
プロンプトを変えずに色んなキャラを生成する!(Prompt Free Generation)

今回の目的は、プロンプトを考えずに適当な画像を入力するだけで、それっぽい画像を生成するモデルを作ることです。そのために、画像分類モデルの出力をStable diffusionのUNetが理解できるように学習し、画像自体をプロンプトとして扱えるようにします。
※自分の記事があまりにも面白すぎて冗長になってしまったので、太字部分だけ読んでもだいたい分かるようにしています。
ばっくぐらうんど

WD14-Taggerの登場により、danbooru由来のデータであろうがなかろうが、danbooruタグに基づく学習ができるようになりました。そのため、多くのアニメスタイルの画像が、danbooruタグを列挙したプロンプトを入力して作成されています。しかしWD14-Taggerの出力を一旦テキストに置き換えて、再びテキストエンコーダーで埋め込みベクトルにするなんて馬鹿馬鹿しくないですか?せっかくAIが理解できる潜在表現を獲得したのに、それをそのまま使わないのはもったいないでしょう。今回の手法は、WD14-Taggerの最終層手前768次元ベクトルを直接Stable Diffusionのモデルに入力します。画像そのものをプロンプトにしてしまうようなイメージです。
めそっど

WD14-Taggerの最終層手前768次元ベクトルを利用します。このベクトルをテキスト埋め込みベクトルに挿入してしまえばいいじゃんというわけですが、いくらなんでもそのまま挿入するわけにはいきません。そもそもv2モデルではテキスト埋め込みベクトルは1024次元です。そのためWD14-Taggerの出力を変換する全結合層(PFGLinearと呼ぶことにする)を追加して、任意個の埋め込みベクトルを作ります。そしてそれを結合するだけです。後ろにそのまま結合するだけでいいの?と思うかもしれませんが、多分順番は関係ないです。
プロンプトとして、"illustration of *"といったものを全画像共通で使うことを想定しています。*は任意の単語です。プロンプトフリーといってもさすがに空文から画像を作るのは難しいので、学習データセット全体の特徴を表すようなプロンプトを数単語入れます。ただし全画像共通なので生成時はどんな画像を生成するときでもプロンプトを変える必要がありません。そのためプロンプトフリーになります。
生成時は、ほとんど同様ですが、学習時と違って、CFGを使うための無条件生成が必要です。バッチで処理するためには、トークン数を合わせる必要があるので、diffusersのpipelineでは無条件生成と条件付き生成のトークン数が同じになるようパディングされます。条件付き生成だけにPFGLinearの出力を結合すると数が合わなくなるので、無条件生成ではEOSをコピーして対応します。
りれいてっどわーく

画像を使ってAIが生成する画像をコントロールする方法は他にもいくつかあります。一番最初に思いつくのがimg2imgやinpaintでしょう。しかしこれはただのトレパクです。
次に分類器誘導というものがあります。
こちらの記事にあるClip image(またはVGG) guided Stable diffusionがそうです。SDとは別途画像分類器を用意して、生成画像の分類結果が指定した画像と同じような結果になるよう誘導してあげることで、指定した画像と似た画像を出力するようになります。しかしCLIPにしろVGGにしろアニメスタイルに特化したモデルではありません。勘のいいひとならここで、画像分類器としてWD14-Taggerを使えばいいのでは・・・?と思うでしょう。しかし残念ながらこの方法は試してないけど多分うまくいきません。何故なら拡散モデルでは、ノイズを含む画像を扱いますが、WD14-Taggerはノイズ込みの画像を正しく認識するよう学習されていないからです。分類器誘導に使う分類器は、学習の際にノイズを加えて、ノイズに対してロバストになる必要があります。上の記事でもVGG guided Stable diffusionでは、img2imgによる生成しかうまくいかないことが書かれています。その理由は上の記事で扱っているVGGはノイズが濃い状態に対応できるモデルではないからです。しかもこの手法、学習ステップごとに分類器の勾配計算を行う必要があり、実装も計算も難しいです。
最後に最近話題のControlNetというものもあります。
この手法ではエッジやポーズ等の情報を画像として入力することで、その構図そのままの画像を生成できるという非常に優れた手法です。しかし入力は位置情報を持った画像である必要があり、WD14-Taggerのような分類モデルの情報を取り込むのは難しいです。
とれいにんぐ
今回は上でリンクしたものではなく新しいWD14-Tagger-v2を使います。v2ではgeneralタグだけでなく、charactorタグにも対応していてこの手法にとっては非常にありがたいです。学習では、PFGLinearだけでなく、モデル全体を学習します。もちろんLoRAでできる可能性もあります。学習元モデルはwd14-epoch2からウマ娘の画像46000枚をたしか20エポック学習させたモデルです。最初はwd14から直接学習しようとしたのですが、それではあまりうまくいきませんでした。またPFGLinearだけを学習するという方法もありそうですが、今回はうまくいきませんでした(あまり調べられてないけど)。
学習はウマ娘の画像46000枚を学習率5e-6、バッチサイズ20で10エポックやりました。学習時間や必要VRAM量はほとんど変わりません。PFGLinearの重みサイズは5トークンで16MBほどになります。
全画像共通のプロンプトを、"illustration of umamusume"としました。思い付きベースなので、このプロンプトが正解とは思っていません。
りざると
はえ~~
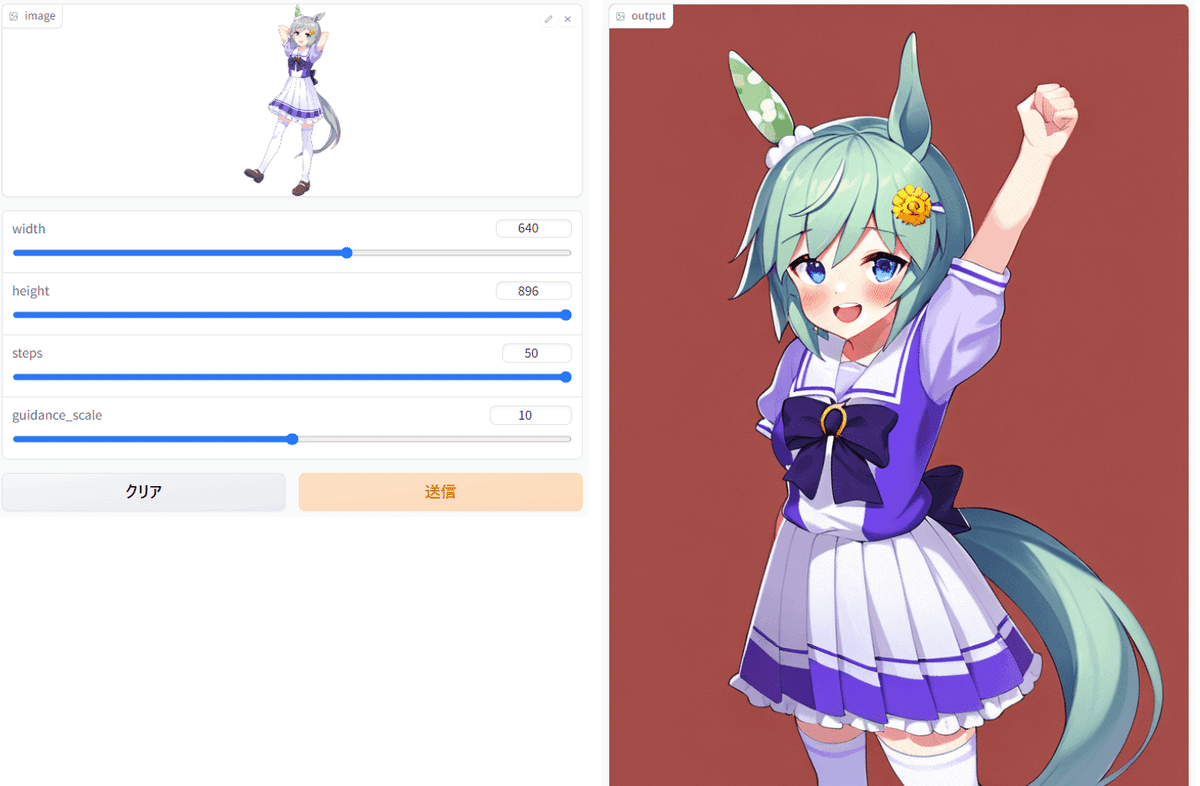
うまくいくかは画像やキャラによります。またguidance scaleの上下で結構変わるみたいです(というかそれしか変えるところがないww)。
こんくるーじょん
今回の手法で、同一モデル同一プロンプトでも画像があれば様々なキャラクターが生成できることが分かりました。私は今までキャラクター再現に結構注力を当ててきたのですが、新しいキャラクターを学習するたびにdanbooruでキャラクターを検索して、どんなタグが使われているかとか、WD14-Taggerの出力に目を凝らしたりと非常にめんどくさい思いをしてきました。その労力なしに生成できることに感動しています。
ふゅーちゃーわーく
PFGLinearは現状1層のLinearなので、線形(アフィン)変換です。Linear⇒relu⇒Linearなどとした方が良いかもしれません。
プロンプト不要といいつつ、別にプロンプトを設定できない手法ではないので、プロンプトにも頼ることでより多様な画像が生成ができるかもしれません。というかそうじゃないと何でtxt2imgモデルを使ってんの?っていう話になります・・・。
LoRAで学習を行う。相性はいいと思います。
WD14-Tagger以外のモデルで使う。たとえばBLIP等の出力を用いることで、より元画像の再現力が上がる可能性があります。また複数のモデルを同時に使うこともできます。
実装
今後の予定
手元に60万くらいのデータがあるので、これをもとにこの手法で学習しようと思っています。うまくいけば任意のアニメスタイル画像からそれっぽい画像が生成できるかもしれません。学習元はWD1-4(epoch2)かWD1-5(beta)かどっちがいいのかな~。また近いうちにwebuiに対応しようと思います。あんまり難しくなさそうです(他の機能への影響を気にしなければ^^)。
おまけ:こんなへんてこなこと思いついた理由
テキスト埋め込みベクトルは、別にCLIP由来のものじゃなくていいんじゃね?というのは以下の3つに発想の種があります。
テキストエンコーダを勝手に変えても割とうまくいく
この記事ではより強力なテキストエンコーダーを利用するものですが、同じCLIPとはいえ学習に使っていないテキストエンコーダーを利用してもうまくいくというのは不思議です。
トークン長の拡大や、最終層の手前の出力を使える
NovelAIの記事では、CLIPの最終層手前の出力を使うとむしろ精度が高くなる、とかトークン長の制限を拡大するために、テキストエンコーダの出力を複数個うまいこと繋げてしまうといった工夫点があげられました。UNetの構造的にトークン列は順不同(だよね?)かつ数も無制限なんでこんなへんてこなことができてしまいます。
sksみたいな謎の単語でも学習できてしまう
Dreamboothでは"sks"といったへんてこなトークンを利用します。このへんてこなトークンを1から学習させて、キャラクターの特徴をつかめるというのも不思議です。
このように、母なるUNetがすべてをやさしく包み込んでくれるので、テキスト埋め込みベクトルは非常に自由度が高いことが分かりました。じゃあもう好きなベクトルを入れちゃってもええやんというのが今回の発想です。