
埋め込み型のデータベースを使った質問への回答:text-embedding-ada-002チュートリアル

OpenAI-Cookbookで公開されている、大量のテキストを駆使して質問に答えるシステム構築に有利な、埋め込み型検索を用いた質問応答の例題を試してみました。
https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
モデルのファインチューニングは例えると、1週間先の試験のために勉強するようなもので、試験本番になると、モデルは詳細を忘れてしまったり、読んだことのない事実を間違って記憶してしまったりするので、大量のテキストから質問に答えるシステムを構築するには、埋め込み型検索を用いた「Search-Ask」方式を使うのがオススメとのこと。
まずは、通常のChatGPTで質問してみましょう。
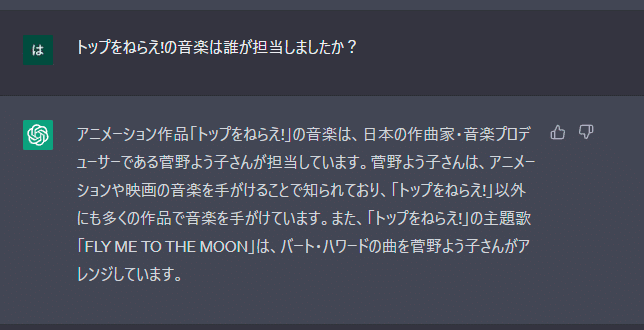
不正解!
菅野よう子さんのトップをねらえ!の音楽も聴いてみたい気がしますが、
正しい情報と嘘の情報を織り交ぜて、文章としてはもっともらしい回答をしてくるのが始末が悪いですよね。
というわけで、モチベーションが沸いたので、さっそくopenai-cookbookの例題をはじめます。今回もgoogle colabにお世話になります。
ライブラリーのインストール
!pip install openai > /dev/null
!pip install tiktoken >/dev/nullOpenAI APIキーを設定(有料)
# OpenAI APIPキーの設定
openai.api_key = "YOUR OPENAI_API_KEY"埋め込み用のデータの準備
アニメ「トップをねらえ!」のwikipediaカテゴリーを埋め込み表現に変換したデータを準備します。なお、変換に用いた埋め込みモデル「text-embedding-ada-002」はnpakaさんが概要を簡潔にまとめてくれています。感謝。以前のモデルに比べて性能が上がって、コストがとても下がった安旨モデルとのこと。
収集: 必要なWikipediaの記事をダウンロード
チャンク: ドキュメントを短い半自己完結型のセクションに分割し、埋め込む。
埋め込み:各セクションにはOpenAI APIで埋め込み表現(ベクトル表現)に変換
保存: CSVファイルで保存(大規模なデータセットの場合はPineconeなどのベクトルデータベースを使うとよい)
# imports
import mwclient # for downloading example Wikipedia articles
import mwparserfromhell # for splitting Wikipedia articles into sections
import openai # for generating embeddings
import pandas as pd # for DataFrames to store article sections and embeddings
import re # for cutting <ref> links out of Wikipedia articles
import tiktoken # for counting tokens# get Wikipedia pages about トップをねらえ!
CATEGORY_TITLE = "Category:トップをねらえ!"
WIKI_SITE = "ja.wikipedia.org"
def titles_from_category(
category: mwclient.listing.Category, max_depth: int
) -> set[str]:
"""Return a set of page titles in a given Wiki category and its subcategories."""
titles = set()
for cm in category.members():
if type(cm) == mwclient.page.Page:
# ^type() used instead of isinstance() to catch match w/ no inheritance
titles.add(cm.name)
elif isinstance(cm, mwclient.listing.Category) and max_depth > 0:
deeper_titles = titles_from_category(cm, max_depth=max_depth - 1)
titles.update(deeper_titles)
return titles
site = mwclient.Site(WIKI_SITE)
category_page = site.pages[CATEGORY_TITLE]
titles = titles_from_category(category_page, max_depth=1)
# ^note: max_depth=1 means we go one level deep in the category tree
print(f"Found {len(titles)} article titles in {CATEGORY_TITLE}.")Found 14 article titles in Category:トップをねらえ!.
# define functions to split Wikipedia pages into sections
# 検索に不要なセクションを無視
SECTIONS_TO_IGNORE = [
"See also",
"References",
"External links",
"Further reading",
"Footnotes",
"Bibliography",
"Sources",
"Citations",
"Literature",
"Footnotes",
"Notes and references",
"Photo gallery",
"Works cited",
"Photos",
"Gallery",
"Notes",
"References and sources",
"References and notes",
]def all_subsections_from_section(
section: mwparserfromhell.wikicode.Wikicode,
parent_titles: list[str],
sections_to_ignore: set[str],
) -> list[tuple[list[str], str]]:
"""
From a Wikipedia section, return a flattened list of all nested subsections.
Each subsection is a tuple, where:
- the first element is a list of parent subtitles, starting with the page title
- the second element is the text of the subsection (but not any children)
"""
headings = [str(h) for h in section.filter_headings()]
title = headings[0]
if title.strip("=" + " ") in sections_to_ignore:
# ^wiki headings are wrapped like "== Heading =="
return []
titles = parent_titles + [title]
full_text = str(section)
section_text = full_text.split(title)[1]
if len(headings) == 1:
return [(titles, section_text)]
else:
first_subtitle = headings[1]
section_text = section_text.split(first_subtitle)[0]
results = [(titles, section_text)]
for subsection in section.get_sections(levels=[len(titles) + 1]):
results.extend(all_subsections_from_section(subsection, titles, sections_to_ignore))
return results
def all_subsections_from_title(
title: str,
sections_to_ignore: set[str] = SECTIONS_TO_IGNORE,
site_name: str = WIKI_SITE,
) -> list[tuple[list[str], str]]:
"""From a Wikipedia page title, return a flattened list of all nested subsections.
Each subsection is a tuple, where:
- the first element is a list of parent subtitles, starting with the page title
- the second element is the text of the subsection (but not any children)
"""
site = mwclient.Site(site_name)
page = site.pages[title]
text = page.text()
parsed_text = mwparserfromhell.parse(text)
headings = [str(h) for h in parsed_text.filter_headings()]
if headings:
summary_text = str(parsed_text).split(headings[0])[0]
else:
summary_text = str(parsed_text)
results = [([title], summary_text)]
for subsection in parsed_text.get_sections(levels=[2]):
results.extend(all_subsections_from_section(subsection, [title], sections_to_ignore))
return results# split pages into sections
# may take ~1 minute per 100 articles
wikipedia_sections = []
for title in titles:
wikipedia_sections.extend(all_subsections_from_title(title))
print(f"Found {len(wikipedia_sections)} sections in {len(titles)} pages.")Found 210 sections in 14 pages.
# clean text
def clean_section(section: tuple[list[str], str]) -> tuple[list[str], str]:
"""
Return a cleaned up section with:
- <ref>xyz</ref> patterns removed
- leading/trailing whitespace removed
"""
titles, text = section
text = re.sub(r"<ref.*?</ref>", "", text)
text = text.strip()
return (titles, text)
wikipedia_sections = [clean_section(ws) for ws in wikipedia_sections]
# filter out short/blank sections
def keep_section(section: tuple[list[str], str]) -> bool:
"""Return True if the section should be kept, False otherwise."""
titles, text = section
if len(text) < 16:
return False
else:
return True
original_num_sections = len(wikipedia_sections)
wikipedia_sections = [ws for ws in wikipedia_sections if keep_section(ws)]
print(f"Filtered out {original_num_sections-len(wikipedia_sections)} sections, leaving {len(wikipedia_sections)} sections.")Filtered out 22 sections, leaving 188 sections.
# print example data
for ws in wikipedia_sections[:5]:
print(ws[0])
display(ws[1][:77] + "...")
print()['トップをねらえ!']
{{Otheruseslist|1988年に制作されたOVA|スピンオフとなるメディアミックス作品群|トップをねらえ! NeXT GENERATION|2...
['トップをねらえ!', '== 概要 ==']
[[庵野秀明]]初監督作品。本作品は『[[王立宇宙軍 オネアミスの翼]]』だけを制作して解散するはずのガイナックスが興行不振により生まれた借金を返済するた...
(以下略)
GPT_MODEL = "gpt-3.5-turbo" # only matters insofar as it selects which tokenizer to use
def num_tokens(text: str, model: str = GPT_MODEL) -> int:
"""Return the number of tokens in a string."""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def halved_by_delimiter(string: str, delimiter: str = "\n") -> list[str, str]:
"""Split a string in two, on a delimiter, trying to balance tokens on each side."""
chunks = string.split(delimiter)
if len(chunks) == 1:
return [string, ""] # no delimiter found
elif len(chunks) == 2:
return chunks # no need to search for halfway point
else:
total_tokens = num_tokens(string)
halfway = total_tokens // 2
best_diff = halfway
for i, chunk in enumerate(chunks):
left = delimiter.join(chunks[: i + 1])
left_tokens = num_tokens(left)
diff = abs(halfway - left_tokens)
if diff >= best_diff:
break
else:
best_diff = diff
left = delimiter.join(chunks[:i])
right = delimiter.join(chunks[i:])
return [left, right]
def truncated_string(
string: str,
model: str,
max_tokens: int,
print_warning: bool = True,
) -> str:
"""Truncate a string to a maximum number of tokens."""
encoding = tiktoken.encoding_for_model(model)
encoded_string = encoding.encode(string)
truncated_string = encoding.decode(encoded_string[:max_tokens])
if print_warning and len(encoded_string) > max_tokens:
print(f"Warning: Truncated string from {len(encoded_string)} tokens to {max_tokens} tokens.")
return truncated_string
def split_strings_from_subsection(
subsection: tuple[list[str], str],
max_tokens: int = 1000,
model: str = GPT_MODEL,
max_recursion: int = 5,
) -> list[str]:
"""
Split a subsection into a list of subsections, each with no more than max_tokens.
Each subsection is a tuple of parent titles [H1, H2, ...] and text (str).
"""
titles, text = subsection
string = "\n\n".join(titles + [text])
num_tokens_in_string = num_tokens(string)
# if length is fine, return string
if num_tokens_in_string <= max_tokens:
return [string]
# if recursion hasn't found a split after X iterations, just truncate
elif max_recursion == 0:
return [truncated_string(string, model=model, max_tokens=max_tokens)]
# otherwise, split in half and recurse
else:
titles, text = subsection
for delimiter in ["\n\n", "\n", ". "]:
left, right = halved_by_delimiter(text, delimiter=delimiter)
if left == "" or right == "":
# if either half is empty, retry with a more fine-grained delimiter
continue
else:
# recurse on each half
results = []
for half in [left, right]:
half_subsection = (titles, half)
half_strings = split_strings_from_subsection(
half_subsection,
max_tokens=max_tokens,
model=model,
max_recursion=max_recursion - 1,
)
results.extend(half_strings)
return results
# otherwise no split was found, so just truncate (should be very rare)
return [truncated_string(string, model=model, max_tokens=max_tokens)]
# split sections into chunks
MAX_TOKENS = 1600
wikipedia_strings = []
for section in wikipedia_sections:
wikipedia_strings.extend(split_strings_from_subsection(section, max_tokens=MAX_TOKENS))
print(f"{len(wikipedia_sections)} Wikipedia sections split into {len(wikipedia_strings)} strings.")print(wikipedia_strings[1])# calculate embeddings
EMBEDDING_MODEL = "text-embedding-ada-002" # OpenAI's best embeddings as of Apr 2023
BATCH_SIZE = 1000 # you can submit up to 2048 embedding inputs per request
embeddings = []
for batch_start in range(0, len(wikipedia_strings), BATCH_SIZE):
batch_end = batch_start + BATCH_SIZE
batch = wikipedia_strings[batch_start:batch_end]
print(f"Batch {batch_start} to {batch_end-1}")
response = openai.Embedding.create(model=EMBEDDING_MODEL, input=batch)
for i, be in enumerate(response["data"]):
assert i == be["index"] # double check embeddings are in same order as input
batch_embeddings = [e["embedding"] for e in response["data"]]
embeddings.extend(batch_embeddings)
df = pd.DataFrame({"text": wikipedia_strings, "embedding": embeddings})
# save document chunks and embeddings
SAVE_PATH = "gun_buster.csv"
df.to_csv(SAVE_PATH, index=False)保存した埋め込みファイルの読み込んで、dfにリスト型で格納しなおす
embeddings_path = "gun_buster.csv"
df = pd.read_csv(embeddings_path)
# convert embeddings from CSV str type back to list type
df['embedding'] = df['embedding'].apply(ast.literal_eval)
df
Serch関数の定義
ユーザークエリおよび、「テキスト」と「埋め込みベクトル表現」を持つデータフレームdfを受け取る。
ユーザークエリをOpenAI APIで埋め込みベクトル表現に変換する。
openai.Embedding.create( model=EMBEDDING_MODEL, input=query, )
クエリ埋め込みとテキスト埋め込みの距離を利用して、テキストをランク付けする
-> 返り値:
上位N個のテキストを、関連性でランク付けしたもの。
対応する関連性スコア
# search function
def strings_ranked_by_relatedness(
query: str,
df: pd.DataFrame,
relatedness_fn=lambda x, y: 1 - spatial.distance.cosine(x, y),
top_n: int = 100
) -> tuple[list[str], list[float]]:
"""Returns a list of strings and relatednesses, sorted from most related to least."""
query_embedding_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=query,
)
query_embedding = query_embedding_response["data"][0]["embedding"]
strings_and_relatednesses = [
(row["text"], relatedness_fn(query_embedding, row["embedding"]))
for i, row in df.iterrows()
]
strings_and_relatednesses.sort(key=lambda x: x[1], reverse=True)
strings, relatednesses = zip(*strings_and_relatednesses)
return strings[:top_n], relatednesses[:top_n]ASK関数の定義
ユーザのクエリを受け取る
クエリに関連するテキストを検索。
検索されたテキストをGPT用の入力メセージに詰め込む
GPTに送信
-> 返り値:
GPTの回答
def num_tokens(text: str, model: str = GPT_MODEL) -> int:
"""Return the number of tokens in a string."""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def query_message(
query: str,
df: pd.DataFrame,
model: str,
token_budget: int
) -> str:
"""Return a message for GPT, with relevant source texts pulled from a dataframe."""
strings, relatednesses = strings_ranked_by_relatedness(query, df)
introduction = 'Use the following article on Japanese animation to answer the questions that follow. If you cannot find the answer in the article, write "No answer found".'
question = f"\n\nQuestion: {query}"
message = introduction
for string in strings:
next_article = f'\n\nWikipedia article section:\n"""\n{string}\n"""'
if (
num_tokens(message + next_article + question, model=model)
> token_budget
):
break
else:
message += next_article
return message + question
def ask(
query: str,
df: pd.DataFrame = df,
model: str = GPT_MODEL,
token_budget: int = 4096 - 500,
print_message: bool = False,
) -> str:
"""Answers a query using GPT and a dataframe of relevant texts and embeddings."""
message = query_message(query, df, model=model, token_budget=token_budget)
if print_message:
print(message)
messages = [
{"role": "system", "content": "You answer questions about the 2022 Winter Olympics."},
{"role": "user", "content": message},
]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0
)
response_message = response["choices"][0]["message"]["content"]
return response_messageSearch-Askの実施
ask('トップをねらえ!の音楽は誰が作曲しましたか?')'トップをねらえ!の音楽は田中公平が作曲しました。'
正解! おしまい。お疲れ様でした。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?