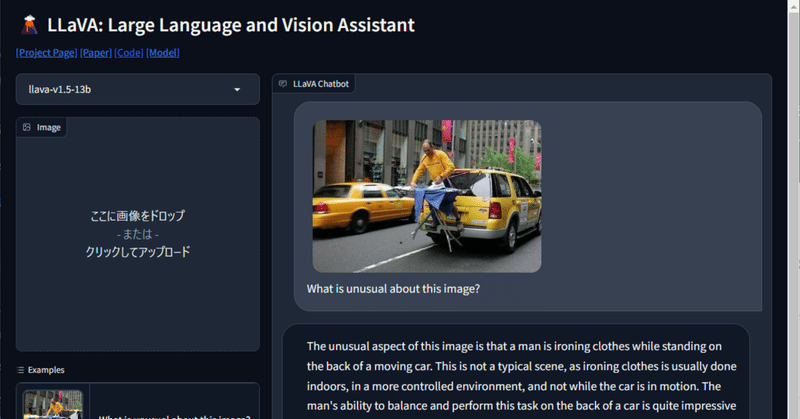
画像分析機能を持つオープンソースLLM『LLaVA-1.5』を試す

gpt-4vのような画像分析機能を持つオープンソースLLM『LLaVA-1.5』が公開されていたのでローカルPC環境(RTX3090 24GB)で試してみました。
LLaVAの特徴
ビジョンおよび言語の理解のためのビジョンエンコーダとLLMを接続する、エンドツーエンドで訓練された大規模なマルチモーダルモデル
マルチモーダル指示に従うデータセットでGPT-4と比較して85.1%の相対スコアを達成、11 のベンチマークでSoTA性能を達成
オープンソース。ヴィジョン指示チューニングデータ、モデル、およびコードベースを公開。ライセンスは研究目的でのみ使用可

とにかく試してみます
インストールはgithubの説明の通り行いました。デモ実行は説明に沿ってcontroller、gradio_web_server、model_workerを起動します。なお、私の環境ではllava-v1.5-13bを--load-8bitオプションをつけて起動しました。
$ python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b --load-8bit
ブラウザでhttp://localhost:7860/を開くとgradioのwebuiで試せます。

gradioインターフェイスのほか、4ビットおよび8ビットの量子化推論もサポートするCLIも用意されていて、LLaVA-1.5-7Bは4ビット量子化で8GB未満のVRAMで利用できるようです。
ローカル環境で画像認識LLMが動くとは。ますます夢が膨らみますね!😆
この記事が気に入ったらサポートをしてみませんか?