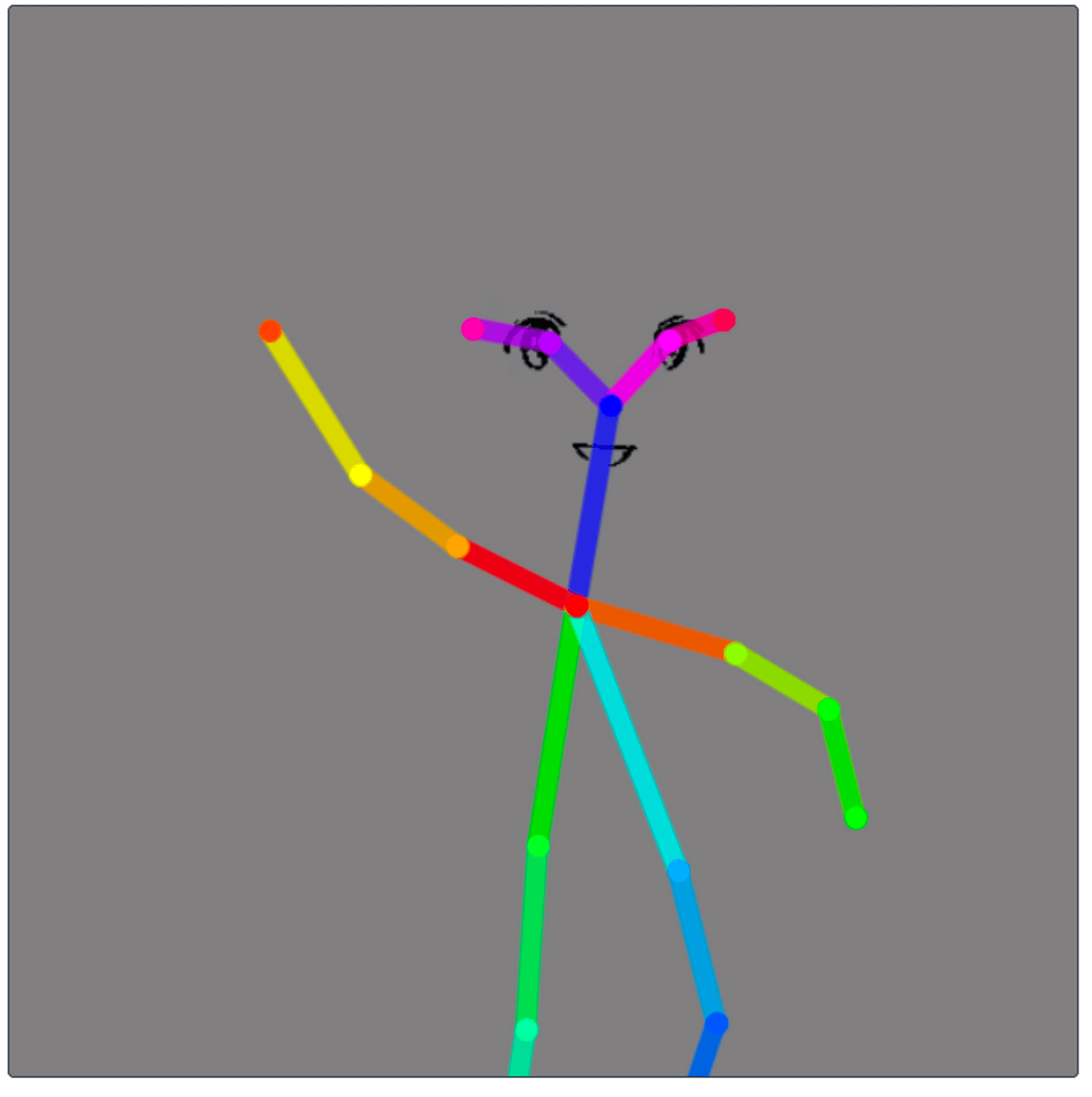
今回は以上です。
少し古い情報となってしまってすみません。もちろんcontrolnet1.1以降も調査はしておりますので、そちらも早めに公開したいと考えています。
次回は画像生成系ではなく「ChatGPT・Large Language Model(LLM)」に関することをまとめてみます!
文:Hi君
協力:inaho株式会社
この記事が気に入ったらサポートをしてみませんか?