
自然言語処理⑪~Transformer・BERTのためのAttention理解と実装に挑戦その1~

Transformer とかBERT とか聞くと、自然言語処理の本丸に近づきつつありますね。
TransformerはもちろんBERTやらGPT-nでも使われてますが、画像処理のViTなどでも使われている優れものです
BERTの実装くらいまでは自然言語処理を扱おうと思っているので、もう少々自然言語処理が続くかなと思います。
今回は、TransformerやBERTの背景にあるAttentionという理論(や数式)を理解して、実装を始めていく回となります。
この辺をがっつり理解しなければ実装できない、っていうわけでもないとは思います。
(ちゃんと理解するには論文読む必要とか出てくる。そうなると、詰みますので、私が。)
その後に実装(公式のチュートリアルから)も複数回にわけて見て行きます。
とても長いですし、毎回えげつない実装をすることもないですし、自分も普通にスラスラかける内容では到底ないですw
が、通しでみることで理解を深めて行きましょう
では、今回もよろしくお願いいたします。
・Attentionを理解する
前回まではRNNを中心に時系列を加味することによる学習で文章を予測したり生成したりしました。
このAttentionでは、まず文章をエンコードするわけですが
Bi-GRU(※)が使われます。
(※GRUは一方向で、文頭から文末へ情報を保持しつつ出力を計算していました。そこに、文末から文頭へ逆に移動して、最初の単語を予測するようないわば逆GRUも使うことで、各単語の前後をみた上でのベクトル化をすることができる)
このエンコードにより、
次元dのベクトルx_i(i=0, ..., T )というT+1個のシーケンスを得られたとします。
ここからデコードしていくのですが、このときにAttention値というものを利用するのがAttentionとなります。
(古典的なAttentionについて)手順を書くと以下。
①x_iとそれ以外のx_jの類似度を内積で算出(これをw_ijとする)
②そのw_ij全てをソフトマックス関数(前回解説しました)で正規化
(W_ijとする)
③この重み行列W_ijとx_jをかけたものをj=0~Tの総和をとる
順番に見て行きます。
①x_iとそれ以外のx_jの類似度を内積で算出(これをw_ijとする)
まず、対象となるx_iベクトルとそれ以外のベクトルx_jの類似度を内積により計算します。
内積を計算するというのは、意味が近しいベクトル同士は大きくなり、遠いものは小さくなる性質があります。
(確かword2vecでコサイン類似度を話した記憶。。)
これをw_ijとします。
②そのw_ij全てをソフトマックス関数(前回解説しました)で正規化
(W_ijとする)
x_iに対して他の単語全ての類似度を計算して、w_ijを準備すればそれらをsoftmax関数に当て込みます。
W_ij = softmax(w_ij)
つまり、ΣW_ij = 1となるため、正規化された状態となります。
前回softmaxは確率にできる話をしましたが、正規化する(要素を0~1の範囲にする)用途としても使うことができます。
③この重み行列W_ijとx_jをかけたものをj=0~Tの総和をとる
そして、最後に出力o_iが欲しいので、
o_i = ΣW_ij * x_j (j = 0 ~Tで総和)
として計算します。
このW_ijはいわば重みですから、o_iでは類似度の高い部分が大きく、類似度の小さい部分は数値的に小さくなるように重み付けされて出てきます。
つまり、注意を払って欲しい(pay attention)単語(意味)にマークをつけるイメージです。
ちょっと数式的な部分を言えば、x_iとo_iの次元は変わっていないため、なんか入力があれば、返ってきた時にはマーカーが付いている感じ。
これが基本的なattention(self-attention)です。
もう少し踏み込みます。
・Attentionのスケーリング
上記のAttention値を見ると、
入力シーケンス(x_i)のみでAttentionの値が「勝手に」決まってしまいます。
精度上げるために学習したい!ってなっても、
「いやいや入力の文章だけで決まりますさかい、学習できませんで!」ってなります
学習させるためには、そもそもの入力を工夫する必要となりますので、そこでうまい具合にスケーリングしようよ!っていう考え方が出てきます
(Scaled Dot-Product Attention)
具体的に3つのパラメータ:query, key, valueというものが出てきます。
(以下、厳密性よりイメージのしやすさを重視しているため、厳密性を求める場合は論文を読む方がいいかなとおもいます。。)
順に見て行きましょう。
- query
さきほどのx_iという入力ではなく、
q_i というqueryを用いるのですが、簡潔に言えば入力です
(細かく言えば、検索したいもの)。
となります
- key value
次にkey とvalueですが、これはdict型のkey valueの関係のように、あるkeyに対してvalueが対応している(k-vector: v-vector)ものがm個あるものです。
・・・
そして最初のAttentionの手順を踏みます。
まず内積を計算するのですが、今回はquery とkeyを用います。
w_ij = q_i・k_j
k_j: keyのj番目のベクトル
※表記は厳密ではないです
これにより、queryとkeyの類似度がわかります。
次にsoftmaxを使いますが、その前にkeyの次元√dで割ることにより、スケーリングします。
w_ij -> w_ij / √d
なぜにこんなことをするのかと言えば、次元dが大きくなると(要素を足し合わせるので)内積の値が自然と大きくなりがちになることを防ぐためです。
純粋な類似度が次元数に影響しないように補正しているイメージ。
で、softmax。
W_ij = softmax ( w_ij / √d )
で、最終的なAttention値は
Attention = softmax(Q K_T / √d) V
Q: 横ベクトルq_iをまとめたもの
K_T: k_iベクトルをまとめた行列の転置
V: valueベクトルをまとめたもの
となります。
「まぁ、そうなんだ」くらいでいいと思いますw
・MHA
この学習できるようになったモデルの理解のためにMult-Head Attentionというものを理解する必要があります。
これがtransformerの中で使われている理論の一つとなります。
その前にheadというものがあります。(表記の関係で厳密さのかけらもないですw)
head_i = Attention(Q*W_i_Q, K*W_i_K, V*W_i_V)
W_i_~: ~に対応する行列。
ちなみに、このhead はベクトルです。
この中身を踏み込むのも悪くはないのですが、端的に言えばそれぞれの行列をかけることでquery, key, value達を「回転」させた上でAttentionを計算しています。
(どの回か忘れたのですが、行列が回転をイメージするものっていうの書いた気がします。)
で、ざっくり言えば、
これらを計算することで、どの情報が重要なの?っていうのを出してくれます
このhead_iベクトルを全てのiで計算し、繋げたもの(concat)をzとして出力に対応した行列W_oをかけたものが出力に出てきます
o_i = W_o * z
・結局??
簡単にまとめると、
類似度をとにかく多面的に計算して、どの情報が重要なのかを自ら処理して行き、それを何層にも積み上げることで高度に言語処理や画像処理ができるようになる
ってのがAttentionとtransformerの背景となります。
今回厳密性を加味してない表現を用いているので、正確な理解をするには他のサイトとかの方が優れていますので、導入の導入、くらいのスタンスかなと思います。
実装でもまたみて行きますので、一旦進めましょう
・Transformerの実装その①
では、上記をふまえつつ実装してみましょう
以下の公式チュートリアルに準拠して書きます。
今回はポルトガル語→英語の翻訳となります。
できる限りコードを都度解説するスタンスは崩さないですが、そもそもの理解が何回であったりする部分は適宜自白しますw
では、行きましょう。
・Transformer 実装のデータ準備
まずはtfdsにある英語とポルトガル語に翻訳された文章をloadして行きます。
では、みて行きましょう。
!pip install -q tf-nightly
import tensorflow_datasets as tfds
import tensorflow as tf
import time
import numpy as np
import matplotlib.pyplot as pltexamples, metadata = tfds.load('ted_hrlr_translate/pt_to_en', with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']ちなみに、metadataにはこのデータに関する情報が記載されているので、みておきましょう。

小さいですが、特徴量としてen, ptがあり、データ種類としてtrain ,validation, testが用意されていますね。
次にSubwordTextEncoderを用います
これいわゆるencode, decodeするものくらいの認識でおけです。
build_from_corpusで情報を読み取り、decode, encodeメソッドで数値的に解釈もしくは翻訳するという関数が使えます。
まずはコードとその例をみてみましょう。
tokenizer_en = tfds.features.text.SubwordTextEncoder.build_from_corpus(
(en.numpy() for pt, en in train_examples), target_vocab_size=2**13)
tokenizer_pt = tfds.features.text.SubwordTextEncoder.build_from_corpus(
(pt.numpy() for pt, en in train_examples), target_vocab_size=2**13)sample_text = 'Transformer is awesome!'
encoder = tokenizer_en.encode(sample_text)
print('Tokenized string is {}'.format(encoder))
decoder = tokenizer_en.decode(encoder)
print('Original string is {}'.format(decoder))
assert decoder == sample_text![]()
- おまけ

ここで飛ばした(というか、いずれ書くつもり)文字レベルの予測モデルをLSTMで作成するときにindex - > character, character -> indexという辞書的な対応表を作る工程が必ずあるのですが、それに近いですね。

次にmapメソッドで要素をすべてencodeしたいのですが、tensorflow特有の問題でmap関数ではテンソルの直接的な値(.numpy()で参照するような値)を取れないという問題があります(たしかEager Executionとかいうやつ。詳しくないです)
そのため、py_functionメソッドを使うことによってラップしてmapメソッドを使う必要が出てきます。
まずは適用したい関数を準備します。
def encode(lang1, lang2):
lang1 = [tokenizer_pt.vocab_size] + tokenizer_pt.encode(lang1.numpy()) + [tokenizer_pt.vocab_size + 1]
lang2 = [tokenizer_en.vocab_size] + tokenizer_en.encode(lang2.numpy()) + [tokenizer_en.vocab_size + 1]
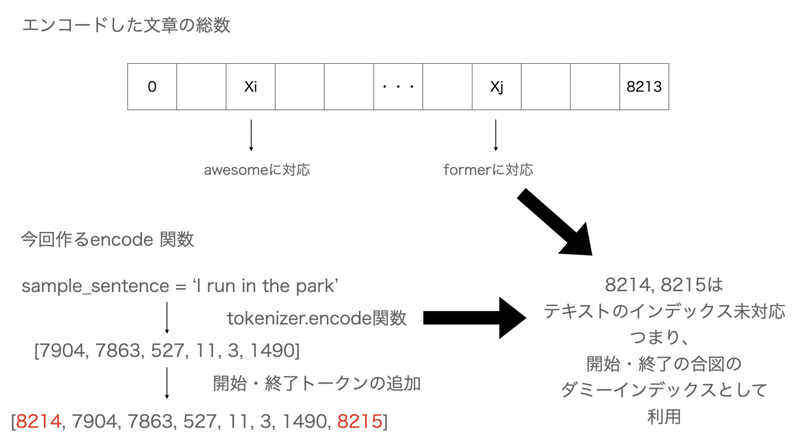
return lang1, lang2これ、どういう関数なのかというと、コードをみると、ptの単語数である8214という数値と+1した8215を開始・終了インデックスとして適用し、リストでエンコードした文章(つまりインデックス番号)を順に格納するものです。
インデックス=8214というのはvocab_sizeで確認できます。

インデックス8214というのは存在しないため、開始・終了トークンとして定義できるのですね。(tokenizer_pt.encode([8213])が最後なので)
しかし、これは直接trainデータなどには使えないため、使えるようにするため py_function 関数を中で利用するための関数を準備します。
- 公式のもの
def tf_encode(pt, en):
result_pt, result_en = tf.py_function(encode, [pt, en], Tout=[tf.int64, tf.int64])
result_pt = tf.ensure_shape(result_pt, [None])
result_en = tf.ensure_shape(result_en, [None])
return result_pt, result_enpy_functionを使うことによりmapで扱えない.numpy()を呼び出してくれる良いうになりました。
- 自分で書いたコード
def tf_encode(pt, en):
result_pt, result_en = tf.py_function(encode, [pt, en], Tout=[tf.int64, tf.int64])
result_pt = tf.ensure_shape(result_pt, [None])
result_en = tf.ensure_shape(result_en, [None])
return result_pt, result_en公式ドキュメント的に、.set_shapeからensure_shapeを使いましょう的なことが書いていたので、一応そっちでも書いてみました。
ちなみに、このset_shape, ensure_shapeはshapeをアップデートするもので、形状確認やらランタイム確認とかするものらしいのですが、使い所はピンときてないです
次に40トークンを超えるサンプルの削除をします(サンプルを小さくすることと、処理を速くするため)
MAX_LENGTH = 40
def filter_max_length(x, y, max_length=MAX_LENGTH):
return tf.logical_and(tf.size(x) <= max_length, tf.size(y) <= max_length)logical_andは中に格納した条件をandで判定し、最終的にbooleanで返します。
ちょっとこの関数を試しに見てみましょう。

では関数が揃ったので、訓練用・検証用のデータセットを作成します。
BUFFER_SIZE = 20000
BATCH_SIZE = 64
train_preprocessed = (
train_examples
.map(tf_encode)
.filter(filter_max_length)
# 読み取り時間を上げるため、キャッシュに全て載せる
.cache()
.shuffle(BUFFER_SIZE)
)
valid_preprocessed = (
val_examples
.map(tf_encode)
.filter(filter_max_length)
)特にcache関数とか使っていますが、必ず使わないといけないわけではないので、一旦進めます
train_dataset = (train_preprocessed
.padded_batch(BATCH_SIZE)
.prefetch(tf.data.experimental.AUTOTUNE))
val_dataset = (val_preprocessed.padded_batch(BATCH_SIZE))padded_batchにより、指定したデータセットの中の一番長いトークンにサイズを合わます(0埋め)。画像の0-paddingと同じイメージくらいでいいと思います。
(prefetchは簡単にいえばデータ処理を効率的にするため、一気に読み込むのではなく、モデルの処理実行と前処理を同時に行うもの)
ちなみに、trainデータにはpt, enの二つあるため、datasetはそれぞれtupleにすることで分離させています。
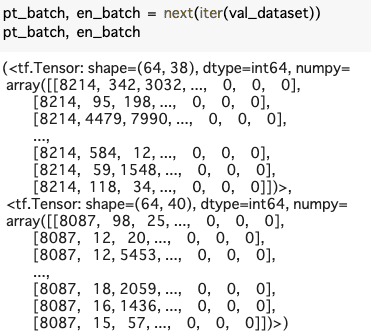
試しに一つ見てみます。
(またもiter関数が出てきましたねw)
開始トークンがちゃんと格納され、後ろは0パディングが施されていることが分かります
- Positional Encoding
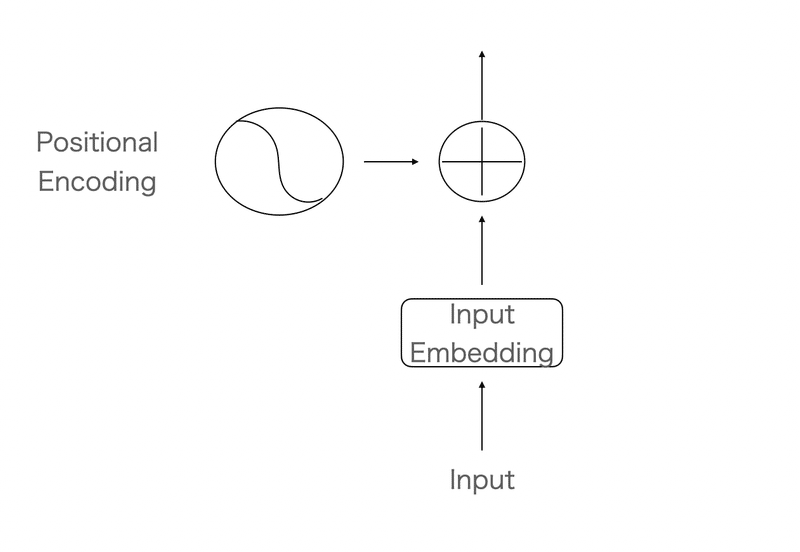
transformerの論文にある図で、最初にEmbeddingの埋め込みとPositional Encodingにより入力の処理を行います。
(いわゆる単語を定量化したものと、文章における単語の位置情報を持たせてAttentionを計算させにかかる)
Embeddingはいわゆる単語数で膨大に増える次元数を圧縮して表現するもの、くらいでおけです。
なんで位置情報がいるのか?ということですが、transformerにはRNNやCNNを使わないため、時系列的にどう影響しているのかがわからないまま進めることになります。
そうなるとただ単語を集めただけのものをNNに入れると何がなんやらって感じなので、位置情報を与えることで位置的な観点からどの単語がどの単語に影響しているのか?というものを理解させるようにします。
余談ですが、tensorflowの位置エンコーディングのノートブック参照したかったのですが、消えてた。。
なので、どのようにして導出されているのかわかってないです。
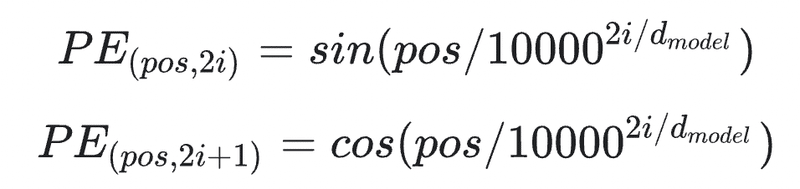
(引用元↓)
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates(np.powerは累乗のこと)
i番目が奇数・偶数でcos, sinの適用が使い分けられているので、別々にみて行きます。
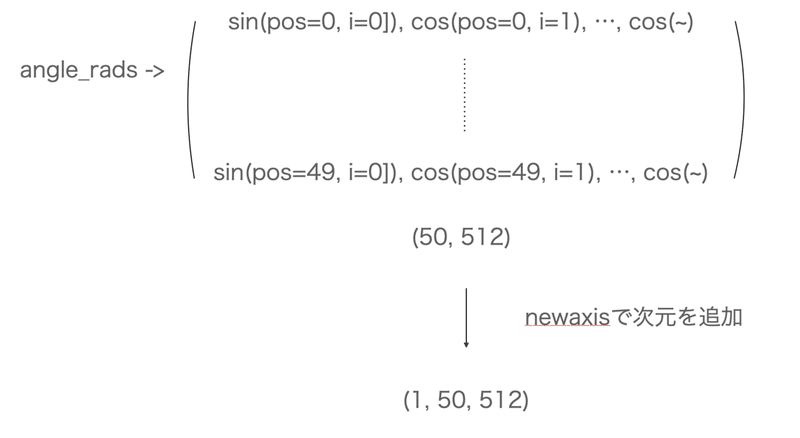
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# 偶数インデックスにはsin
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 奇数にはcos
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)グラフにしてみてみる
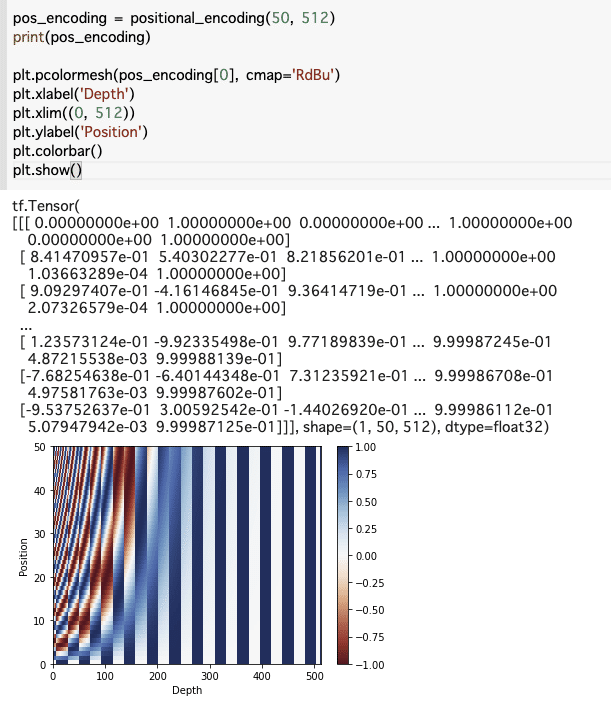
このコード、何をしているのか図示して理解してみます。

それぞれのpositionに対して埋め込みされたd次元分に対してそれぞれpositionごとに位置エンコーディングで計算された値がsin, cos, sin, ・・・と順番に格納されて行きます
(ちなみに私は実践でnewaxisを使う状況に出会ったことがないため、発想がすごいって思わされますw)
・Masking
次に0-paddingされたトークンをマスク(隠す)します。
今、トークンの長さを全て均一に認め、ほとんどの行の後半には0埋めがされています。実際に0の部分は1を、その他は全て0を出力するような関数を作成します。
これを実際に使うのは後半なので、今はサラッと紹介だけになるかなと思います。
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# アテンション・ロジットにパディング(?)を追加するため
# さらに次元を追加する
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)このcreate_look_ahead_maskですが、例えば3つ目の単語は1, 2つ目の単語から参照してもらうように制限するコードです。
・一旦終わり
疲れたので、一旦この辺にします
続きはこのマスキングをちゃんと扱うところから始めます
この記事が気に入ったらサポートをしてみませんか?