
Einstein Analyticsのデータフローの読み解き方について(1)

最初にこれ見たときは面食らいました。
えっ、最初に作ったデータセットビルダーのままじゃだめだったの??ってなりませんでした?僕はなりました。あそこに戻れると良いのになって思いますよね。とはいえ、実はこの画面が便利なのです。実は。
下側のブロックで説明します
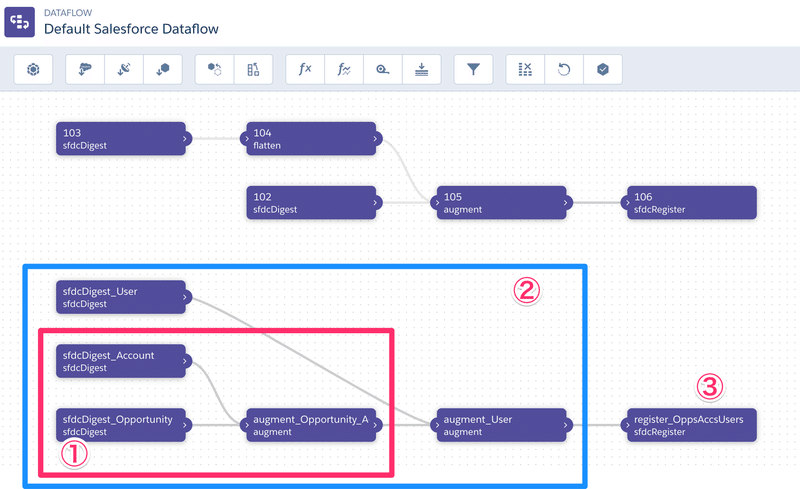
sdfcDigestっていうのが一番左に並んでます。Salesforceからのデータをロードする場合はこれを使って配置します。AccountとOpportunityとUserが配置されています。
1の中では、OpportunityのノードにAccountのノードを、argmentノードをつかってマージしています。
2の中では、マージしたデータセットに更にUserのノードをargmentノードを使ってマージしています。
最終的に3ですべてのデータを出力しますよという処理の流れです。sfdcRegisterノードを置くことで、データセットとして表示されます。
ツールバーのあれそれ

タブのアイコンはこんなイメージ。
データの取り込み先は以下の3つを使います
sfdcDigest:Salesforceからの取り込み
digest:上述に加え、その他の外部接続も含んだデータ
edgemart:CSVで予め取り込んでおいたデータの使用
argmentノードの使い方
例えば、1では、商談に取引先をマージしています。用途としては、商談に主従関係として入っている取引先IDがあるのですが、そのIDを使って取引先名を取り出したいというものです。
Salesforceは正規化されているので(商談と取引先は別オブジェクトに入っている)、それをargmentノードを使って呼び出すことで非正規化するというアクションを行っています。つまり、一つのエクセルシートに並べてしまうということです。エクセルで言えば、vlookupで他のシートからデータをひっぱってくるという数式項目と同じです。
argmentノードの左右について
接続の方向性というものがあります。
左側を商談ノードにして、右側を取引先にしてあります。
左側ノードのデータはすべて使われます。右側ノードは必要なものを選択します。ここでいえば、取引先名がわかれば良いので、取引先名のみ選択すればOK。先程も言いましたが、vlookupですので、ここで選択した項目がメインとなるデータのシートに追加されるというイメージを持っていただければよいかと思います。
左右を間違えると、うまくいかないので注意。図の通り、データフローの左から入ってきて右側に抜けていくイメージで良いと思います。選ぶノードを間違えないようにしましょう。
理解すれば簡単ですね!?
なれるまではこんなかんじでやってました
実際にデータフロー画面で操作できるようになる前までは、作成>データセットとボタンを押して、データセットビルダーを呼び出し、既存のデータフローを保存先にして保存。できたデータフローから、重複するノードを切り替えて新規作成で重複したノードを削除するみたいなやり方です。
noteにはこれまでの経験を綴っていこうかと思います。サポートによって思い出すモチベーションが上がるかもしれない。いや、上がるはずです。