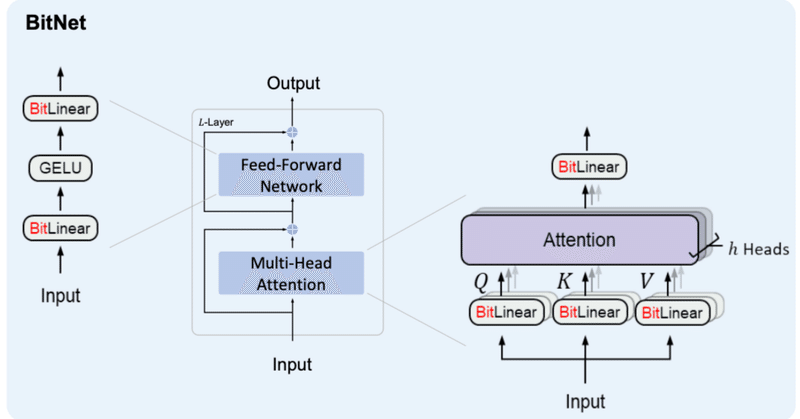
BitNet&BitNet b158の実装④

はじめに
前回、BitLinear b158の実装を行いました。前回までの内容は以下をご参照ください。
4. BitNet b158の検証
BitNetの検証と同様、
BitLlamaでBitLinear158bを利用できる様に修正
事前学習ができるか(Lossが下がるか)確認
を行います。
4-1. BitLlamaの修正
modeling_bit_llama.pyにおいて、BitLinearを使用している箇所をBitLinear158bに切り替えられる様にするだけなので変更は容易です。
① configの修正
まず、BitLlamaがBitLinearとBitLinear158bのどちらを使用するかConfigで指定できるようにbitnet_typeを追加します。
この時、["1.58b", "1b"]以外が入力されたらエラーを返す様にしておきます。
self.bitnet_type = bitnet_type
if self.bitnet_type not in ["1.58b", "1b"]:
raise ValueError("bitnet_type must be either '1.58b' or '1b'.")Config全体は以下の様になります。
class BitLlamaConfig(LlamaConfig):
model_type = "bit_llama"
def __init__(self, bitnet_type="1.58b", bits=8, **kwargs):
super().__init__(**kwargs)
self.bitnet_type = bitnet_type
if self.bitnet_type not in ["1.58b", "1b"]:
raise ValueError("bitnet_type must be either '1.58b' or '1b'.")
self.bits = bits② 各モジュールの修正
次にBitLinearを含むモジュール(BitLlamaMLP, BitLlamaAttention, BitLlamaFlashAttention2, BitLlamaSdpaAttention)にて、上で追加したconfig.bitnet_typeを確認してBitLinear / BitLinear158bのどちらを使うかの分岐を追加します。
例えば、BitLlamaMLPは以下の様になります。
class BitLlamaMLP(LlamaMLP):
def __init__(self, config):
super().__init__(config)
if config.bitnet_type=="1b":
self.gate_proj = BitLinear(self.hidden_size, self.intermediate_size, bias=False, rms_norm_eps=config.rms_norm_eps, bits=config.bits, flg_before_linear=False)
self.up_proj = BitLinear(self.hidden_size, self.intermediate_size, bias=False, rms_norm_eps=config.rms_norm_eps, bits=config.bits, flg_before_linear=True)
self.down_proj = BitLinear(self.intermediate_size, self.hidden_size, bias=False, rms_norm_eps=config.rms_norm_eps, bits=config.bits, flg_before_linear=True)
elif config.bitnet_type=="1.58b":
self.gate_proj = BitLinear158b(self.hidden_size, self.intermediate_size, bias=False, rms_norm_eps=config.rms_norm_eps, bits=config.bits)
self.up_proj = BitLinear158b(self.hidden_size, self.intermediate_size, bias=False, rms_norm_eps=config.rms_norm_eps, bits=config.bits)
self.down_proj = BitLinear158b(self.intermediate_size, self.hidden_size, bias=False, rms_norm_eps=config.rms_norm_eps, bits=config.bits)
else:
raise ValueError("bitnet_type must be either '1.58b' or '1b'.")これでBitLlamaの修正は完了です。全量は以下をご確認ください。
4-2. 事前学習(Lossの確認)
① 学習条件
2章同様、学習は"range3/wiki40b-ja"を1epochのみ実行しある程度Lossが下がっていきそうなことを確認するに止めました。
モデルサイズは127Mほどです。
公式からの追加FAQのTable1, 2を参照し、学習時の設定は以下のようにしました。learning_rateのみ、BitLlamaの時のもの(2章参照)を踏襲しています。
lr_scheduler_type="linear",
learning_rate=2.4e-3,
adam_beta1=0.9, # 追加FAQより
adam_beta2=0.95, # 追加FAQより
weight_decay=0.1, # 追加FAQより

論文の設定では、LearningRateのピークとWeight Decayを途中で変更していますが、ここでは一旦変えずに実行しています。
② Lossの確認
Trainの実行結果は以下の様になりました。

| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 4.7094 | 0.05 | 2000 | 3.7099 |
| 3.5644 | 0.1 | 4000 | 3.4754 |
| 3.4187 | 0.15 | 6000 | 3.3482 |
| 3.3026 | 0.2 | 8000 | 3.2653 |
| 3.2405 | 0.25 | 10000 | 3.2143 |
| 3.1966 | 0.29 | 12000 | 3.1806 |
| 3.1666 | 0.34 | 14000 | 3.1533 |
| 3.1408 | 0.39 | 16000 | 3.1344 |
| 3.12 | 0.44 | 18000 | 3.1123 |
| 3.1005 | 0.49 | 20000 | 3.0934 |
| 3.0802 | 0.54 | 22000 | 3.0769 |
| 3.0629 | 0.59 | 24000 | 3.0545 |
| 3.0427 | 0.64 | 26000 | 3.0319 |
| 3.0206 | 0.69 | 28000 | 3.0111 |
| 3.0008 | 0.74 | 30000 | 2.9897 |
| 2.9735 | 0.79 | 32000 | 2.9632 |
| 2.9466 | 0.83 | 34000 | 2.9335 |
| 2.9165 | 0.88 | 36000 | 2.9039 |
| 2.8816 | 0.93 | 38000 | 2.8623 |
| 2.8345 | 0.98 | 40000 | 2.8102 |無事に事前学習ができていると言ってよさそうです。
またBitLlamaの時と同様、The S-shape Loss Curveが確認できました。学習後半、learning rateが下がってきたタイミングでLossの下がり方が大きくなっています。
2章のBitNetと先ほどのBitNet b158のLossを比較すると以下の通りです。lr_scheduler_typeが異なりますが、どちらもlearning rateは2.4e-3です。BitNet b158の方がLossの下がり方が大きく、学習が早いと言えそうです。

③ モデルの動き確認
モデルは以下に配置しています。
学習したモデルの動きを見てみます。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "HachiML/myBit-Llama2-jp-127M-8"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)prompt = "昔々あるところに、"
input_ids = tokenizer.encode(
prompt,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)昔々あるところに、この地には、かつての王の宮殿があった。_NEWLINE_王の宮殿は、王の宮殿の周りに建てられた。王の宮殿は、王の宮殿の周りに建てられた。王の宮殿は、王の宮殿の周りに建てられた。王の宮殿は、王の宮殿の周りに建てられた。王の宮殿は、王の宮殿の周りに建てられた。王の宮殿は、王の宮殿の周りに建てられた。王の宮殿は、王
BitNetの時と同様、学習が足りない感じではあるものの序盤はなんとなく頑張って返そうとしてくれている感じはします。
学習に使ったコードの全体は以下に配置してあります。ご参照ください。
最新のtransformersでは、customモデルの取得にバグがあるみたいで上手く行えないので、しばらくはtransformers==4.38.2として使用するのが良いと思います。
おわりに
これでBitNetの実装からBitNet b158の実装まで完了しました。思ったよりも長くなってしまいましたが、これで一旦やりたかったことは完了としたいと思います。
今後は、
同サイズのLlama(BitLlamaではなく)のLoss curveとの比較
処理速度、メモリの観点でのコードの最適化
weightの2,3値化とactivationの量子化を活かした行列積の実装
など空いた時間にできればと思っています。
多くの人は感じている通り、現状では実用的とは言えない状況です。実用化には特に3点目の実現が必要となります。現行のPytorchではtorch.matmulが勝手にfloat32の精度で計算してしまうみたいです。
長くなりましたがここまで目を通していただきありがとうございます。
これまでのコードはGithub上に公開していますのでよければ触ってみてあげてください。
参照
この記事が気に入ったらサポートをしてみませんか?