
論文紹介: クラスタに分割して効率的にLLMを訓練(c-BTM法)

Twitterのタイムラインで少し話題になっていた、Meta AIのメンバー主体で書かれた以下論文を、(話題についていきたいので😊)超ななめ読みしてみました。
1.概要
通常、大規模言語モデルをトレーニングする場合、数千のGPU上の数十億のすべてのパラメータを同期させる必要があるため大きなコストが必要。
この解決策として、テキストコーパスを関連するドキュメントのセットに分割し、それぞれに対して独立した言語モデル(専門家モデル:Expert Language Models, ELMs)を訓練することで、並列化が容易な訓練に一般化する方法 cluster-Branch-Train-Merge (C-BTM)を提案する。
推論時は、これらの専門家モデルをアンサンブルして使用する。すべてのELMsをすべて使用せず、必要なモデルだけを選択して使用(スパースアンサンブル)することで、効率的に言語モデルを利用できる。
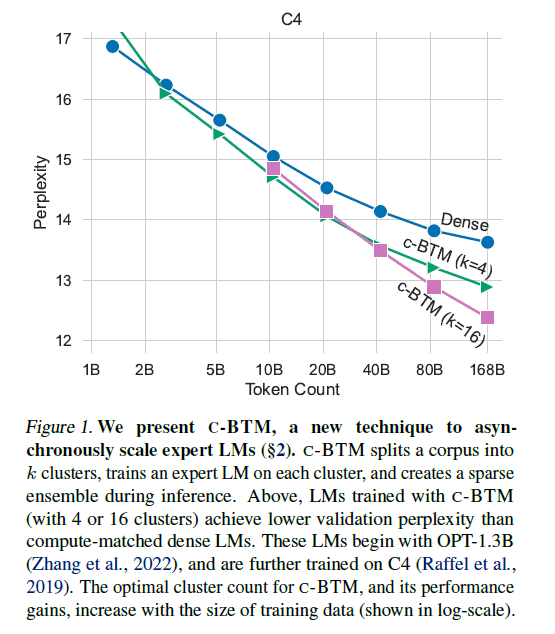

2.c-BTMのトレーニングプロセス
(0) クラスタリング(Cluster):
k-meansクラスタリングを使用した教師なし学習にて、テキストコーパスを関連するドメイン毎のセット(クラスタ)に分割する。

(1)ExpertLMの初期化(Branch):
シード言語モデル(例えば、OPT)を用いて、各クラスタに対する専門家言語モデル(Expert Language Models、ELMs)を初期化する。各クラスタが持つ特性を理解するための「専門家」を生成するステップ。
(2)ELMsの訓練(Train):
各クラスタに対して初期化したELMsを、そのクラスタのデータを用いて独立で訓練する。これにより、各ELMsはそのクラスタの特性をより深く理解する能力を獲得する。
(3)ELMsを統合(Merge):
訓練済のELMsは、スパースな推論(必要なELMsだけを選択し推論)を行うためのセットにマージする。
推論時には、現在のコンテキストの埋め込みと各ELMsのクラスタセンターとの距離に基づいて、ELMsの出力を重み付けを行う。
3.c-BTMの効果
全体の訓練データサイズを同じにしてモデルのパフォーマンスを比較した場合、1つ以上のクラスタで訓練すると、単一クラスタで訓練するよりも常に性能が向上した。ただし、クラスタ数はモデルのサイズ毎に最適値が存在する。
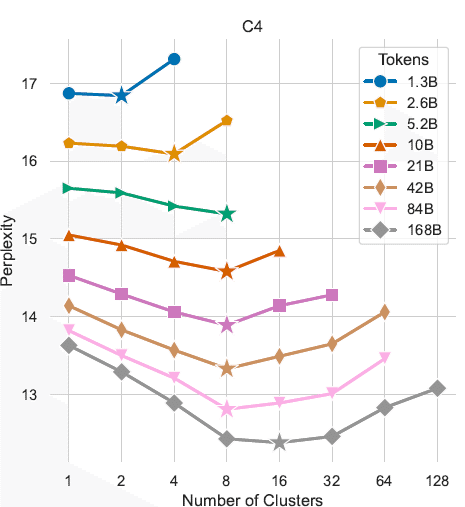
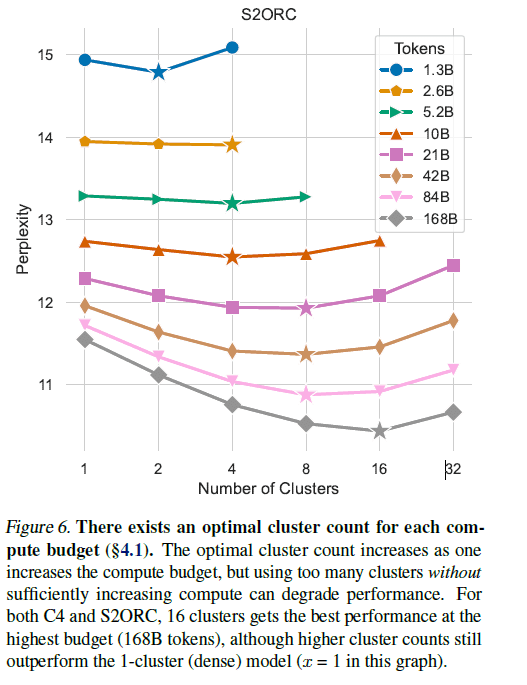

以上、超ざっくりc-BTMの手法を中心に概要ををまとめてみました。
それにしても、恐ろしいほど計算資源を使った研究ですね。ここまで超大規模でなくとも、個人レベルでも使えそうな手法だと思うのでとても興味深い論文だと思いました。
認識の誤りや、重要な論点の取りこぼしなど、お気づきの点がありましたらコメントいただけると幸いです。最後までお読みいただき、ありがとうございました。
220B x 8という噂は本当なんでしょうか…。
この記事が気に入ったらサポートをしてみませんか?