
【論文紹介】大規模言語モデルにおけるニューロンの挙動について

大規模言語モデルにおける人工ニューロンの挙動をテーマにした以下論文が面白かったので、ざっくり目についたキーワードを抜き出してみました。
理解不足など多分にあると思いますので、興味を持たれた方は、ぜひ原文をご確認ください。
概要
LLMの内部構造を理解するため、パラメータの異なる125Mから66BまでのMeta社のOPTファミリーのモデル内部の人工ニューロンの挙動を分析した
キーワード
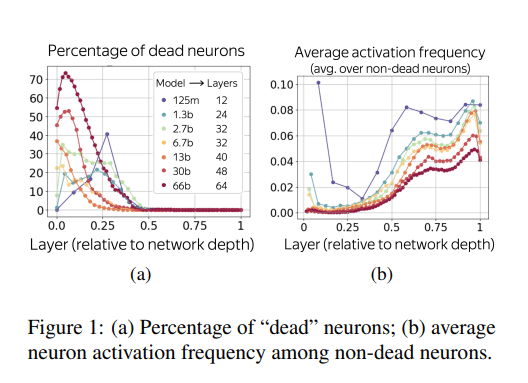
活性化しないニューロン(Dead Neurons)
ネットワークの入力部付近の層では、多くの活性化しない「デッドニューロン」が存在しており、特に66B(660億)モデルでは、一部の層で70%以上のニューロンが活性化していない。
ネットワークの前半はデッドニューロンの割合が高く、後半はほとんどのニューロンが「活性化」している。
著者らは、この層間での疎さの違いは、初期層では「概念と対応するニューロン」の比率が後半の層よりも小さいすなわち、前半の層でエンコードされる概念は大部分が浅く、おそらくは離散的(例えば、語彙的)であり、後層ではより高次元のセマンティクスや推論を学習しているのではないかと述べている
トークン・N-gram検出ニューロン
トークンやn-グラム(連続するn個の単語や文字)を検出するニューロンが大きなモデルではより多く存在することが確認された。これらのニューロンは、次のトークン候補を直接活性化することだけでなく、特定のトークンを抑制する能力も持っている

モデルが大きくなるに従って、より少ない数のn-グラム(トークンの連続)がカバーできるニューロンの割合が増えていく。例えば3-gram検出ニューロンは、30Bパラメータのモデルで急激に増えており、大きなモデルと小さなモデルの表現力に大きな違いが表れることを示唆された

位置情報ニューロン
Input Embeddingで事前に付加される絶対位置情報とは別に、位置情報に反応するニューロンが存在する。位置情報ニューロンにはいくつかの活性化パターン(振動性、絶対位置の両端で活性、片方で活性)がある

小さいモデル(6.7bパラメータ以下)は、振動性のニューロンに大きく依存している一方で、大きなモデルは振動性のニューロンを持っていないことが多い。これは、小さいモデルが絶対位置をより正確にエンコードする一方で、大きなモデルは絶対位置よりも「意味のある何か」に依存している可能性が高いことを示唆している

すべてのモデルが絶対位置エンコーディングで訓練されているにもかかわらず、より強力なモデルは絶対位置から抽象化する傾向がある
モデルが大きくなると、死んだニューロンやトークン検出器が増え、絶対位置に対する焦点が減少する
TransformerベースLLMにおけるFFNの役割について
この論文では、フィードフォワードネットワーク(FFN)の役割について、各「キー」が訓練例中のテキストパターンと相関し、各「バリュー」が出力語彙に対する確率分布を生成することで、キー・バリュー記憶として働くという説に、疑問を投げかけています
FFNが単純なキー・バリュー記憶として機能するわけではなく、より多様な、または特定のタスクに特化した方法で動作している可能性を示唆している
感想
自分の理解が追い付かない部分も多かったですが、とても興味深く読むことができました。興味を持たれた方は、いちど目をとおされてはいかがでしょうか
私には詳しい知識はありませんが、人間の脳も部位ごとに役割分担していることから、LLMがどういった原理で動作しているかを理解することは、我々の脳や思考の発生原理や働きを理解するうえでも役にたつかもしれません。
最後までお読みいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?