
ココナラから副業案件を自動通知してくれるpythonスクレイピングコードを作った。その1(全3回)

プログラミングを覚えてさて副業だ!と意気込む諸兄がまずぶち当たる壁は、副業サイトの多さではなかろうか!?そもそもこのご時世、副業サイトが多い多い。
とは言え、いわゆる定番なクラウドソーシングのサイトは決まっている。
今回はその中でも、とっつきやすい副業サイト、ココナラ(coconara)から、一発でプログラミング案件をスクレイピングするpythonコードを作ってみた!
このコードで出来ること
・副業サイトから狙った仕事をスクレイピング出来る
・自動でラインに通知してくれる
・自動通知でプログラミングを習慣化出来る
対象としている人
・プログラミングで何が出来るか知りたい人
・プログラミングの基礎トレのその後を探している人
必要なアイテム
ココナラをスクレイピングするのに必要なアイテムはこちら。
python
Beautiful Soup (ライブラリ)
selenium(ライブラリ)
その他もろもろのライブラリ
この記事を見てくれている時点で、最低限のプログラミン知識も経験もあると思うので、pythonの環境設定などについてはガッツリ省きます。
因みに私はMacもWinも使ってて、両方とも同じコードで動いてるよ。
因みに、まだそこまでじゃないんだ。オラに力を与えてくれ!という若武者には下記のサイトをおすすめします。
私がプログラミンを出来るようになった恩人のような方で、説明が非常に分かりやすく、私の中では「ご飯を育てたピッコロさん」みたいな人です。(ドラ○ンボールの話をすると若い世代に激しく忌避されると聞いてビビっているので、これ以上はやめておきます)
良いプログラミングサイトは沢山ありますが、生徒の目線まで降りてきて、相手が何が分からないか先回りして説明してくれる能力が、はやたす先生はずば抜けてると思います。
因みに余談ですが、このテクニックを利用するとモテるんじゃないかと思います。
さあ!冒険に出かけよう!
必要なアイテムも揃っていよいよ出発です。
心の準備はいいかな?
と!その前に、スクレイピングでは注意することがある。
もう知ってるかもだけど一応確認しよう。
スクレイピングは用法用量を守って正しくお使いください
私はスクレイピングする前に必ず以下の点を必ず確認しています。
・robots.txtで対象のページがDisallowに該当しないか?
・利用規約でスクレイピングを禁止していないか?
・禁止されていなくても、相手のサーバーに負荷をなるべくかけないようにsleepを忘れない
今スクレイピングを禁止していないサイトだとしても、相手方に迷惑がかかれば後々禁止になるかもしれません。なので上記3点を必ず私は守るようにしています。
とりあえずざっと完成品を見てみよう!順番に上から一つずつ見て行けばきっと理解できると思います。
#ココナラのサイトから募集中の仕事を毎日送ってきてくれるプログラミング
#ライブラリのインポート
import requests
import os
# import sys
from time import process_time_ns, sleep, time
import requests
from selenium import webdriver
# import os
from glob import glob
from time import sleep
from bs4 import BeautifulSoup
import pandas as pd
import time
import schedule
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# def job(event, context):
def job():
options = webdriver.ChromeOptions()
options.add_argument('--incognito')
options.add_argument('--headless')
#Chromeの場所を指定 Chrome104Betaで起動させるための設定
# options.binary_location = '/Applications/Google Chrome Beta.app/Contents/MacOS/Google Chrome Beta'
# driver = webdriver.Chrome(
# # executable_path='/Users/tomoyoshionuki/Desktop/lesson/tools/chromedriver', #105のDriverに変更済み
# executable_path='C:/Users/Administrator/Desktop/fromADev/tools/chromedriver', # win server用のpath
# options=options)
driver = webdriver.Chrome(ChromeDriverManager().install(), chrome_options=options) #自動でdriverをインストールして動かす。
driver.implicitly_wait(10)
max_page = 1
for n in range(max_page):
driver_url = f'https://coconala.com/requests/categories/230?recruiting=true&categoryId=230&page={n}'
driver.get(driver_url)
print(driver_url)
sleep(2)
html = driver.page_source
d_list = [] #ここにd_listを置かないとデータが蓄積されない。19段に置くと常に更新されて、csvに一つのデータしか入らない。
soup = BeautifulSoup(html, 'lxml')
# print(soup)
indi_tags = soup.select('div.c-searchItem') #各詳細ページの項目タグになる。
# print(indi_tags)
for i, ind in enumerate (indi_tags):
# areas = ind.select_one('h3.job-lst-main-ttl-txt').text
titles = ind.select_one('div.c-itemInfo_title > a').text
urls = ind.select_one('div.c-itemInfo_title > a').get('href')
# # dataes = ind.select_one('div.c-itemTileLine_remainingDate').text
list1 = ['\n' + titles.strip() + '\n' + urls] # ここで '\n' + を入れないとURLがURLとして認識されない
# list1 = list(filter(None,list1))
# # url = ind.select_one('div.c-searchPage_itemList')
# print(areas)
print(titles)
print(urls)
# # print(dataes)
# # u3_tags = soup.select('div.c-itemInfo_title > a').get('href')
# # u3_tags = soup.select_one('div.c-itemInfo_title > href').text
# # print(len(indi_tags))
# # print(u3_tags)
# # u3_tags = soup.select_one('span.d-requestPrice_emphasis').text
# # u4_tags = soup.select_one('div.c-contentHeader > nav > ul > li:nth-of-type(4) > a ').text
sleep(3)
d_list.append({
'Title': titles,
'URL': urls
})
print('='*30, i, '='*30 )
print(d_list[-1])
# df = pd.DataFrame(d_list)
# df.to_csv('townwork_yakin.csv', index=None, encoding='utf-8-sig')
def main():
line_notify(list1)
def line_notify(message):
line_notify_token = 'Bjifgdaoadhogayuoahgpiud121bhoubh' #ここでの初期値は'()'となっていたが、()にトークンを入れるとエラーになる。なので外した。
line_notify_api = 'https://notify-api.line.me/api/notify'
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
# # 実行プログラム本体
if __name__ == "__main__":
main()
driver.quit()
if __name__ == "__main__":
job()
# schedule.every().day.at("09:30").do(job)
# schedule.every().day.at("21:00").do(job)
# while True:
# schedule.run_pending()
# time.sleep(1) #完成した。この上記までのコードで定期実行は可能
関数(def)使ったりなんかコードも長くて難しそう。
てか
なんかゴチャゴチャしてね?
完成品の見て、こう思ったあなた!その通り。
でもね、このコード私が毎日使ってちゃんと動いているんです。
それにこれはあくまで完成版
今回のテーマはまず
「案件のタイトルとURLを取れるようにしよう!」
なので、下記のコードでタイトルとURLをスクレイピングしていこう。
(因みに余談だけど最終的にここで使う関数は簡単で、最後に囲むだけです。今はそんなに難しくはないんだな〜位の感覚で大丈夫です。)
#ココナラのサイトから募集中の仕事を毎日送ってきてくれるプログラミング
#ライブラリのインポート
import requests
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
options = webdriver.ChromeOptions()
options.add_argument('--incognito')
options.add_argument('--headless')
driver = webdriver.Chrome(ChromeDriverManager().install(), chrome_options=options) #自動でdriverをインストールして動かす。
driver.implicitly_wait(10)
max_page = 1
for n in range(max_page):
driver_url = f'https://coconala.com/requests/categories/230?recruiting=true&categoryId=230&page={n}'
driver.get(driver_url)
print(driver_url)
sleep(2)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
indi_tags = soup.select('div.c-searchItem') #各詳細ページの項目タグになる。
for i, ind in enumerate (indi_tags):
titles = ind.select_one('div.c-itemInfo_title > a').text
urls = ind.select_one('div.c-itemInfo_title > a').get('href')
print(titles)
print(urls)
sleep(3)だいぶスリムになった所でいよいよ始めていきましょう。
各種ライブラリーをインストール
#ライブラリのインポート
import requests
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options色々入ってますが、全部使いますのでpip install等で入れてあげて下さい。
seleniumでChromeからココナラにアクセス
options.add_argument('--incognito')Chromeをシークレットモードを開いています。
options.add_argument('--headless')そしてヘッドレスモードでブラウザを表示させずにコードを動かします。
これはスクレイピングの処理速度をアップさせる為だよ。
逆にブラウザの起動を確認したい場合などは、ヘッドレスモードをコメントアウトすると、ブラウザが動いている所を確認しながらコードをテスト出来るよ。
driver = webdriver.Chrome(ChromeDriverManager().install(), chrome_options=options) #自動でdriverをインストールして動かす。
# driver = webdriver.Chrome(
# executable_path='/Users/ttt/Desktop/lesson/tools/chromedriver', # mac用のpath
# executable_path='C:/Users/Administrator/Desktop/fromADev/tools/chromedriver', # windows用のpath
# options=options)はい!
ここちょっとポイントなんだけど、自動的に最新のwebdriverをダウンロードしてしてくれる便利なコードです。
何がそんなに便利なん?って思った人はコメントアウト(#から始まってるコードの事だよ)を見て欲しい。
実は自分でwebdriverのpath(ファイルの住所みたいな物を)を手動で設定することも出来るんだ。
でも私はオススメしない。なんで?って
Chromeのバージョンが上がると、プログラムが動かなくなるから。
多分初学者の内って、ちょっとしたことでコードが動かなくなるとパニックになると思うのね。エラー文章を見れば大抵解決するのだけど、パニック時にそんなもの冷静に見れないと思うんだ。しかも英語のエラーだし。
パニックも経験だし、慣れるとエラーが愛おしくなるんだけ、最初はつまずきは少ない方がいいと思うので、webdriverは自動でダウンロードしてくれる方が私はいいと思います。
(手動の方が動作は早いんだけどね)
driver.implicitly_wait(10)これも必須なんですが、ココナラがブラウザ上で開かれるまで待機してます。
driver_url = f'https://coconala.com/requests/categories/230?recruiting=true&categoryId=230&page={n}'いよいよここからスクレイピングに入っていくよ。
まずはココナラのURLから、自分に必要なページを取得していこう。
因みに、URL(https://coconala.com/requests/categories/230?recruiting=true&categoryId=230&page=1)にアクセスしてもらうと分かるのだけど、作業自動化・効率化というカテゴリに飛びます。
つまりスクレイピングの案件が表示されるんだ。
因みにココナラは59ページ(2022.12現在)まであります。
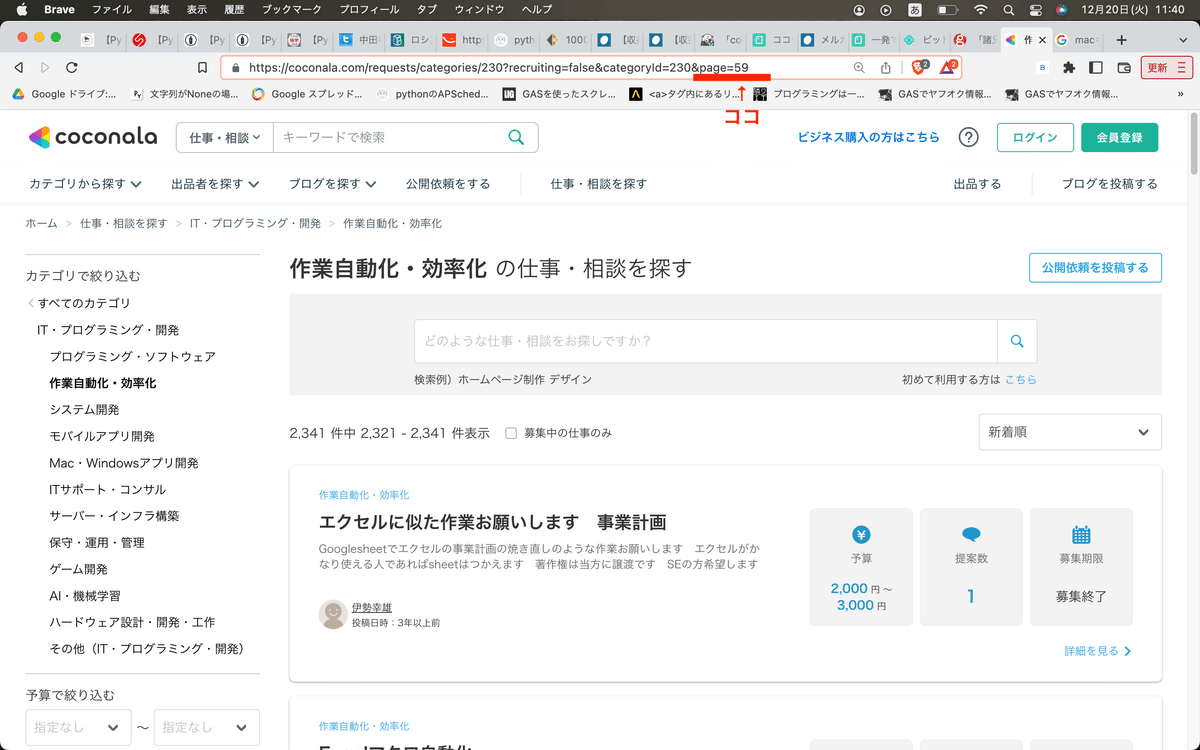
max_page = 1
for n in range(max_page):上記のmax_pageを1から59まで変えると必要なページまで取得出来るよ。
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')driver.page_sourceで表示したURLを取得します。
その後は、BeautifulSoupで解析して、これを変数soupに入れます。
CSS Selecterで取得したい要素を指定する
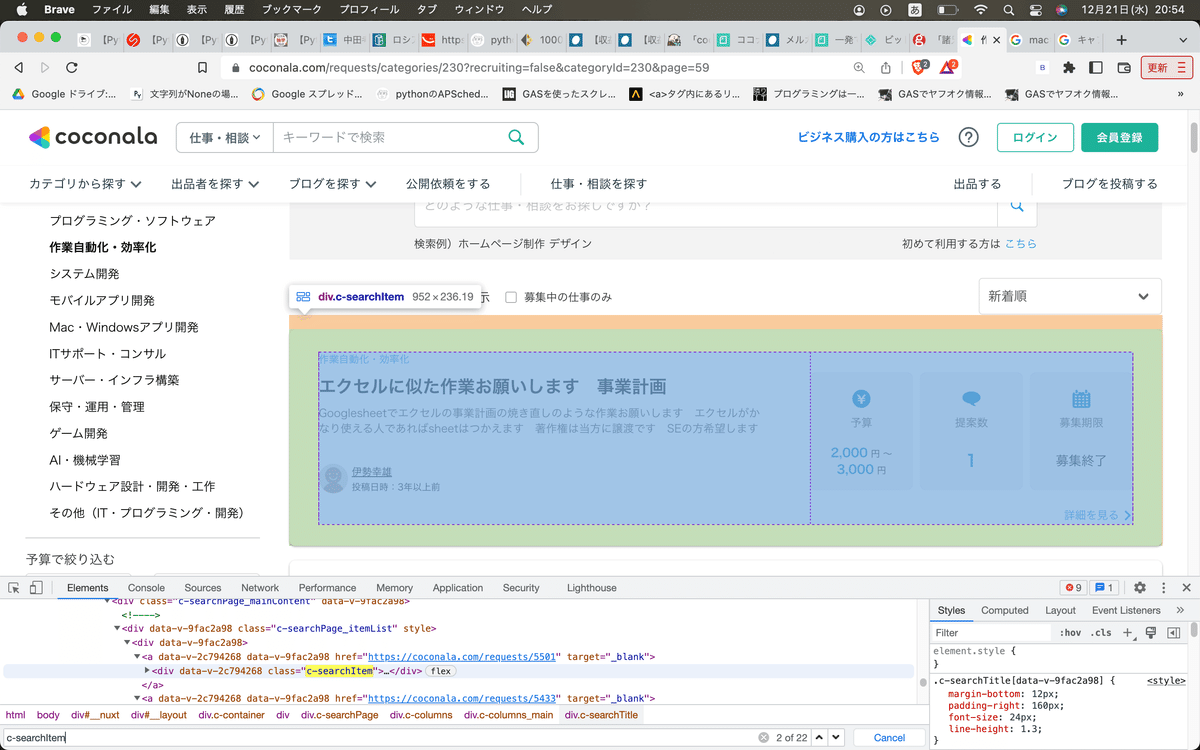
上記の画像を見て頂くと分かる通り、それぞれの案件は('div.c-searchItem') に囲まれており、その中から必要な情報を抽出していきます。
(上のサイトで右クリックから検証を押すと、上記の検証画面が出てくるよ)
#CSS Selecterで要素抜き出し
indi_tags = soup.select('div.c-searchItem') #各詳細ページの項目タグになる。その為、まずは上記の通り、各個別案件をスクレイピングします。
for i, ind in enumerate (indi_tags):
titles = ind.select_one('div.c-itemInfo_title > a').text
urls = ind.select_one('div.c-itemInfo_title > a').get('href')
print(titles)
print(urls)更に各要素から案件のタイトルとURLをスクレイピングします。
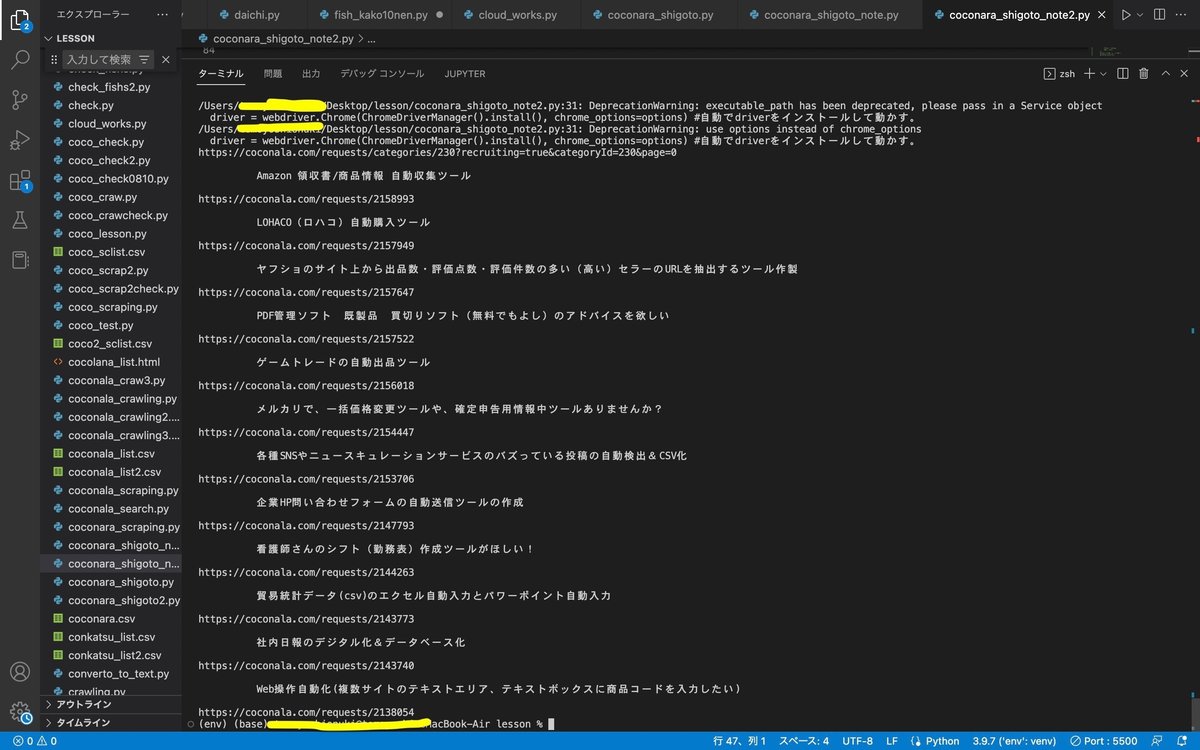
動いた!?(表示された?)
おめでとう!
これで案件の情報はスクレイピング完了です
成功すると下のようにターミナルに表示されているはず!
さあ今回はここまで。
次回はここでスクレイピングした情報を
①自分のラインに送って
②定期実行する方法をシェアするよ。
良かったらTwitterやってます。
分かんないことがあればコメントください。
https://twitter.com/nukey9696
この記事が気に入ったらサポートをしてみませんか?