
【論文紹介】アテンション・シンクを用いた効率的なストリーミング言語モデル

興味深い論文を見つけたので、ざっとまとめました。
私の理解不足は多々ありますので、興味を持たれた方はぜひ原文をご参照ください。
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis
概要
この研究では、大規模な言語モデルを実行するための新しいフレームワークであるStreamingLLMを提案しています。これは、従来のアプローチであるWindow attentionがテキストの長さがキャッシュサイズを超えると処理が失敗するという問題を解決するものです。
現在のLLMsには二つの主な課題があります。1つ目は、デコーディング段階で以前のすべてのトークンのキーと値の状態(KV)をキャッシュすると、メモリ使用量やデコーディングの遅延が増加すること。2つ目は、LLMsが事前学習時に設定されたアテンションウィンドウのサイズを超えると、そのパフォーマンスが低下することです。
StreamingLLMでは、これらの問題を解決するために「アテンションシンク」を導入し、初期のトークンに対するアテンションスコア(注目度)を保持することで、モデルのパフォーマンスを安定させることができました。スライディングウィンドウのKVとともに、最初の数個のトークンのKV値を保持しますることで、無限長のテキストに対してトークンをモデリングすることが可能となったとのこと。

Attention sinks アテンションシンク
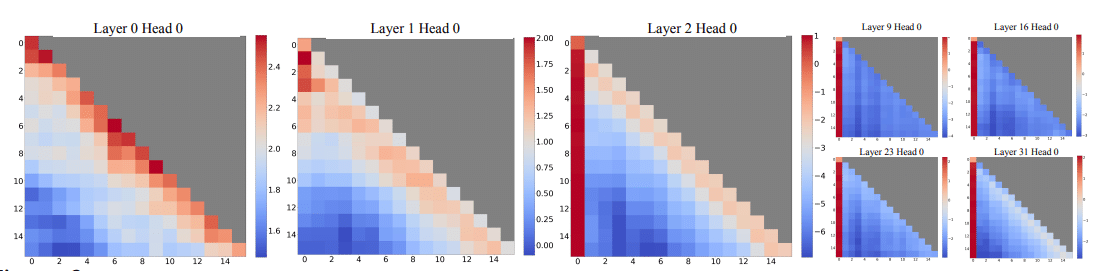
自己回帰的なLLMsにおいて、タスクとの関連性に関係なく、初期のトークンに驚くほど大量のアテンションスコアが割り当てられる興味深い現象が見られた(図2)。これらのトークンを筆者は「Attention sinks: アテンションシンク」と名付けた。これらは意味的には重要ではないにもかかわらず、大量のアテンションスコアが集まる。この理由は、ソフトマックス操作によるもので、これはすべてのコンテキストトークンのアテンションスコアを1に合計する必要があるところに原因がある。したがって、現在のクエリが多くの以前のトークンと強い一致を持たない場合でも、モデルはこれらの不要なアテンション値をどこかしらに割り当てる必要がある。初期トークンは、自己回帰的な言語モデリングの性質から、ほとんどすべての後続のトークンに対して見えるため、結果的にアテンションシンクとしての役割を果たすようトレーニングされる。
トレーニング済みLLMへの適用
トレーニング済みLLMでストリーミングを有効にするため、ローリングKVキャッシュという方法を用いる。キャッシュ内の相対的な位置情報を維持することでトークンがスライディングウィンドウ内で動的に移動するときでも、アテンション計算の一貫性が保たれる。

ウィンドウ外となったトークンが発生した場合でも、アテンションシンクへの相対位置の整合性を保つ
StreamingLLMのデコードの効率性
シンクトークンを使用して訓練されたモデルは、標準設定(Vanilla)で訓練されたモデルと同様の性能を示すことが確認されています。またシンクトークンを導入したモデルは、通常のモデルと比較して、ストリーミング時の性能が高くなることが示されています。キャッシュサイズが増加すると、StreamingLLMは線形的なデコーディング速度の向上を示す一方、従来のスライディングウィンドウアプローチでは、デコードの遅延が二次的に増加しますため、StreamingLLMが非常に効率的であることが示されています。

サンプルコード
サンプルコードも公開されています!読まねば。
感想
中間トークンが破棄されることで論理的な洞察力が欠ける可能性があることなど、利用用途は選ぶかもしれないですが学習済みモデルにも適用できて性能を発揮する画期的なアイデアだと思います。チャットアプリの用途だと十分なキャッシュサイズが確保できていれば問題なさそうです。
LLMの学習挙動の観察に基づいて性能改善をおこなった、とても興味深い取り組みだと思いました。
この記事が気に入ったらサポートをしてみませんか?