【Python】画像認識で建物の種類を識別する

はじめに
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
インフラの点検を主な職業としています。
将来的に点検で得られた損傷の画像をAIで判別して分類できるようになれば楽だなあと考え、その前段階として建物の種類を分類するアプリを作成することにしました。
実際の作業データ
実際に作成したAI学習成果を公開します。
学習済みモデル(h5ファイル)
https://drive.google.com/file/d/17KR2a040tL2mhwEGzq9dosdFBERiM-jQ/view?usp=drive_link
目次
1.実行環境
2.画像収集
3.画像の確認
4.コードの実行
5.HTMLの作成
6.試行錯誤
7.結果と考察
8.まとめ
1.実行環境
・Visual Studio Code
・Google Colaboratory
2.画像収集
将来の運用を見越して、「橋」・「ビル」・「タワー」の3種類の画像を収集することにしました。
必要な画像を用意して収集した画像をGoogleDrive上に保管しなくてはなりません。
以下のコードを実行することで、マウントできます。
#Googledrive内にフォルダを作る許可を与える
from google.colab import drived
rive.mount('/content/drive') 許可を与えたらコードを用いて画像の収集、スクレイピングを行います。
今回はスクレイピングする対象をBingとします。
以下のコードを実行することで、スクレイピングできます。
まずは画像を収集する枚数を「100」として実行しました。
#必要な機能のインストール
!pip install icrawler #pythonライブラリの 「icrawler」でBing用モジュールをインポート
from icrawler.builtin import BingImageCrawler #GoogleColab内に保存フォルダを作る
crawler = BingImageCrawler(storage = {'root_dir' : './image'}) #ダウンロードするキーワード ”ビル”と取得する最大枚数を100枚として設定
crawler.crawl(keyword = 'ビル', max_num = 100)参考)【Python】icrawlerを使って画像データを簡単に収集する
https://zenn.dev/robes/articles/fb617fc0144e80
実行すると以下のように画像を収集することができました。
以上のコードをビル以外にも橋とタワーでそれぞれ実行します。
収集した画像はPCの作業フォルダに一度ダウンロードしておきます。
3.画像の確認
収集した画像を確認して不要な画像がないかどうかを確認します。
画像を収集すると不要な画像が必ず入ります。
私は以下の点を確認して画像の要不要を決めました。
1.画像の拡張子がjpgである
2.学習対象に使用できない、もしくは使用しづらい

例に示されるような画像を除外した上で、以降の作業を続けました。
この時点ではそれぞれ40~50枚程度の画像でした。
4.コードの作成
一番最初に実行したコードです。
import os #osモジュール (os機能がpythonで扱えるようにする)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
#GoogleDriveの参考
from google.colab import drive
drive.mount('/content/drive/')
#建物の画像の格納
drive_tower = "/content/drive/MyDrive/Aidemy/tower/"
drive_building = "/content/drive/MyDrive/Aidemy/building/"
drive_bridge = "/content/drive/MyDrive/Aidemy/bridge/"
image_size = 150 # 幅150のサイズに指定
#os .listdir() で指定したファイルを取得
path_tower = [filename for filename in os.listdir(drive_tower) if not filename.startswith('.')]
path_building = [filename for filename in os.listdir(drive_building) if not filename.startswith('.')]
path_bridge = [filename for filename in os.listdir(drive_bridge) if not filename.startswith('.')]
#各種建物の画像を格納するリスト作成
img_tower = []
img_building = []
img_bridge = []
for i in range(len(path_tower)):
img = cv2.imread(drive_tower+ path_tower[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_tower.append(img) #画像配列に画像を加える
for i in range(len(path_building)):
img = cv2.imread(drive_building+ path_building[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_building.append(img)
for i in range(len(path_bridge)):
img = cv2.imread(drive_bridge+ path_bridge[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_bridge.append(img)
X = np.array(img_tower + img_building + img_bridge)
y = np.array([0]*len(img_tower) + [1]*len(img_building) + [2]*len(img_bridge) )
label_num = list(set(y))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone -hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(image_size,image_size, 3))
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの定義 ~活性化関数シグモイド #転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid')) #top_model .add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax'))
#モデルの定義 ~活性化関数ReLU #転移学習の自作モデルとして下記のコードを作成 #top_model = Sequential() #top_model .add(Flatten(input_shape=vgg16.output_shape[1:])) #top_model .add(Dense(256, activation='relu')) #top_model .add(Dropout(0.5)) #top_model .add(Dense(3, activation='softmax'))
#vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを15層までに固定 (以降に新しい層(top_model)が追加)
for layer in model.layers[:15]:
layer.trainable = False
#訓令課程の設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
学習の実行
#グラフの可視化
history = model.fit(X_train, y_train, batch_size=32, epochs=50, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #acc , val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show() #モデルを保存
model.save("my_model.h5")以上のコードの中で実行するにあたって、以降に解説を行います。
参考文献:
>>numpy.random.permutation – 配列の要素をランダムに並べ替えた新しい配列を生成
https://www.headboost.jp/numpy-random-permutation/
コード解説
image_size = 150 #150 ×150のサイズに指定 学習時の画像サイズを決定するコードです。
この場合は1辺150に固定するように指示しています。
#学習データと検証データを用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):] 学習時と検証時のデータの割合を決めます。
最初は学習割合を一般的な0.8にして実行しました。
#モデルの定義 ~活性化関数シグモイド #転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax')) 学習モデルのニューロン数を定義します。
初回は枝数を256、ドロップアウト0.5で行いました。
やっていて意外と難題になってしまい、とにかく正確性に困らされました。
5.HTMLの作成
アプリを実行するためのhtmlを作成します。
内容は以下の通りです。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Buildings Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<!-- <img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy"> -->
<a class="header-logo" href="#">Building Classifier</a>
</header>
<div class="main">
<h2> AIが送信された画像が橋、神社、ビルのどれであるかを識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2024 Takahashi, inc.</small>
</footer>
</body>
</html> AidemyのFlask入門の中にあるコードを参考に作成しました。
この状態で進めていきます
6.問題と改良
モデルの定義の選定と問題点1
モデルの定義にはシグモイドとReluの2種類があります。
2種類の定義でどのように異なるかををまず検証しました。
#モデルの定義 ~活性化関数シグモイド #転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax')) #モデルの定義 ~活性化関数ReLU #転移学習の自作モデルとして下記のコードを作成 #top_model = Sequential() #top_model .add(Flatten(input_shape=vgg16.output_shape[1:])) #top_model .add(Dense(256, activation='relu')) #top_model .add(Dropout(0.5)) #top_model .add(Dense(3, activation='softmax')) 以上を用いて作成したコードを実行しました。
以下がその成果です。
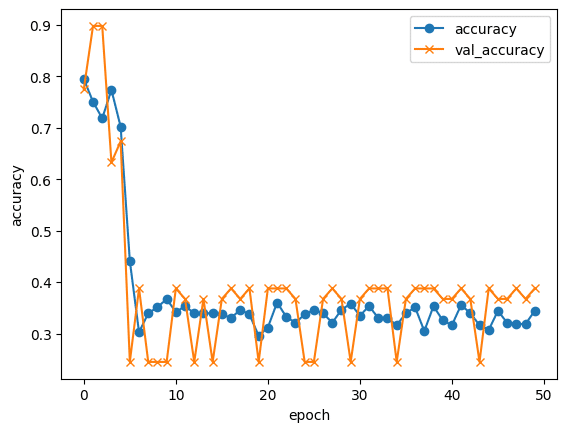

シグモイドもReluもどちらも低調です。
ですが、多少の有意を見いだせたのでシグモイドを利用します。
このあと進捗の確認として一度チューターに確認すると正確性が低すぎる点を指摘されました。
正確性向上のために以下を試すよう指摘されました。
・画像の枚数を増やす
・反転画像を用いるようにして画像を水増ししてみる。
学習対応の変更と問題点2
指摘に伴い反転画像を増やすコマンドを追加しました。
また、この時点でできた学習成果を用いて判定を行ったところ、橋の画像としてつり橋を多く利用しており、吊り橋の塔の部分をタワーとみなしてしまう場合がありました。
そのため学習が困難になる可能性を考慮して、識別対象を「橋」・「ビル」・「タワー」から「神社」・「ビル」・「タワー」の建物3種類に変更することにしました。htmlも含めてこの時点で更新しました。

この時点でのコードに変更・追加した部分は以下の通りです。
#建物の画像の格納
drive_shrine = "/content/drive/MyDrive/Aidemy/shrine/"
drive_building = "/content/drive/MyDrive/Aidemy/building/"
drive_bridge = "/content/drive/MyDrive/Aidemy/bridge/"
image_size = 128 # 幅256のサイズに指定
#os .listdir() で指定したファイルを取得
path_shrine = [filename for filename in os.listdir(drive_shrine) if not filename.startswith('.')]
path_building = [filename for filename in os.listdir(drive_building) if not filename.startswith('.')]
path_bridge = [filename for filename in os.listdir(drive_bridge) if not filename.startswith('.')]
#各種建物の画像を格納するリスト作成
img_shrine = []
img_building = []
img_bridge = []
for i in range(len(path_shrine)):
img = cv2.imread(drive_shrine+ path_shrine[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_shrine.append(img) #画像配列に画像を加える
my_img = cv2.flip(img, -1)
img_shrine.append(my_img) #画像配列に反転した画像を加える
for i in range(len(path_building)):
img = cv2.imread(drive_building+ path_building[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_building.append(img)
my_img = cv2.flip(img, -1)
img_building.append(my_img) #画像配列に反転した画像を加える
for i in range(len(path_bridge)):
img = cv2.imread(drive_bridge+ path_bridge[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_bridge.append(img)
my_img = cv2.flip(img, -1)
img_bridge.append(my_img) #画像配列に反転した画像を加える
X = np.array(img_shrine + img_building + img_bridge)
y = np.array([0]*len(img_shrine) + [1]*len(img_building) + [2]*len(img_bridge) )
label_num = list(set(y))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.9)]
y_train = y[:int(len(y)*0.9)]
X_test = X[int(len(X)*0.9):]
y_test = y[int(len(y)*0.9):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone -hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(image_size,image_size, 3))
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの定義 ~活性化関数シグモイド #転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid')) #top_model .add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax')) また指摘があった通り、使用している画像は100枚を収集した中から使えそうなものを選別しているため、この時点で50枚程度です。
そのため、画像収集する枚数を「500」にして収集しなおしました。
その結果、250枚前後の画像が収集でき、不適当なものや画像の重複を確認して選別した結果、100枚前後になりました。
新たに作業した結果が以下の通りです。
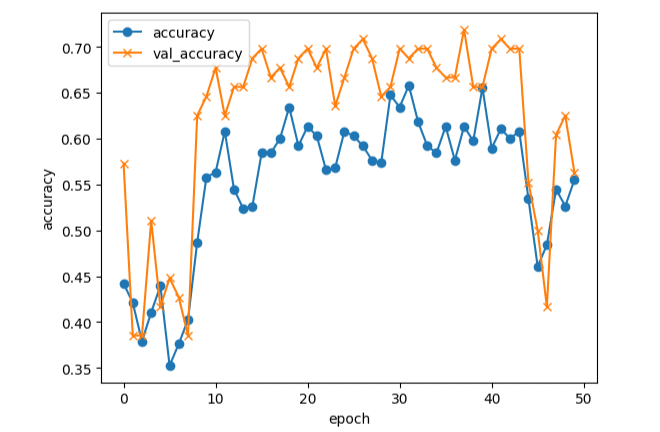
これでもまだ40~70%程度までしか正確性が確保できていません。
一度行き詰りました。
画像の加工
あらためてチューターに相談したところ、以下の点に問題がありそうだと指摘されました。
・画像に余計な情報が含まれていないか、画像についてはある程度加工してよいので切り出してみてはどうか
・加工と合わせて自動学習に用いる画像は正方形が望ましいため、画像サイズを変更してはどうか
・正確性のグラフがあまりにも凸凹している。dropoutが悪さをしている可能性が高いので、はずしてみてはどうか
・枚数も100枚程度なので、学習割合を0.9にしてみてはどうか
この4点のうち、最も重要な指摘は前半の二つです。
特に、画像を加工してもよいというのが盲点でした。
ここから手持ちの画像ソフトを使用して画像サイズを変更しました。
下に示す通り、画像内の緑や背景の建物などの不要な部分を削除します。

また収集した画像は横長でかつサイズは一定ではないので、すべての画像で1080×1080になるようにしました。足りない部分は余白を設けることで対応します。
学習においては正確性を確保するためとチューターのアドバイスで2の倍数のほうが良いのではないかと言われたので、コードでは少し大きめの256にしました。
以上の作業を踏まえて、最終的なコードを以下に示します。
import os #osモジュール (os機能がpythonで扱えるようにする)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
#GoogleDriveの参考
from google.colab import drive
drive.mount('/content/drive/')
#建物の画像の格納
drive_shrine = "/content/drive/MyDrive/Aidemy/shrine/"
drive_building = "/content/drive/MyDrive/Aidemy/building/"
drive_bridge = "/content/drive/MyDrive/Aidemy/bridge/"
image_size = 256 # 幅256のサイズに指定
#os .listdir() で指定したファイルを取得
path_shrine = [filename for filename in os.listdir(drive_shrine) if not filename.startswith('.')]
path_building = [filename for filename in os.listdir(drive_building) if not filename.startswith('.')]
path_bridge = [filename for filename in os.listdir(drive_bridge) if not filename.startswith('.')]
#各種建物の画像を格納するリスト作成
img_shrine = []
img_building = []
img_bridge = []
for i in range(len(path_shrine)):
img = cv2.imread(drive_shrine+ path_shrine[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_shrine.append(img) #画像配列に画像を加える
for i in range(len(path_building)):
img = cv2.imread(drive_building+ path_building[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_building.append(img)
for i in range(len(path_bridge)):
img = cv2.imread(drive_bridge+ path_bridge[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size))
img_bridge.append(img)
X = np.array(img_shrine + img_building + img_bridge)
y = np.array([0]*len(img_shrine) + [1]*len(img_building) + [2]*len(img_bridge) )
label_num = list(set(y))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.9)]
y_train = y[:int(len(y)*0.9)]
X_test = X[int(len(X)*0.9):]
y_test = y[int(len(y)*0.9):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone -hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(image_size,image_size, 3))
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの定義 ~活性化関数シグモイド #転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid')) #top_model .add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax'))
#モデルの定義 ~活性化関数ReLU #転移学習の自作モデルとして下記のコードを作成 #top_model = Sequential() #top_model .add(Flatten(input_shape=vgg16.output_shape[1:])) #top_model .add(Dense(256, activation='relu')) #top_model .add(Dropout(0.5)) #top_model .add(Dense(3, activation='softmax'))
#vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを15層までに固定 (以降に新しい層(top_model)が追加)
for layer in model.layers[:15]:
layer.trainable = False
#訓令課程の設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習の実行 #グラフの可視化
history = model.fit(X_train, y_train, batch_size=32, epochs=50, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #acc , val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show() #モデルを保存
model.save("my_model.h5")このコードを用いて得られた成果が以下の通りです。

この成果とVisual Studio Codeでの作業結果をチューターに確認していただいた結果、成果として十分であると評価をいただいたので、これを最終成果としました。

Flask上での公開を目指したのですが、これについてはFlask上で公開できる容量のサイズ(100MB)をオーバーしてしまったので、その点だけ残念です。
7.結果と考察
建物3種類の分類を実行した結果、作業者が最も重要であると判断したのは以下の点です。
・画像サイズは正方形になるように調整すること
・学習対象の画像は何を学習させたいかを作業者が判断して加工すること
・画像の内容が似通ってしまった場合は対象を変更するか、画像の調整で学習点を明確に差異を付けること
かなり正確性の向上については悩んだのですが、これらを踏まえれば学習の正確性を確保できると思います。
8.まとめ
AIアプリ開発講座をしました。
まったく勉強したことのないプログラム言語の学習から始まり、ディープラーニングやAIの体系的な知識を得ることができ、基本的なモデルの構築について把握することができたので、非常にいい勉強になりました。
特にチューターの方々の指導がなければ、Pythonの考え方、コードの問題点の解決方法、Flaskの環境構築など個人では理解できないこと多数です。
この場を借りて厚く御礼申し上げます。
この記事が気に入ったらサポートをしてみませんか?