
AUTOMATIC1111 Ver1.7.0の個人設定

こちらは先日アップデートされた AUTOMATIC1111 Ver1.7.0 の個人的な設定や、拡張機能の覚書です。
以前の記事に乗せていたのですが、Settingの項目が大幅にリニューアルされまして、同じ設定をしようにも迷ってしまいましたので、改めて書き出しておこうと思います。
今後も 1.7.0 の間はこちらの記事で内容更新するつもりですので、たまに覗いて頂けると、なにか変わっているかもしれません。
では、前回と同じように順番にご紹介していきますね。
目次ジャンプも有効に使って頂けると嬉しいです。
1⃣ WebUI の setteing 部分
・画像のファイルネームを変更する
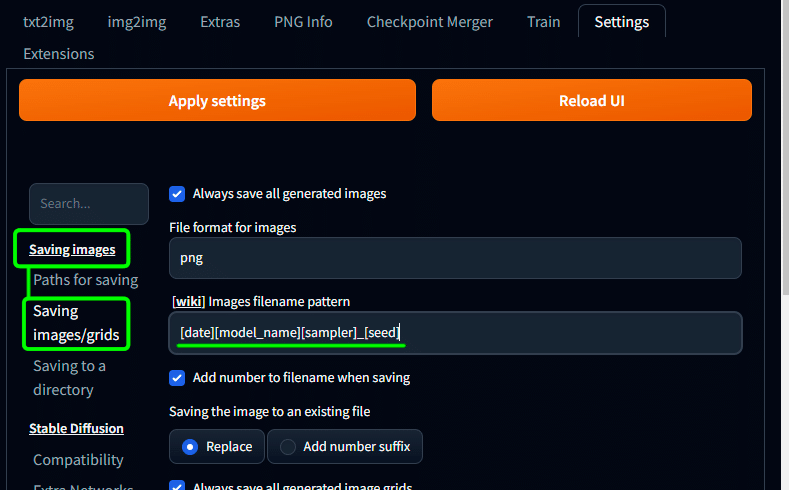
Saving images 内の Saving images/grids の
[wiki] Images filename pattern に
[date]_[model_name]_[sampler]_[seed]とコピペする。
これで画像生成した際に画像の名前が
【日付】【モデル名】【サンプラー】【seed値】になります。
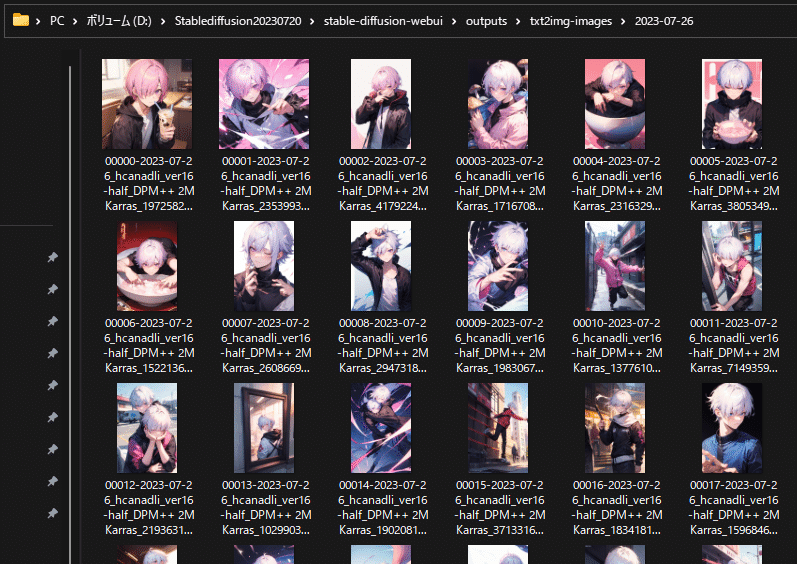
画像の詳しい内容はWebUI内の PNG Info タブに放り込むことで詳しく見ることができるのですが、このあたりの情報はファイル名で見れるようにしておくと、あとあと便利だったりします。
他にもいろいろな内容でカスタムできますので、以下のページで確認してください。
・大きい画像の場合にJPG画像も保存するのチェックを外す
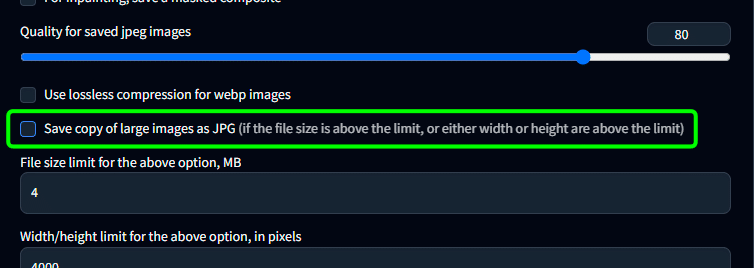
Saving images 内の Saving images/grids の
Save copy of large images as JPG(以下略) のチェックを外す
普段はPNGで画像を生成していますが、これにチェックが入っていると、大きな画像を生成した際にコピーを JPG としても保存されてしまいます。
よほどメモリが苦しい場合は有用なのかもしれませんが、ぱっと見どっちがPNGなのかわからなくて面倒なので、私は切っています。
ちなみに、PNGは画像劣化の少ないファイル形式で少し重いですが、jpegは独特の画像劣化のある軽いファイル形式です。
・メイン画面上部で選択できるサンプラーを選別する
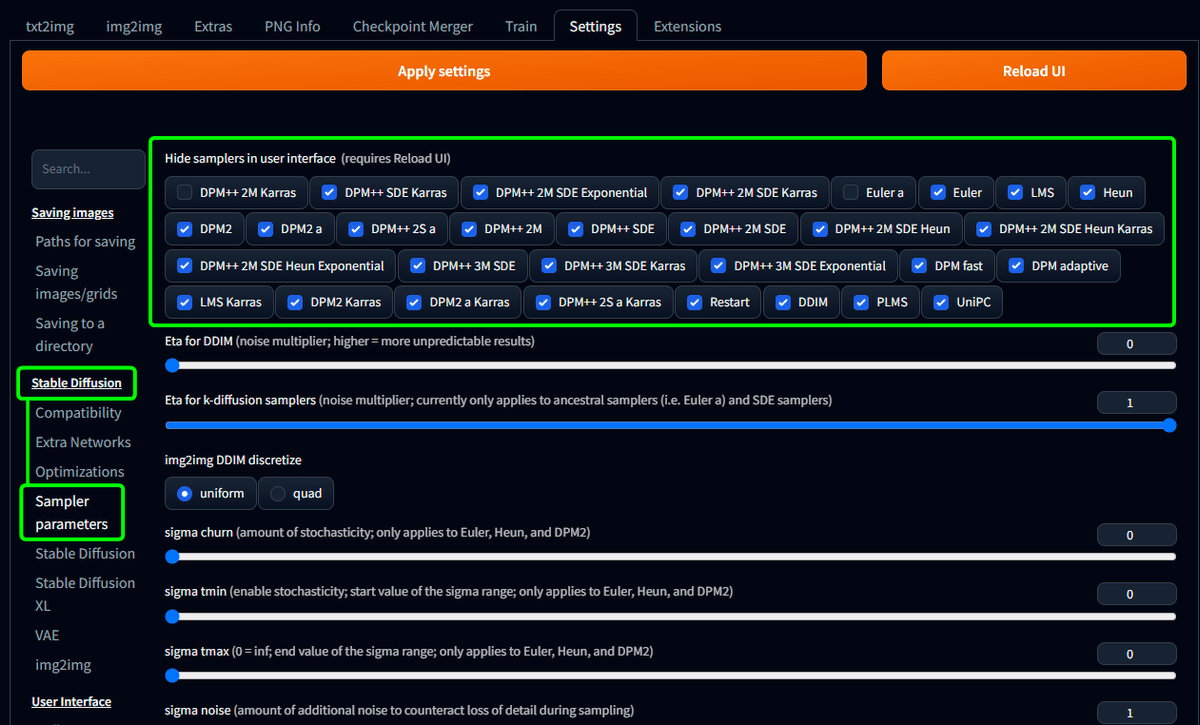
Stable Diffusion 内の Sampler parameters で
使わないサンプラーにチェックをつけていく。
Stable Diffusion ではサンプラーというものがありまして、それごとに絵の描き方が違ってきます。
結構な数があるのですが、ここでチェックを入れたサンプラーは非表示にできますのでやっておきましょう。
サンプラーに関しての詳しくは hoshikat さんのblogをご覧いただければと思います。
・Img2Img の際に色を元画像に寄せて自動補正する

Stable Diffusion 内の img2img の
Apply color correction to img2img results to match original colors.
にチェックをいれる。
画像にノイズを加え直して、もう一度書き直す機能を Img2Img といいます。
想像しやすいように言うと、画面全体を一度ボカシてからもう一度絵に直す感じで、その際に少しずつ周りと色が混ざってしまうため、使用するたびに絵の彩度が落ちていく場合があります。
ここのチェックを入れることで、生成し直した最後に、元の絵の彩度に近づける処理を入れてくれるため、画像の彩度がどんどん落ちてしまうのを抑制してくれます。
私はTxt2Imgでベースを作成したあと、Img2Imgを何度も繰り返したり合成したりして絵の完成度を上げていく方式を取っていますので、彩度が毎回落ちてしまうのは致命的でした。
この設定を覚えたことで、かなり楽になったのでお勧めしたい設定です。
・Hires.fix の UI 部分を拡張する
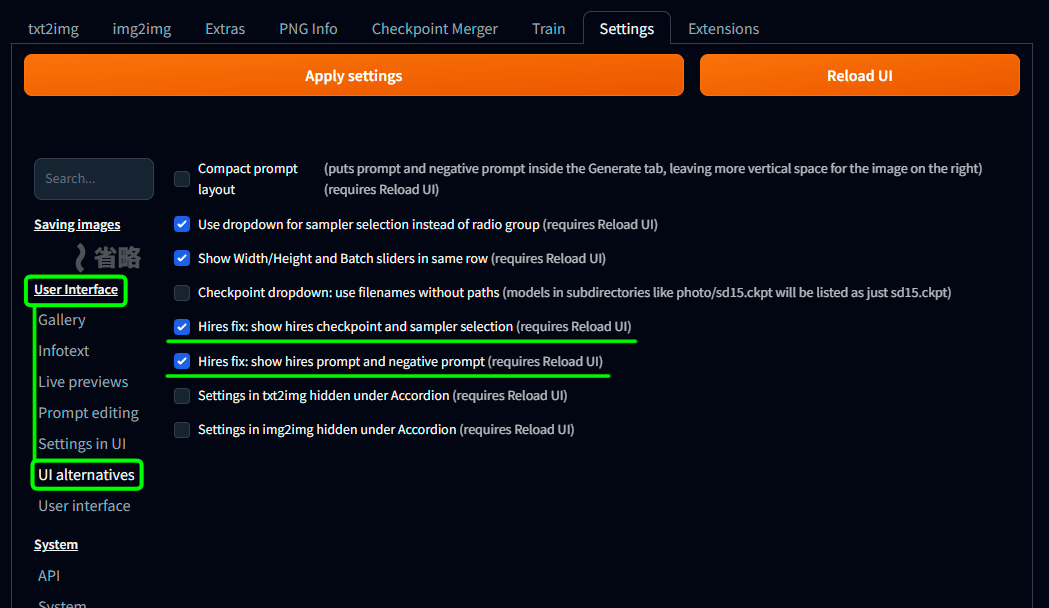
User Interface の UI alternatives にて
Hires fix: show hires checkpoint and sampler selection
Hires fix: show hires prompt and negative prompt
にチェックを入れる。
これを入れることで、txt2img で Hires.fix を ON にした時、
Hires.fix の際にも改めて チェックポイント や サンプラー 、
そして プロンプト & ネガティブプロンプト を設定できるようになる。
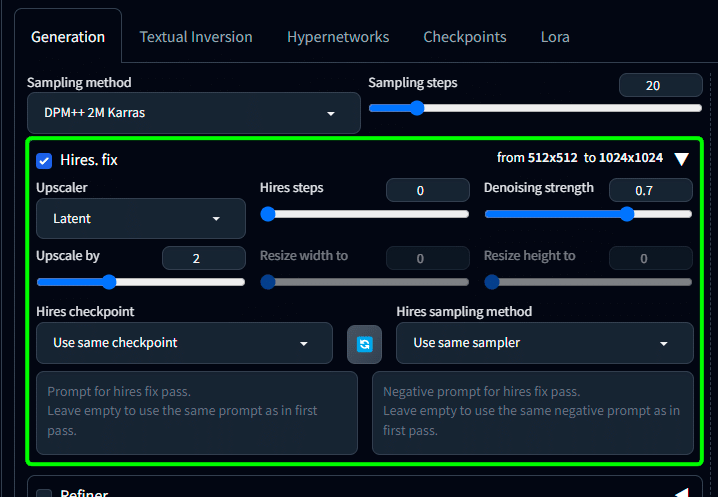
絵柄LoRAを最初から使うと全体の絵の構成自体が変わってしまう事があるが、これを使うことで前半はモデルの真骨頂を出した上で、アップスケールの際に絵柄を適用するといった事が1度でできるようになる。
・メイン画面上部で Clip skip と SD VAE を選択できるように
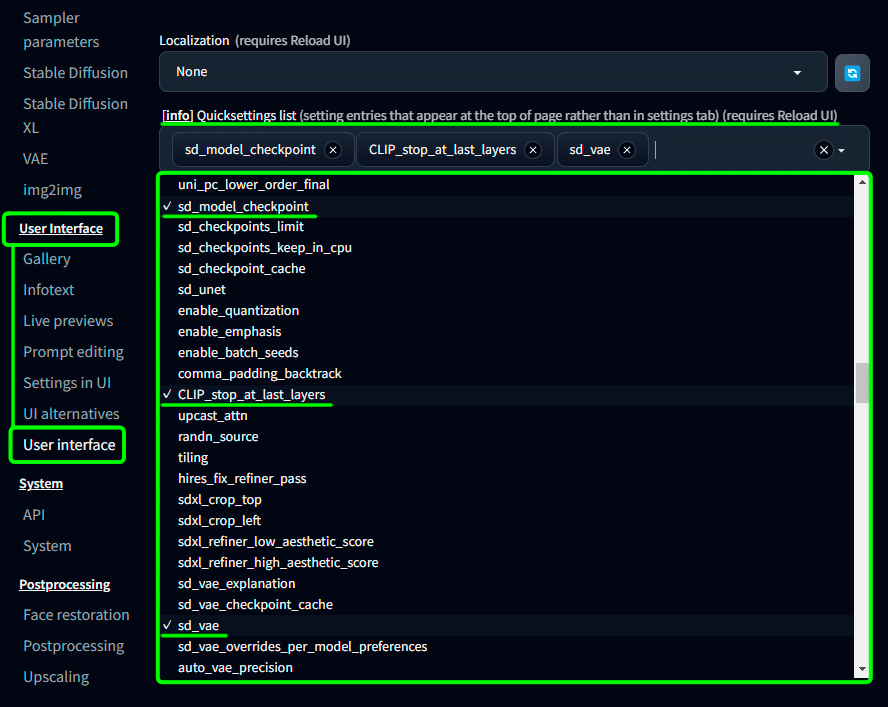
User Interface の User Interface の
[info] Quicksettings list のプルダウンから
・sd_model_checkpoint
・CLIP_stop_at_last_layers
・SD VAE
を追加する。
こうすると、メイン画面の上部に設定項目が追加されています。
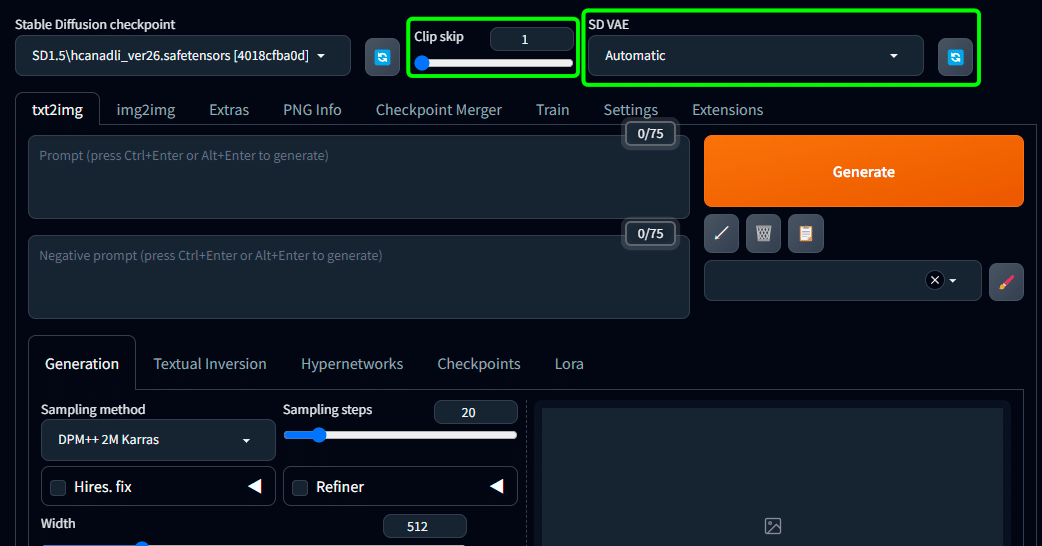
イラスト界隈だとClip skipは 2 というのが多いですが、私は結構頻繁に変えて遊んでいます。
数字が大きいほど変化が大きく、promptの命令から逸脱した画像ができたりします。
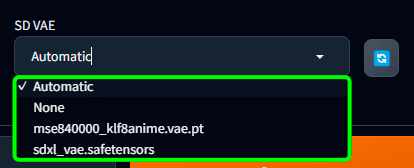
プルダウンで Automatic や None という設定もあります。
基本は Automatic で大丈夫だと思います。
実は、SDXL と以前までの SD1.5モデル などですと、追加学習モデルやVAEで同じものを使えなかったりします。
なので、モデルごとにどのVAEを使ってほしいか、個別に設定する方法もいここで書いておきます。
画像生成する画面のタブから、Checkpoints を選択して 導入しているモデルのサムネイルを表示させてください。
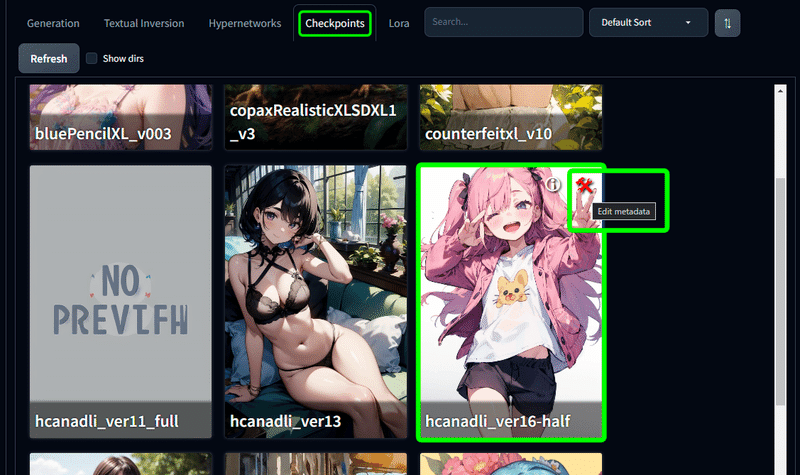
サムネイルの右上にある、工具アイコンをクリックすることで、メタデータを編集する機能が使えます。
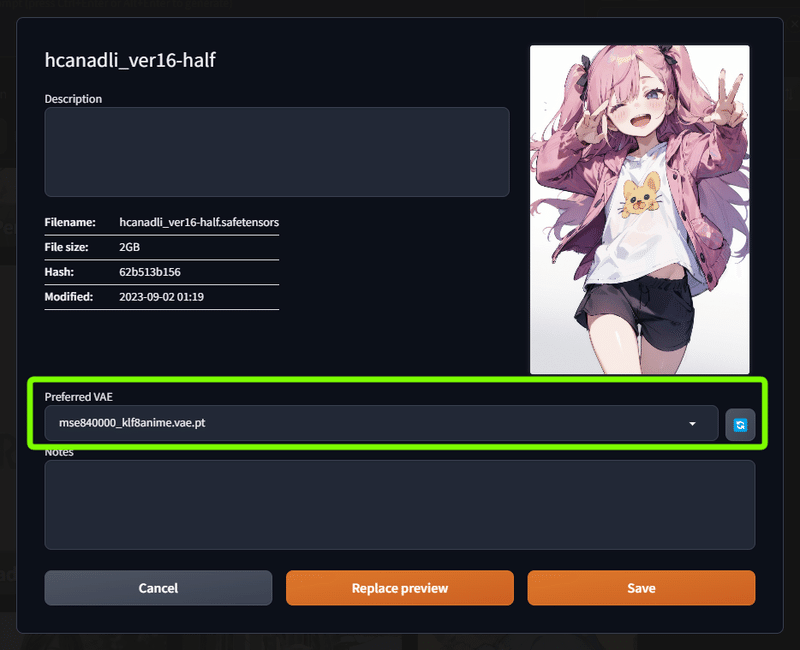
ここで優先されるVAEを個別に設定しておくことができます。
ここでは自作の1.5モデルですので、今まで使っていた1.5モデル用のVAEを設定しました。
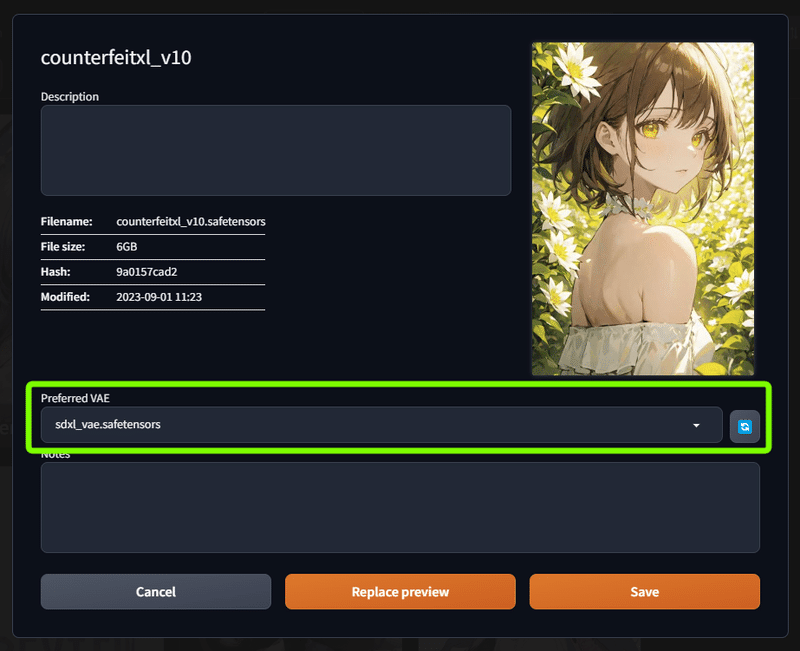
こちらは多くの方がお世話になっているアニメ系モデルのcounterfeitシリーズのSDXL版です。
なので、現状で持っている SDXL用の sdxl_vae.safetensors を設定しておきました。
・img2img の際に使う Upscaler を指定しておく
Postprocessing 内の Upscaling の
Upscaler for img2img で 好みのアップスケーラーを選択しておく。
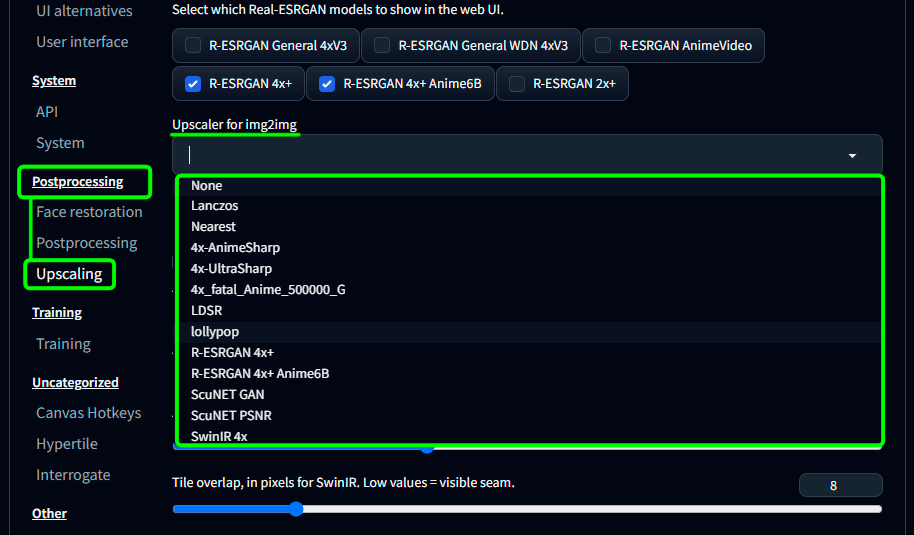
フォルダ構成に関しての説明のあたりでアップスケーラーを追加していた場合の設定です。
img2imgで拡大する際、毎回ここで設定したアップスケーラーを使ってくれるようになります。
アップスケーラーに関しての記事はこちらになっています。
最近は他にも増えてそうですが、初期の定番のものはご紹介しているつもりです。
良いアップスケーラーがありましたら、教えて頂けると嬉しいです。
・変更したセッティングを保存&適用する
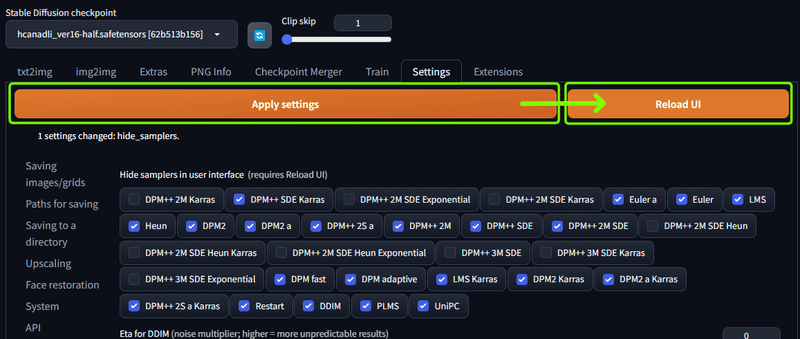
以降、設定が反映されるようになります。
また、これまでの設定の途中段階でも内容を反映したい場合は、その都度やっておいて問題ありません。
個人的に使っている拡張機能
・easy-prompt-selector&wildcards
Extensions の Install from URL で
https://github.com/blue-pen5805/sdweb-easy-prompt-selectorを入れてインストール。
Extensions の Install from URL で
https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards.gitを入れてインストール。
こちらで紹介している拡張機能2つをインストールしています。
詳しくはリンクページをご覧ください。
Tiled Diffusion & VAE
Extensions の Install from URL で
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.gitcopy
を入れてインストール
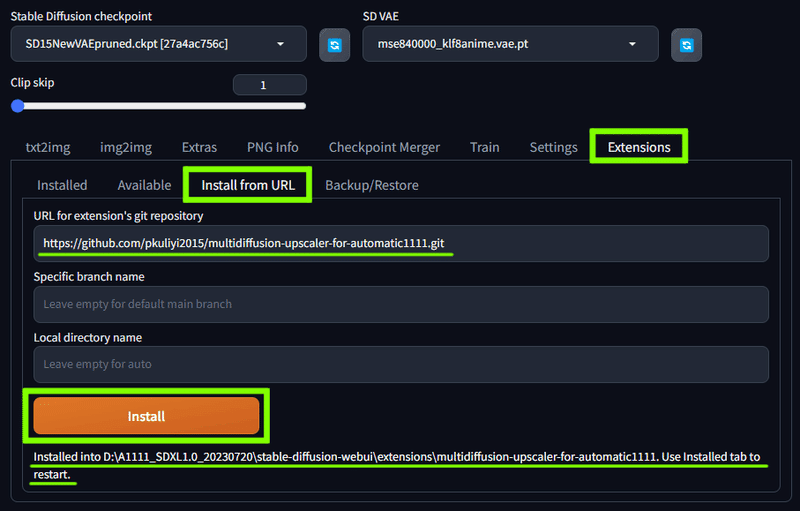
大きいサイズの画像に生成し直す際、画像をタイル状に区切って小さな画像を複数生成するという手順を使うことで、低スペックPCでも大きなサイズの画像を生成することができる拡張機能です。
https://note.com/hcanadli12345/n/n9a3fcbfa2c7e
詳しくはこちらの解説記事をご覧ください。
リッチなイラストに仕上げたい場合には是非使いたい拡張機能です。
ここからは Extensions の Available タブから Load from: を押して、リストの中から拡張機能をインストールしていきます。
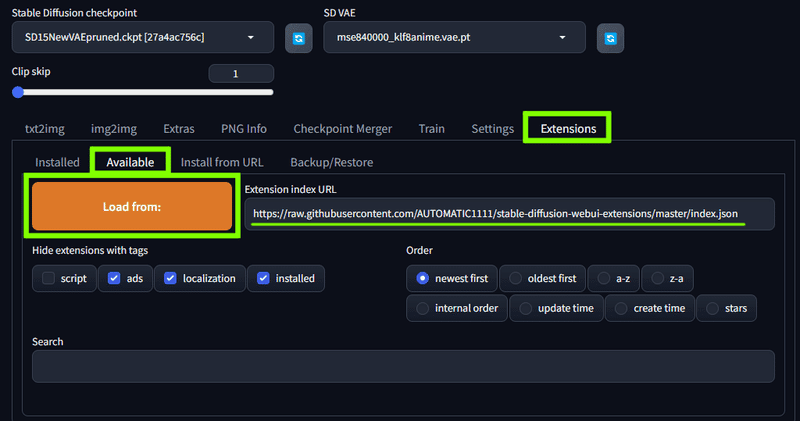
https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.jsoncopy
というURLがあらかじめ入っていると思うので、そのまま Load from: すれば画面下側にリストが読み込まれます。
ここからはサーチ機能を使って拡張機能を探していきます。
After Detailer
「After Detailer」 で検索して !After Detailer manipulations をインストール。
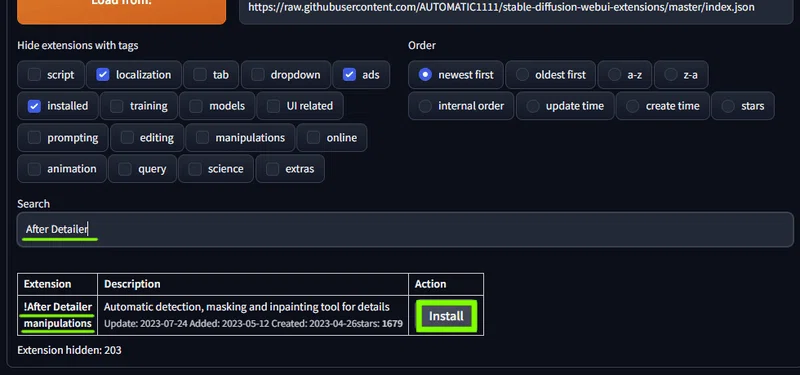
これは画像を生成したあと、自動で顔や手、身体といった特定の部分のみ、もう一度詳細に描き直して合成してくれる拡張機能です。
部分的に拡大した上で生成し、自動で合成してくれるため、その個所のディテールが上がります。
また、それぞれにプロンプト&ネガティブプロンプトも設定できるので、細かい表情や服の模様などは、こちらの欄で指定するなどの方法もとれます。
こちらも細かい説明などは別記事で今後書くことになると思いますので、お待ちいただければ幸いです。
ControlNet
「sd-webui-controlnet」 と検索して sd-webui-controlnet manipulations をインストール。
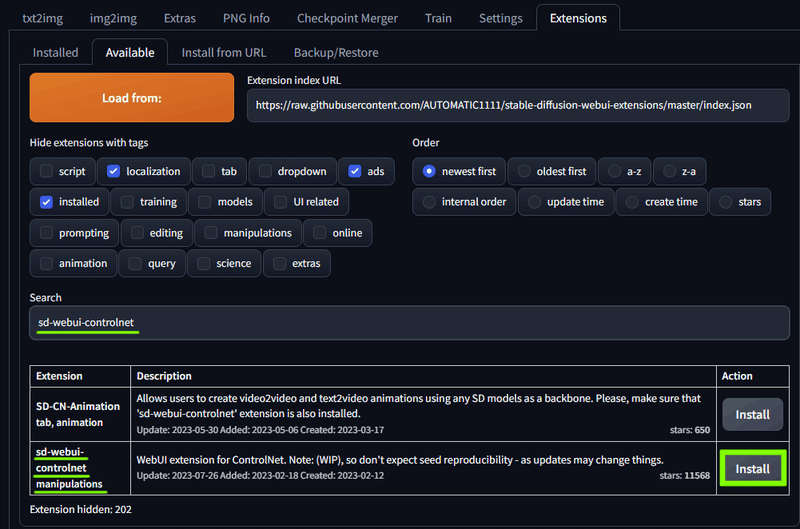
言わずと知れた ControlNet です。
詳しい記事はFANBOXの方でかなり細かく説明していたのですが、現在はあちらが使えなくなってしまったので記事の引っ越しを予定しています。
簡単に言ってしまえば、画像を生成する際にポーズや構図、表情や要素といったものを指定することができる拡張機能です。
ガチャ要素を減らして目的のイラストを作成したい際に大いに役立ちます。
https://note.com/hcanadli12345/n/nb2315a4cabd9
https://note.com/hcanadli12345/n/n1ab807153c7c
詳しくは、これらの記事をご確認ください。
3D Openpose Editor
「3D Openpose Editor」で検索して 3D Openpose Editor tab をインストール。
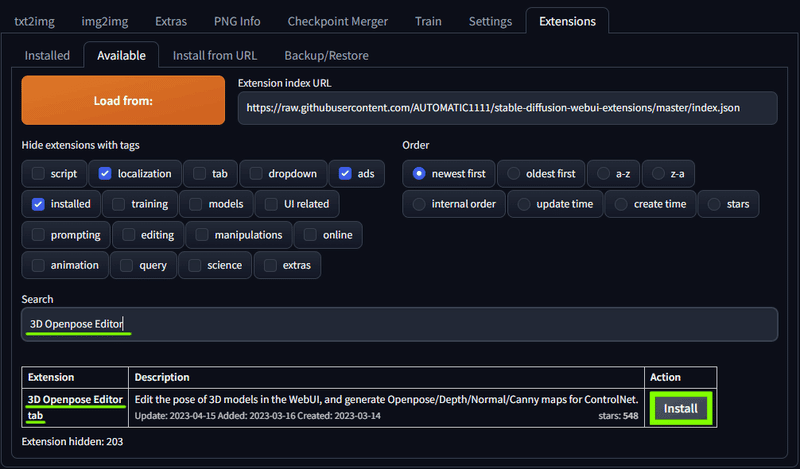
先程の ControlNet でポーズを指定する際に使う機能に Openpose というものがあるのですが、その下地になるポーズを3D人形を使って作成することができる拡張機能です。
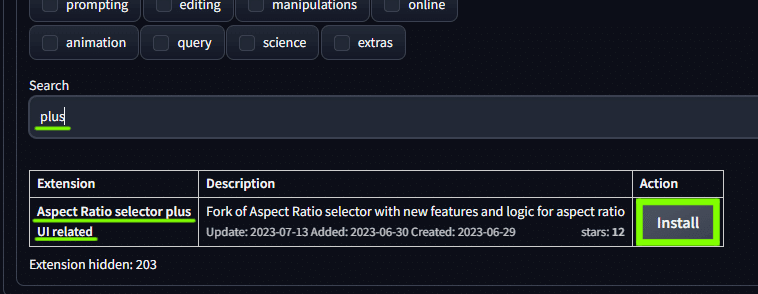
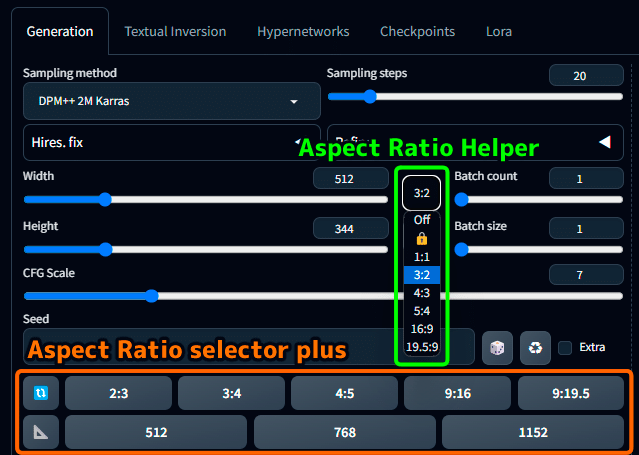
Aspect Ratio selector plus & Aspect Ratio Helper
「plus」 と検索して Aspect Ratio selector plus UI related をインストール。
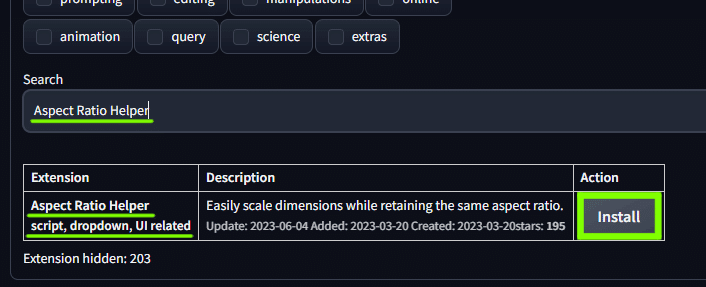
「Aspect Ratio Helper」 と検索して Aspect Ratio Helper script, dropdown, UI related をインストール。
sd-webui-supermerger
※現在、私の環境ではsupermergerを入れると、WebUI起動時に動作反応がしないという不具合に悩まされています。
更新ボタンを押すと解消されるのですが、毎回は結構面倒なんですよね。
使わない時は Extensions ➡ Installed から sd-webui-supermerger のチェックを外しておくと良いかもしれません。
「supermerger」 と検索して SuperMerger tab, models, installed をインストール。
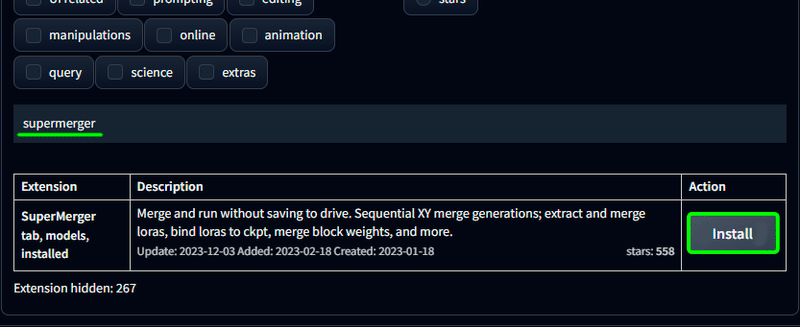
モデルのマージ、階層マージ、LoRAのマージなどが行える強力な拡張機能です。
自分なりの絵柄を追求したい人は是非。
この他にも、モデルデータのチェック・修正のできる stable-diffusion-webui-model-toolkit。
モデルの階層マージを行える sdweb-merge-block-weighted-gui なんかも使っています。
このあたりは解説記事を書いた際にでも改めてご紹介します。
すべての拡張機能のインストールが終わったら、Extentions の Installd から Apply and restart UI を押してインストールを確定させ、再起動させれば拡張機能が反映されるようになります。
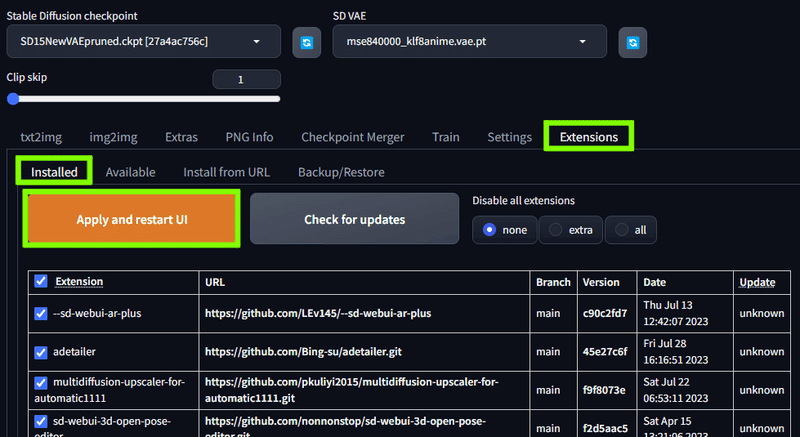
もしそれでも反映しなかった場合は、一度WebUIを終了し、もう一度起動しなおしてみてください。
Q&A:入れたはずのLoRAが消えてんだけど!?
初めてSDXL環境を入れた時にありがちな恐怖体験です。
単純に、現在メインに読み込んでいるモデルが2.0の場合、古い1.5用の追加学習モデルは使用できないため、見えなくなっています。
1.5モデルを読み直してから、LoRA選択ウィンドウの Refreshボタン を押せば再び見えるようになります。
たまに古い学習モデルなのに見える場合があるのですが、あれは使えるという事なのかしら??🤔
手短ですが、以上で今回の記事は終わります。
今後も 1.7.0 の間はこちらの記事で内容更新するつもりですので、たまに覗いて頂けると、なにか変わっているかもしれません。
それでは、また。
はかな鳥でした。
この記事が気に入ったらサポートをしてみませんか?