
Guanaco-33b / ChatGPTの99%の性能のチャットAIがローカルPCで動く!?

ツイッターのタイムラインを眺めていると、QLoRAという手法を使って16ビットのファインチューニングの性能を維持しながら4bit量子化することで、単一GPUによるトレーニングで、ChatGPTの99%の性能を達成したという投稿を見かけました。
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
— Tim Dettmers (@Tim_Dettmers) May 24, 2023
Paper: https://t.co/J3Xy195kDD
Code+Demo: https://t.co/SP2FsdXAn5
Samples: https://t.co/q2Nd9cxSrt
Colab: https://t.co/Q49m0IlJHD pic.twitter.com/UJcowpfhpH
というわけで、早速ためしてみます!
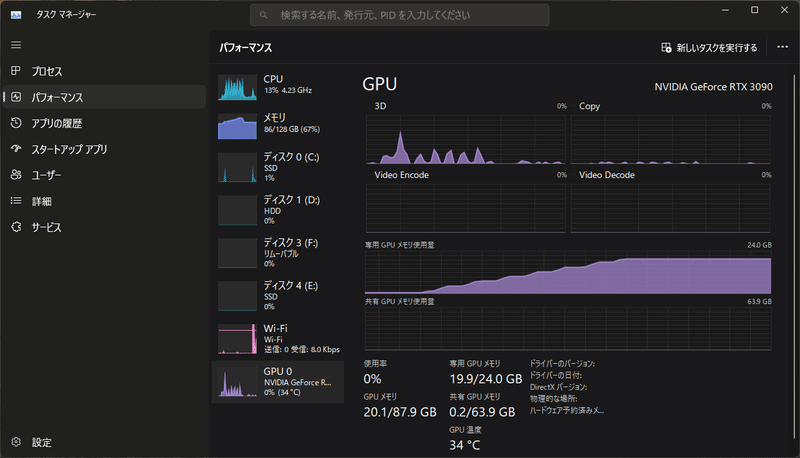
手元のPCのRTX3090でギリギリ動きそうなサイズのGuanaco-33bは、LLaMAのLoRAモデルのほか、本体のLLaMA-33B にマージ済みのモデルも公開されていたので、今回はこちらを試しました。
13Bのモデルでも10GBのサイズですから、これならRTX3060でも動きそうですね。
実行手順🐐
モデルをhuggingfaceからダウンロード
colabのサンプルを参考にして、ローカルPCにダウンロードしたモデル、load_in_4bit オプションで読み込み
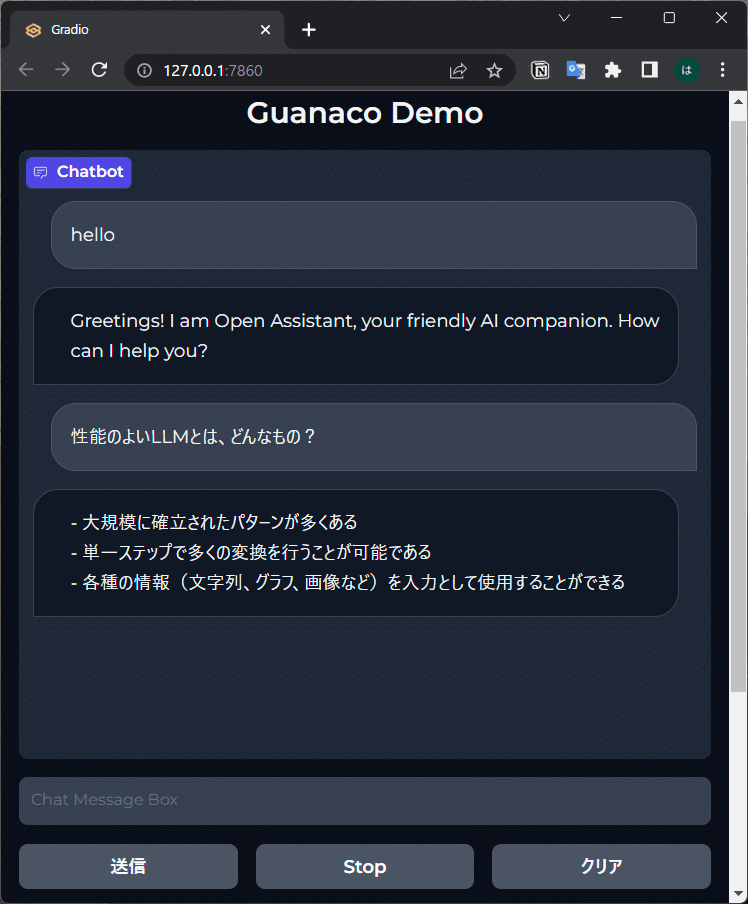
colab サンプルのgradio デモを起動。
gradioを起動するとローカル URLが表示されるので、ブラウザで表示
なお、7B、13Bのモデルはcolabの無償版でも試せると思います。
今回はローカルPCでLLMを実行するロマンを優先しました。😅
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
model_name = "/home/xxxx/models/guanaco-33b-merged"
# adapters_name = 'timdettmers/guanaco-7b'
print(f"Starting to load the model {model_name} into memory")
m = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
# torch_dtype=torch.bfloat16,
device_map={"": 0}
)
# m = PeftModel.from_pretrained(m, adapters_name)
# m = m.merge_and_unload()
tok = LlamaTokenizer.from_pretrained(model_name)
tok.bos_token_id = 1
stop_token_ids = [0]
print(f"Successfully loaded the model {model_name} into memory")Starting to load the model /home/xxxx/models/guanaco-33b-merged into memory
Loading checkpoint shards: 100%|██████████| 7/7 [00:31<00:00, 4.47s/it]
Successfully loaded the model /home/xxxx/models/guanaco-33b-merged into memory
まとめ・感想
一応、日本語でも会話できましたが、学習データの品質がイマイチなのか、ChatGPT並みの自然な会話と言うには、正直少し遠い気がします。英語であればgpt-3.5-turbo並みなんだろうと思います。
今回試してみた33Bサイズのモデルだと、さすがにGPUメモリに余裕がないので、今のところローカルPCでの普段使いには、Vicuna-13b系をload_in_8bitで使うのが良さげな気がします。
それでも、65BサイズのLLMが単一GPU でファインチューニングできて、ChatGPTに近い高品質なLLMを生成できたというのは驚きです。このQLoRAの手法をほかのモデルの学習に適用するなど、LLMのファインチューニングがもっと身近になりそうですね。
最後までお読みいただき、ありがとうございました。
現場からは以上です
大きいメモリのGPUがほしいと思いH100の価格を調べて絶句。計算速度はいいからメモリだけでも80GBくらいの家庭用GPU、出ないかなぁ。
この記事が気に入ったらサポートをしてみませんか?