Stable Diffusion、UNetのすべて

UNetの構造について書いていきます。またHyperNetworksやLoRAといったモジュールについても説明します。間違っているところがあっても謝りません。最初は大まかにみて徐々に小さいモジュール単位でみていきます。ResNetやVision Transformerのことを全く知らない人が読むことは想定していません。実装はdiffusersやStabilityAIのくそコードなんかよりわかりやすいリポジトリがあるのでそれを参考にします。
全部作った後この記事より圧倒的に分かりやすい記事見つけてしまって悲しくなった。こっちなら誰でもわかります。
UNetへの入力
UNetの入力は3つあります。
潜在変数:画像をVAEでエンコードしたもの、4チャンネルで縦横それぞれ8分の1に圧縮される。
テキストエンコーダの出力:プロンプトをテキストエンコーダでエンコードしたもの。サイズは(トークン長、768(SDv1.x) or 1024(SDv2.x) )
Time step:ノイズ除去の何ステップ目かを入力する。これによりステップごとにモデルを学習せずに済む。
25個のブロック
UNetは25個のブロックに分けられます。この分け方は層別マージとかの層別に合わせています。512×512画像を生成する場合のサイズを書いています。数字は(チャンネル数, 画像サイズ)です。

UNetでは各ブロックを左から右に一直線で計算するだけでなく、INPUT側の12ブロックの出力がそれぞれOUTPUT側の12ブロックの入力にチャンネル方向で結合されます。たとえばOUT5の入力はOUT4の出力とIN8の出力が結合されて1920チャンネルの画像となります。またこの図には表示されていませんが、テキストエンコーダの出力や、Time stepも各ブロックに入力されます。
IN、MID、OUTはdown, mid, upとかencoder, middle, decoderとかいろいろな呼び方があります。
各ブロックの分類
各ブロックはそれぞれConv層、ResNet層、Transformer層、Upsample層、Downsample層などから構成されます。それぞれの層の説明は置いておいて、各ブロックの構成を確認していきます。
IN0


IN0に入ってるとは言いづらいが、層別マージとかではこの層もIN0として扱われる。
入力に一番近い層で、4チャンネルの潜在変数を320チャンネルにするConv層にする単層のブロックです。
Time embedding層ではtimestepをcosやsinを使った意味わかんない式でいい感じの埋め込みベクトル(320次元)に変換したあと、linear層で1280次元ベクトルに変換します。
IN 3, 6, 9

Downsample層です。ストライド2のConv層で、出力の大きさが縦横それぞれ2分の1になります。プーリング層じゃないんですね。
IN 1, 2, 4, 5, 7, 8
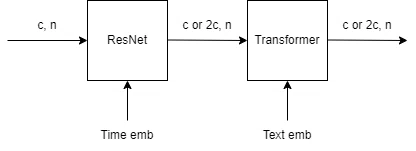
ResNet層⇒Transformer層という順番で処理される基本的なブロックです。ただしDownsample層の直後にあるブロックでは、チャンネル数が2倍になります。
IN 10, 11

ResNet層1つの単純なブロックです。
MID

ResNet層⇒Transformer層⇒ResNet層という感じのブロックです。一番大きいですね。
OUT 0, 1

INの10, 11とほとんど同じですが、INの10, 11の出力も受け取るので入力のチャンネル数が倍になっています。
OUT 2

IN 9に対応するUpsample層です。Upsampleには転置畳み込みではなく、学習パラメータのないtorch.nn.functional.interpolateが使われているようですね。
OUT 5, 8

IN 3,6に対応するUpsample層です。OUT 2からさらにTransformer層が追加されています。
OUT 3, 4, 6, 7, 9 ,10
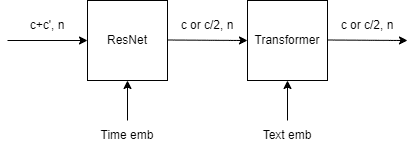
IN 1, 2, 4, 5, 7, 8に対応して、ほとんど同じです。Upsample直後の層はチャンネル数が2分の1になります。
OUT 11

最後の層です。出力は潜在変数に含まれるノイズで、サイズは同じになります。
それでは各モジュール単位で見ていきましょう。といってもConv層は特にいうことがないので、ResNet層とTransformer層を説明します。
ResNet
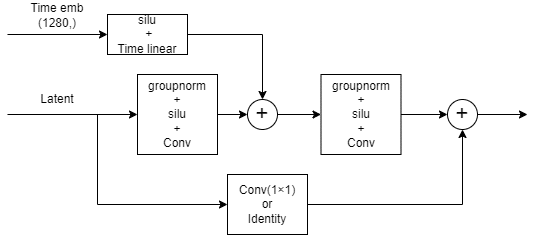
ResNet層はスキップコネクションを導入した畳み込み層です。SDのUNetではここにTime embeddingが入力されます。Time embeddingは1280次元ベクトルになっていますが、これを全結合層でLatentのチャンネル数次元ベクトルに変換したあと、中間の層で足し算します(幅、高さ方向でブロードキャストされる)。
スキップコネクションでは入力形状を合わせるため、フィルターサイズ1の畳み込み層があります。入力と出力が同じ形状の場合はこの層は恒等変換になります。
Transformer

Vision Transformer層です。スキップコネクションだらけで気持ち悪いですね。最初の層はパッチ分割+埋め込みに変換するための層ですが、SDのUNetではパッチサイズは1です。そのため1×1ConvになるわけですがこれはLinearに置き換えられます。SD1系は1×1Conv、SD2系はLinearとして実装されています。またCross Attention層にテキストエンコーダの出力が入力されます。Transformer層では入力と出力で形状が変わりません。この辺からLayerNormとかはめんどくさくなってきたので省略してます。
Attention

Self Attentionではq,k,vにLatentを、Cross Attentionではk,vにはテキストエンコーダの出力が渡されます。xformersはこの内積とかしてる部分(scaled dot product attention)に適用されます。つまりここがVRAM使用量のピークなんでしょうね。書いてませんがmulti head attentionなので、headの分割を行っています。head数はSDv1系は8固定ですが、SDv2系はチャンネル数÷64になってます。
Cross Attentionの場合、qは(チャンネル数, 幅×高さ)、k,vは(トークン数, 幅×高さ)という形状になっています。qk^Tvは(チャンネル数、幅×高さ)となり入力と出力が一致します。ここでトークン数は最終的な形状に影響しないことが分かると思います。これがトークン長の拡張ができる理由です。
テキストエンコーダの出力はSDv1系が768次元で、SDv2系が1024次元です。そのためCross Attentionの形状はv1とv2で異なります。
FeedForward

1層目がgated linear unitという出力を2分割にして要素ごとに積をとるという層になっています。
アダプターの説明
UNetに追加でネットワークを挿入することで、生成画像をコントロールする手法がいくつかあります。せっかくなのでそれらがどう挿入されるかをみていきましょう。
HyperNetworks

HyperNetworksでは、Attention層のto_k, to_vへの入力を変換するモジュールを挿入します。入力形状ごとにモジュールを作成して、Attention層のLinear層の直前でモジュールを適用します。入力形状はチャンネル数で決まるので、320, 640, 1280の3つと、テキストエンコーダの出力(768 or 1024)に対応するもの、計4つのモジュールをk,vそれぞれで用意することになります。モジュールの中身は結構自由に決められるようで、全結合層と活性化関数を組み合わせて色々やってる人がいるようですね。
LoRA

上が線形層、下が畳み込み層
線形変換なので結局1層で表現できる
学習対象モデルの層を2つに分解してパラメータ数を削減する方法です。現在一番使われている手法ですね。最大の特徴はdown層とup層の行列積を元の重み行列に足すだけで、モデルにマージできることです(アダプターを追加せずに再現できる)。学習時はup層の重みを0で初期化します。これにより学習初期はLoRA適用前と出力が同じになり、学習が安定します。
cloneofsimo氏の最初の実装ではAttention層内のLinear層のみに適用されていましたが、kohya氏はそれをTransformer内のLinearと1×1Convまで拡張しました。その後ResNet部分の3×3Convまで拡張する方法が実装されたり、KohakuBlueLeaf氏がアダマール積(LoHA)だのクロネッカー積(Lokr)だのを使うやつを実装したりとよく分からんことになってますね。LoHAやLokrはアダプターという感じではないですけどね。
ControlNet
元論文の図があまりにもわかりやすいので自分で作るのはあきらめてそれを貼り付けます。
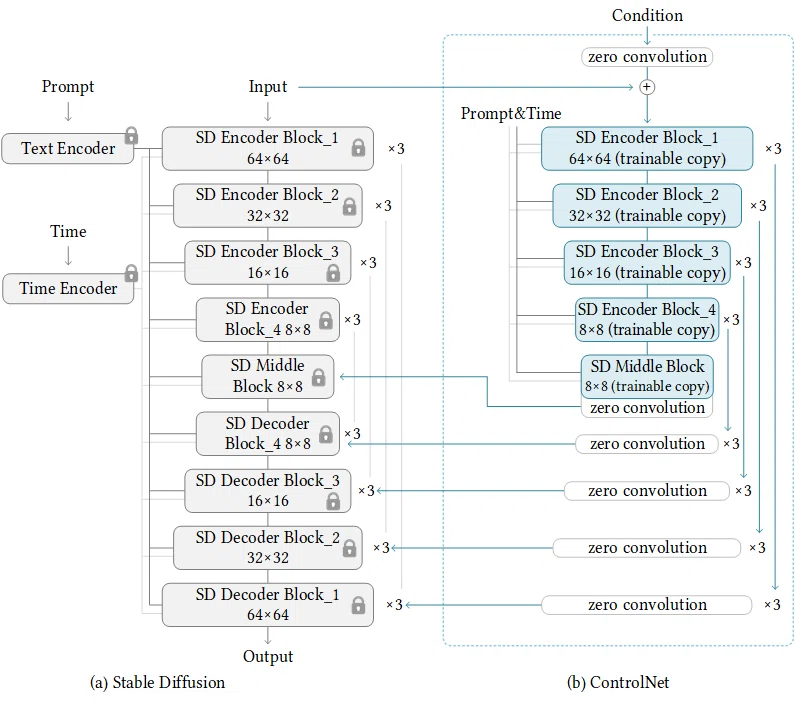
テキストの他にエッジや深度などの情報を画像として入力することで、生成画像をコントロールする方法です。ControlNetはIN+MIDをコピーしたものです。初期重み0の畳み込み層を経由して元のモデルのMID、OUTへの入力に足し算します。重み0にするというのはLoRAと同じような発想ですね。ただしこれにより学習の途中まで全くControlNetの効果が見られず、あるステップで突然効果が表れるようになる「突然の収束現象」というものが発生するようになります。途中まで全然学習できていないと思っていたら、突然うまく生成できるようになる、という感じになるので、学習時は設定等が悪いのかステップ数が足らないのか判断しづらく結構苦労します。
その他
以下実装ちゃんとみてなかったりするのでなんとなくの理解で書いてます。
T2I-Adapter:ControlNetと似てますが、元のモデル構造は使わず、画像を変換するモジュールを用意して、各INブロックに入力するみたいですね。ControlNetと違って計算時間が増えるのは1ステップ目のみになります。
GLIGEN:Self AttentionとCross Attentionの間にオリジナルのAttention層を追加することで、生成画像をコントロールする手法です。
(IA)^3:重み行列を行や列方向に定数倍することで微調整します。学習パラメータ数は行または列の数だけになるので非常に少ないです。
SVDiff:重み行列の特異値のみを微調整します。これも学習パラメータ数は重み行列の行または列の数だけになるので、非常に少ないです。
おわりに
AIアシスタントに書いてもらおうとしましたが、ちょっと試したら上限きてしまったので、来月まで待ってください。