
メルカリの検索結果をスクレイピングするプログラミング解説

2024年3月更新
・メルカリのHTML変更及びPandas1→Pandas2に合わせてコードを修正
2023年6月更新
・メルカリのHTML変更及びSelenium3→Selenium4に合わせてコードを修正
メルカリで何か探しているときに、目当ての出品物が見つかるまでひたすら検索結果を見るのは大変だなぁ…と思ったことはありませんか?
カテゴリによっては結果一覧が何ページにも及ぶ場合があるので、お目当ての出品物を見つけるのはとても骨の折れる作業ですよね…
でも、もしあなたがPythonの基本的な知識をご存じなら、簡単なプログラミングを組むだけで
『スマホでいちいち検索しなくても、検索したい商品一覧をゲット』
できてしまうツールが作れるんです!
今回は、そんな自動化ツールの作り方をご紹介します(^_-)-☆
こんな方におススメ(*´▽`*)
・探したい商品の金額を一覧で表示して、興味がある商品だけ確認したい
・ブラウザを自動で動かしてみたい
・Pythonの基本的な知識で、生活の役に立つアプリを作りたい
概要
実行するツールは、次のような流れになります('ω')
1、検索したいキーワードを決める
(複数キーワードの組み合わせもできます)
2、プログラミングコードを実行
~~終了するまでしばらく待つ~~
3、終了後、取得した結果がCSVファイルで表示される
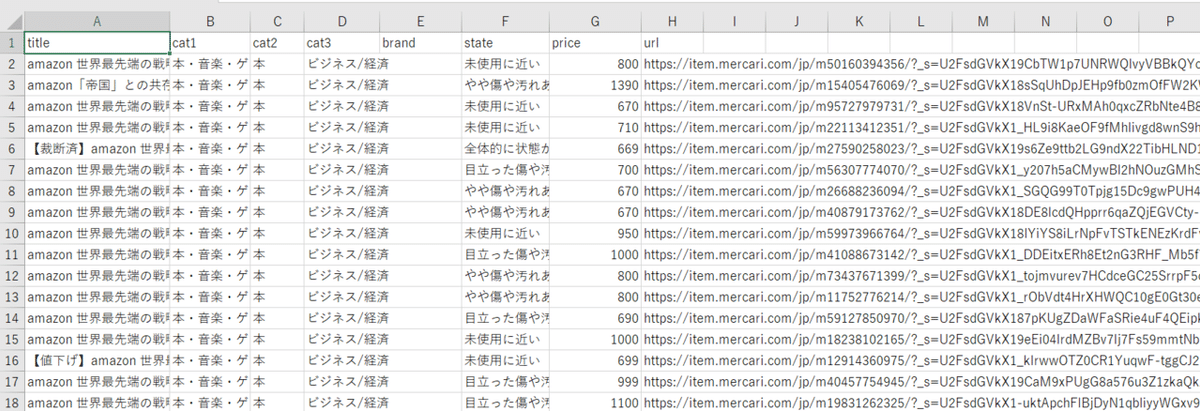
検索結果の詳細ページから以下の情報を取得
①タイトル
②カテゴリー
③ブランド
④商品の状態
⑤金額
⑥詳細ページのURL
なお取得したい情報は、この後紹介するソースコードを編集することで簡単に増減できますので、みなさんの知りたい情報が取れるようカスタマイズしちゃってくださいね(#^.^#)
今回のツールの仕組みをもう少し詳しく言うと、
PythonのライブラリーであるSeleniumを使い、ブラウザを自動で実行することにより、検索結果を自動で取得して、取得した結果をCSVで書きだす。
ということをやります。
完成したpythonファイルを実行してみるとどんなことができるのかイメージしやすいと思いますので、まずは試してみましょう。
実行するには、コンソールを立ち上げて、次のように入力します。

まず、cdで実行したいファイルがある場所に移動します。
そして、"python ファイル名 検索キーワード"を実行すると実行されます。検索したいキーワードが複数ある場合は全角スペースで空けて、複数キーワードを入力してください。
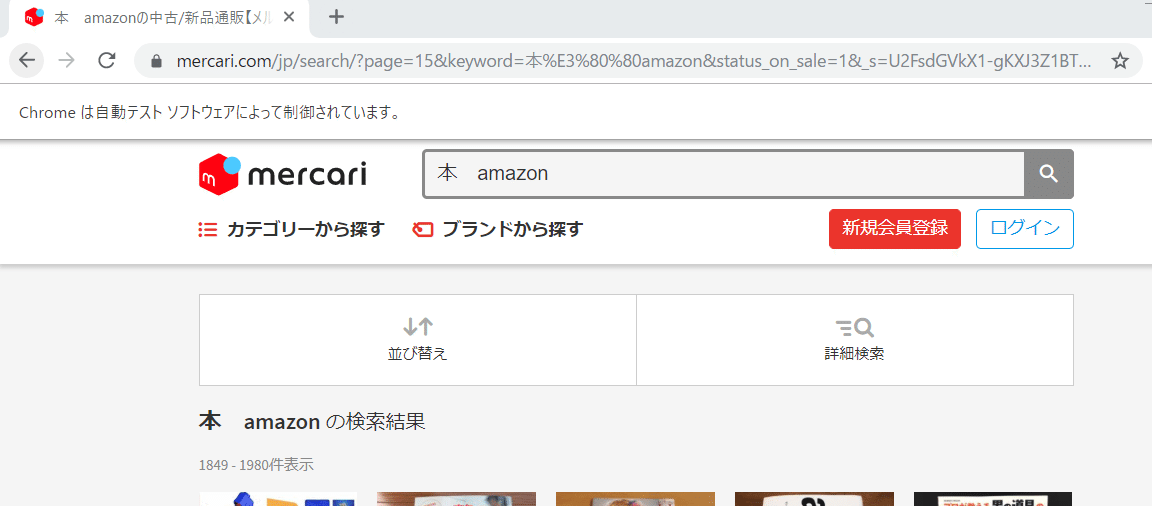
上記の画像のようにブラウザが立ち上がり、自動で情報を取得します。取得の途中経過がわかるように、コンソール上でも取得状況がわかるようにしています。
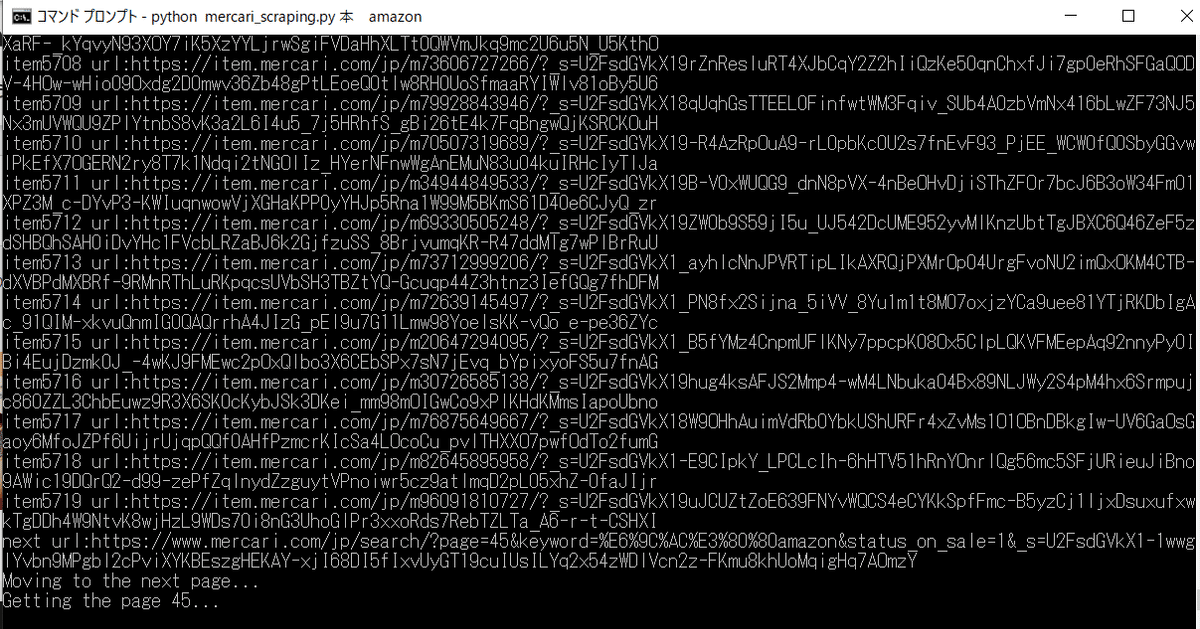
終了すると次のようなCSVファイルが生成されます。
ぜひ試してみてください!
『検索結果を自動で取得』するということをやりますが、今回のカギとなる技術は、
Webスクレイピング(Web Scraping)と呼ばれるものになります。
Webスクレイピングとは、Webサイトで公開されている情報を取得する技こと。今回はメルカリ上の出品物が取得する情報に当たります。
このスクレイピングはPythonの代表的な活用方法の一つで、HTMLやCSSをちょっと知っていれば難しくないので、Pythonの基本的な知識を一通り身に着けた方が実践するにはちょうどいい練習になります。
ただしHTML、CSSを組む訳ではないので、これら言語をよく知らないという方も難しく考えなくて大丈夫です!
"Selenium"は、 Pythonでブラウザを自動で動かすライブラリーで、今回はそのライブラリーを使って、スクレイピングをします。
スクレイピングに関しては他にも"Requests"という有名なライブラリーが存在するのですが、それぞれにメリット・デメリットがあります。
一言でいうと、"Requests"の方が高速だけど、認証でつまずく場合が多い。逆に"Selenium"だとブラウザを動かすから低速だけど、ログイン操作などもできるというイメージ。
今回は"Selenium"の方を使って説明していきますね(^^)
もし、スクレイピングが初めてという方はこちらの記事を先に読んでみると理解しやすいと思います。
全体の流れを決める
まずはざっくりとどんなことをやりたいのかを決めます。
・seleniumでブラウザを実行して、メルカリのサイトから情報取得
・メルカリの検索結果のURLを確認
・検索結果の一覧ページから各商品の詳細ページのURLを取得
・各詳細ページから取得したい情報を取得
・最後にCSVで出力
それでは、順番に解説していきます (*^^)v
1. seleniumの実行環境を作る
import sys
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
まずはライブラリーをインストールします。
"sys"は、コマンドラインでpythonを実行するためのライブラリー、"time"は『(特定の)時/分/秒』を表現するためのライブラリーで、いずれもPythonに標準で実装されています。
そして、"Selenium"の中で、今回は"webdriver"を利用します。"webdriver"はブラウザをプログラムで外部から操作するためのライブラリーです。ほかにも今回のプログラムの中で使う"Service"、"By"、"NoSuchElementException"の3つをインポートします。
ここから先は
¥ 1,200
この記事が気に入ったらサポートをしてみませんか?