Stable Diffusion画像生成スクリプト(Diffusersベース、SD2.0、一括生成対応)

はじめに
多くの方はWeb UI他の画像生成環境をお使いかと思いますが、コマンドラインからの生成にも、もしかしたら需要があるかもしれませんので公開します。
Pythonで仮想環境を構築できるくらいの方を対象にしています。また細かいところは省略していますのでご容赦ください。
※12/16 (v9):img2img等でフォルダ指定したときファイル名をソートして処理するよう変更しました。目次から「スクリプト」に飛んでください。
※使用に当たっては自己責任でお願いいたします。
概要
Diffusersベースの推論(画像生成)スクリプト。
txt2img、img2img、inpaintingに対応。
対話モードに加え、ファイルからのプロンプト読み込み、連続生成に対応。
プロンプト1行あたりの生成枚数を指定可能。
全体の繰り返し回数を指定可能。
途中でモデルを切り替えることはできませんが、バッチファイルを組むことで対応できます。
xformersに対応し高速生成が可能。
速度はWeb UIと同程度のようです。
xformersにより省メモリ生成を行いますが、Web UIほど最適化していないため、512*512の画像生成でおおむね6GB程度のVRAMを使用します。
バッチ生成に対応。
プロンプトの拡張。
ネガティブプロンプト、重みづけ。
225トークンへの拡張。
Diffusersの各種samplerに対応。
Text Encoderの最後から二番目の層を用いることが可能。
Hypernetwork対応。
VAEを別途読み込み。
CLIP Guided Stable Diffusion、VGG16 Guided Stable Diffusion、Highres. fix、upscale対応。
Stable Diffusion v2.0対応(11/27)。
safetensors対応(12/5)。
環境整備
すでにDiffusersの環境のある方は次に進んでください。
※Windowsでxformersを使う場合、Python 3.10をお勧めします(3.8、3.9の場合、自前でxformersをビルドする必要があります)。
適当なディレクトリに仮想環境を構築します。
PyTorchとTorchvisionを入れる
Diffusersを入れる前にPyTorch 1.12.1とTorchvision 0.13.1を入れます。お使いのCUDAのバージョンにあわせたバージョンを入れてください。
※11/12現在、1.13.0を入れるとxformersがエラーになるようです。
以下はCUDA 11.6の例です。
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu11611.3ならこちらになります。
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113Diffusersと依存ライブラリを入れる
Diffusersのページに従いインストールします。私は0.10.0で動作確認しましたが、0.10.0には問題があるようですので0.10.2を使ってください(0.10.2で不具合がありましたらご連絡ください)。0.10.2を入れるには以下となります。
pip install diffusers[torch]==0.10.2次にスクリプトの実行に必要な以下のライブラリを入れます。
pip install transformers>=4.21.0
pip install ftfy
pip install opencv-python
pip install einops
pip install safetensors一部のcheckpointの読み込みで「ModuleNotFoundError: No module named 'pytorch_lightning'」というエラーが出る場合は、以下のようにpytorch_lightningを入れてください。
pip install pytorch_lightningxformersのインストール(オプション)
CrossAttentionを省メモリ化、高速化するためxformersを入れます。Linuxの場合、xformersのページに従ってインストールしてください。
WindowsでPython 3.10、GeForce 10XX(Pascal)以降のGPUの場合、Automatic1111氏のStable Diffusion web UIのWikiを参考に、以下のコマンドでインストールできます。
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whlそれ以外のPythonバージョン、GPUの場合、Wikiを参考に自前でビルドしてください(かなりの時間が掛かります)。
以上で環境整備は完了です。
スクリプト
以下をダウンロード、展開してください。二つのスクリプトが含まれていますので、同じフォルダに置いてください。過去のバージョンは記事の末尾に移しました。
更新情報
※12/16 (v9):img2imgやマスク等でフォルダを指定したとき、ファイル名でソートしてから画像を処理するように変更しました。なおソート順は文字列順となりますので(1.jpg→2.jpg→10.jpgではなく1.jpg→10.jpg→2.jpgの順)、頭を0埋めするなどしてご対応ください(01.jpg→02.jpg→10.jpg)。
※12/15 (v8):マスク指定時のimg2imgでエラーとなる不具合に暫定的に対応しました。
一部条件下でPillowで読んだ画像からファイル名が取得できない場合があるようでした。そのような条件では現状use_original_file_nameオプションでエラーとなりますが、次の近日中の更新で対応予定です。
基本的な使い方
対話モードでの画像生成
以下のように入力してください(実際には1行で入力します)。
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先>
--xformers --fp16 --interactive--ckptオプションにモデル(Stable Diffusionのcheckpointファイル、またはDiffusersのモデルフォルダ)、--outdirオプションに画像の出力先フォルダを指定します。
--xformersオプションでxformersの使用を指定します(xformersを使わない場合は外してください)。--fp16オプションでfp16(単精度)での推論を行います。--interactiveオプションで対話モードを指定しています。
Stable Diffusion 2.0(またはそこからの追加学習モデル)を使う場合は--v2オプションを追加してください。768-v-ema.ckptを使う場合はさらに--v_parameterizationを追加してください。(詳細はその他のオプションをご覧ください。)
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先>
--xformers --fp16 --interactive --v2 --v_parameterization「Type prompt:」と表示されたらプロンプトを入力してください。
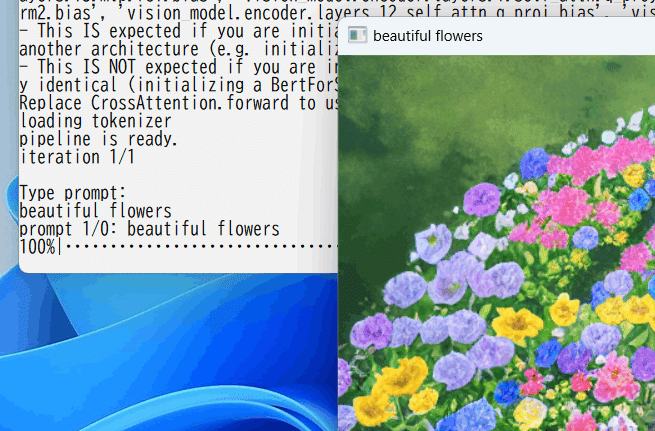
※画像が表示されずエラーになる場合、headless(画面表示機能なし)のOpenCVがインストールされているかもしれません。「pip install opencv-python」として通常のOpenCVを入れてください。または--no_previewオプションで画像表示を止めてください。
画像ウィンドウを選択しキーを押すとウィンドウが閉じ、次のプロンプトが入力できます。プロンプトでCtrl+Z、エンターの順に打鍵するとスクリプトを閉じます。
単一のプロンプトで画像を一括生成
以下のように入力します。
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先>
--xformers --fp16 --images_per_prompt <生成枚数> --prompt "<プロンプト>"--images_per_promptオプションで、プロンプト1件当たりの生成枚数を指定します。
--promptオプションでプロンプトを指定します。スペースを含む場合はダブルクォーテーションで囲んでください。
--batch_sizeオプションでバッチサイズを指定できます(後述)。
ファイルからプロンプトを読み込み一括生成
以下のように入力します。
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先>
--xformers --fp16 --from_file <プロンプトファイル名>--from_fileオプションで、プロンプトが記述されたファイルを指定します。1行1プロンプトで記述してください。
--images_per_promptオプションを指定して1行あたり生成枚数を指定できます。
ネガティブプロンプト、重みづけの使用
プロンプトで「--n」を書くと、以降がネガティブプロンプトとなります。--nの前後にスペースを入れてください。
またAUTOMATIC1111氏のWeb UIと同様の () や [] 、(xxx:1.3) などによる重みづけが可能です(実装はDiffusersのLong Prompt Weighting Stable Diffusionからコピーしたものです)。
コマンドラインからのプロンプト指定、ファイルからのプロンプト読み込みでも同様に指定できます。

主なオプション
コマンドラインから指定してください。
生成画像サイズの指定
--Wオプションで幅、--Hオプションで高さを指定します。
samplerの指定
--samplerオプションを使います。Diffusersで提供されているddim、pndm、dpmsolver、dpmsolver+++、lms、euler、euler_a、が指定可能です(後ろの三つはk_lms、k_euler、k_euler_aでも指定できます)。
11/18現在dpmsolver/dpmsolver+++はDiffusersのリリースに含まれないため、ソースコードを直接コピーしてスクリプトに埋め込んであります。
ステップ数の指定
--stepsオプションを用います。
guidance scaleの指定
--scaleオプションを使います。
バッチサイズの指定
--batch_sizeオプションで同時生成する枚数を指定します。増やすとその分使用メモリ量が増えますが、生成が高速になります。メモリの許す範囲で増やしてください。
使用するText Encoderの層指定
--clip_skipオプションで最後の層を使うか、他の層を使うか指定します。clip_skip指定なし、または1で最後の層、2で最後から二番目の層を使います。
モデルの元々の学習状態と同じ指定とするのが通常ですが、変えてもそれなりに動くようです。
最大トークン長の指定
--max_embeddings_multiplesオプションで通常は75トークンの長さ制限を拡張できます。何倍にするかを指定します。未指定時または1で通常の75トークン、3なら3倍(225トークン)となります。
clip_skipと同様、モデルの元々の学習状態と同じ指定とするのが通常ですが、変えてもそれなりに動くようです。
オプション指定例
次は同一プロンプトで64枚をバッチサイズ4で一括生成する例です。
python gen_img_diffusers.py --ckpt model.ckpt --outdir outputs
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a
--steps 80 --batch_size 4 --images_per_prompt 64
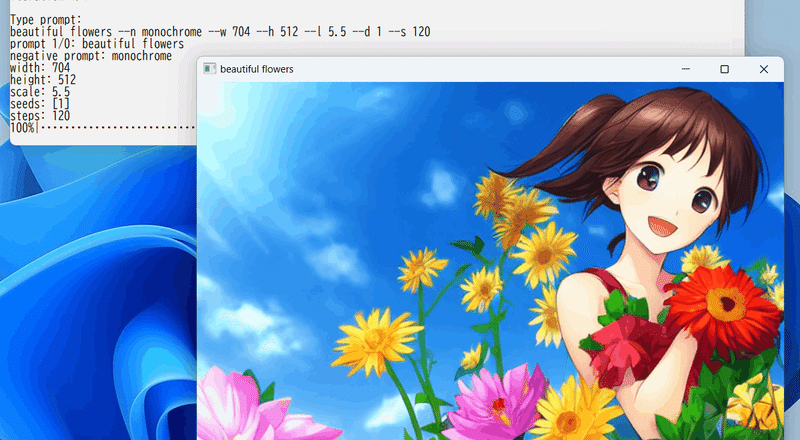
--prompt "beautiful flowers --n monochrome"次はファイルに書かれたプロンプトを、それぞれ10枚ずつ、バッチサイズ4で一括生成する例です。
python gen_img_diffusers.py --ckpt model.ckpt --outdir outputs
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a
--steps 80 --batch_size 4 --images_per_prompt 10
--from_file prompts.txtプロンプトのオプション
プロンプト内で、--nのように「ハイフンふたつ+アルファベット」でプロンプトから各種パラメータの指定が可能です。対話モード、コマンドライン、ファイル、いずれからプロンプトを指定する場合でも有効です。
--n ネガティブプロンプト
前述の通りです。
--d seed指定
乱数種を指定します。images_per_promptを指定している場合は「--d 1,2,3,4」のようにカンマ区切りで複数指定してください。
--w 画像幅指定
--h 画像高さ指定
--s ステップ数指定
--l guidance scale指定
--t img2imgのstrength(後述)指定
コマンドラインで指定したこれらの値を、このプロンプトだけ変更します。
※これらのオプションを指定すると、バッチサイズよりも小さいサイズでバッチが実行される場合があります(これらの値が異なると一括生成できないため)。
(あまり気にしなくて大丈夫ですが、ファイルからプロンプトを読み込み生成する場合は、これらの値が同一のプロンプトを並べておくとよいです。)
--c CLIP text(後述)の指定
CLIP Guided Stable Diffusionで使用するテキストです(後述)。
img2img
--image_pathオプションでimg2imgに利用する画像を指定してください。--strengthオプションでどの程度画像を変化させるかを指定します。
たとえば以下のようなコマンドラインになります。
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
--outdir outputs --xformers --fp16 --scale 12.5 --sampler k_euler --steps 80
--image_path template.png --strength 0.8
--prompt "1girl, cowboy shot, brown hair, pony tail, brown eyes,
sailor school uniform, outdoors
--n lowres, bad anatomy, bad hands, error, missing fingers, cropped,
worst quality, low quality, normal quality, jpeg artifacts, (blurry),
hair ornament, glasses"
--batch_size 8 --images_per_prompt 32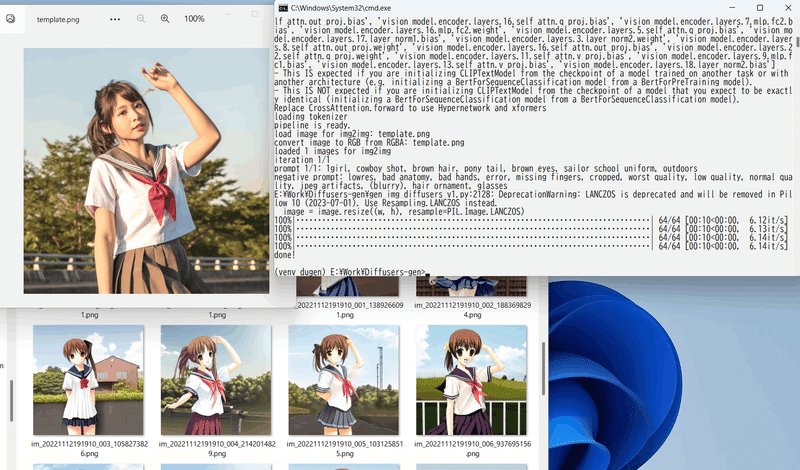
image_pathオプションにフォルダを指定すると、そのフォルダの画像を順次読み込みます。生成される枚数はプロンプト数になりますので、images_per_promptオプションを指定してimg2imgする画像の枚数とプロンプト数を合わせてください。
ファイルはファイル名でソートして読み込みます。なおソート順は文字列順となりますので(1.jpg→2.jpg→10.jpgではなく1.jpg→10.jpg→2.jpgの順)、頭を0埋めするなどしてご対応ください(01.jpg→02.jpg→10.jpg)。
同時に--sequential_file_nameオプションを指定すると、生成されるファイル名が im_000001.png からの連番になります。
以下のようなコマンドになります。生成画像に一貫性を持たせる場合、プロンプトに--dを指定してseedを指定すると良いでしょう。
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
--outdir out_frames --xformers --fp16 --scale 25 --sampler k_euler --steps 80
--image_path i2i_frames --strength 0.2
--prompt "1girl, upper body, brown hair, short hair, brown eyes,
cherry blossoms printed white parker, in room, happy
--n lowres, bad anatomy, bad hands, error, missing fingers,
cropped, worst quality, low quality, normal quality,
jpeg artifacts, (blurry), hair ornament, glasses --d 42"
--batch_size 4 --images_per_prompt 100 --sequential_file_name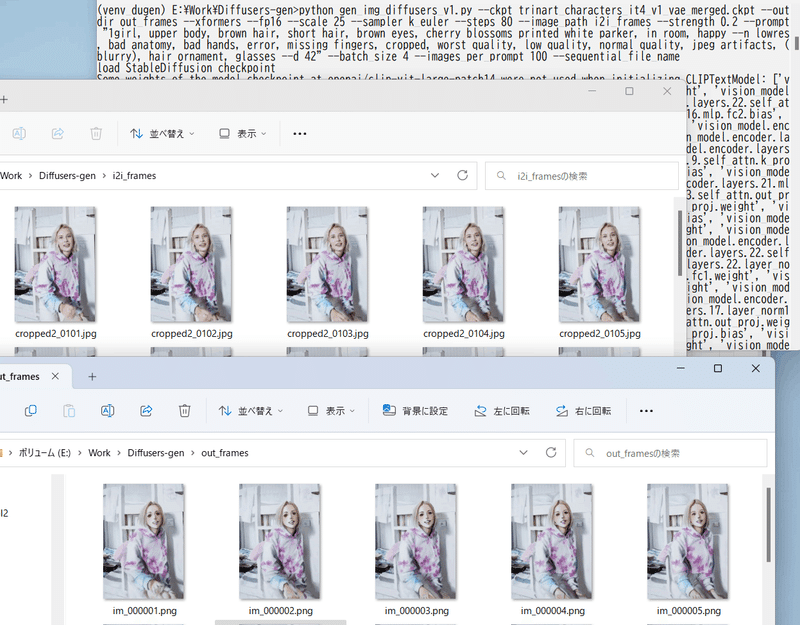
img2imgを利用したupscale
img2img時にコマンドラインオプションの--Wと--Hで生成画像サイズを指定すると、元画像をそのサイズにリサイズしてからimg2imgを行います。
またimg2imgの元画像がこのスクリプトで生成した画像の場合、プロンプトを省略すると、元画像のメタデータからプロンプトを取得しそのまま用います。これによりHighres. fixの2nd stageの動作だけを行うことができます。
inpainting
画像およびマスク画像を指定してinpaintingできます(inpaintingモデルには対応しておらず、単にマスク領域を対象にimg2imgするだけです)。
--mask_imageでマスク画像を指定してください。他のオプションはimg2imgと同様です。
マスク画像はグレースケール画像で、白の部分がinpaintingされます。境界をグラデーションしておくとなんとなく滑らかになりますのでお勧めです。
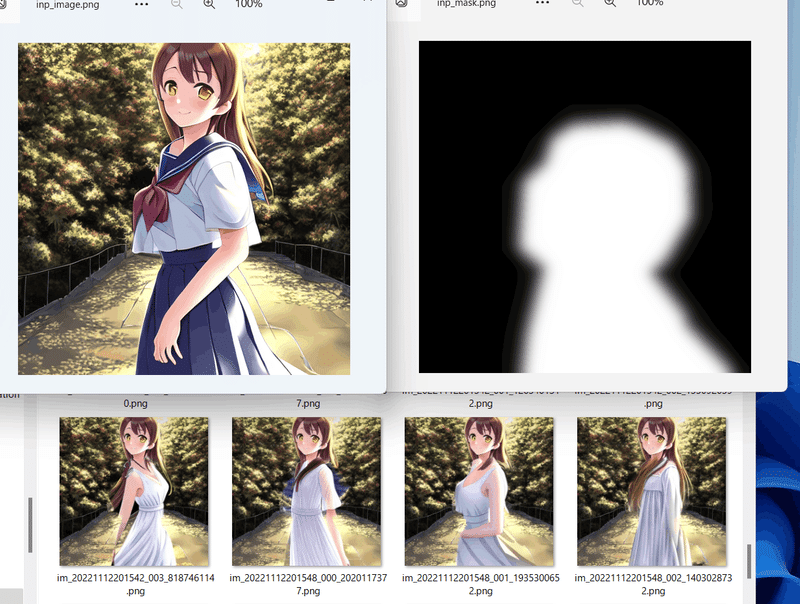
マスク画像としてフォルダをしてするとマスクを順次適用します(未テストです)。
CLIP Guided Stable Diffusion
DiffusersのCommunity Exaplesのこちらのcustom pipelineからソースをコピー、変更したものです。通常のプロンプトによる生成指定に加えて、追加でより大規模のCLIPでプロンプトのテキストの特徴量を取得し、生成中の画像の特徴量がそのテキストの特徴量に近づくよう、生成される画像をコントロールします(私のざっくりとした理解です)。
大きめのCLIPを使いますのでVRAM使用量はかなり増加し(VRAM 8GBでは512*512でも厳しいかもしれません)、生成時間も掛かります。
なお選択できるサンプラーはDDIM、PNDM、LMSのみとなります。
--clip_guidance_scaleオプションにどの程度、CLIPの特徴量を反映するかを数値で指定します。先のサンプルでは100になっていますので、そのあたりから始めて増減すると良いようです。
デフォルトではプロンプトの先頭75トークン(重みづけの特殊文字を除く)がCLIPに渡されます。プロンプトの--cオプションで、通常のプロンプトではなく、CLIPに渡すテキストを別に指定できます(たとえばCLIPはDreamBoothのidentifier(識別子)や「1girl」などのモデル特有の単語は認識できないと思われますので、それらを省いたテキストが良いと思われます)。

プロンプトは先のサンプルに記述されているもの

fantasy book cover, full moon, fantasy forest landscape, golden vector elements, fantasy magic, dark light night, intricate, elegant, sharp focus, illustration, highly detailed, digital painting, concept art, matte, art by WLOP and Artgerm and Albert Bierstadt, masterpiece
コマンドラインの例です。
python gen_img_diffusers.py --ckpt v1-5-pruned-emaonly.ckpt --n_iter 1
--scale 2.5 --W 512 --H 512 --batch_size 1 --outdir ../txt2img --steps 80
--sampler ddim --fp16 --opt_channels_last --xformers --images_per_prompt 1
--interactive --clip_guidance_scale 100CLIP Image Guided Stable Diffusion
また、独自に、テキストではなくCLIPに別の画像を渡し、その特徴量に近づくよう生成をコントロールする機能を追加しました。--clip_image_guidance_scaleオプションで適用量の数値を、--guide_image_pathオプションでguideに使用する画像(ファイルまたはフォルダ)を指定してください。
コマンドラインの例です。
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
--n_iter 1 --scale 7.5 --W 512 --H 512 --batch_size 1 --outdir ../txt2img
--steps 80 --sampler ddim --fp16 --opt_channels_last --xformers
--images_per_prompt 1 --interactive --clip_image_guidance_scale 100
--guide_image_path YUKA160113420I9A4104_TP_V.jpg
1girl, upper body, [[twin tail]], [[[from side, from below]]], at tokyo night street, night scene background, [[cyberpunk, colorful neon]], illuminations, starry sky, beautiful scene, perfect perspective, (happy), blush, ultra detailed CG, 8k wallpaper, November, absurdres, best quality, emerald, portrait taken by Canon EOS --n lowres, bad anatomy, bad hands, error, missing fingers, cropped, worst quality, low quality, normal quality, jpeg artifacts, blurry, no person, bad perspective

プロンプト、seed等同じ
guideに使用した画像はぱくたそさんのこちらです。
VGG16 Guided Stable Diffusion
指定した画像に近づくように画像生成する機能です。通常のプロンプトによる生成指定に加えて、追加でVGG16の特徴量を取得し、生成中の画像が指定したガイド画像に近づくよう、生成される画像をコントロールします。
img2imgでの使用をお勧めします(通常の生成では画像がぼやけた感じになります)。
CLIP Guided Stable Diffusionの仕組みを流用した独自の機能です。またアイデアはVGGを利用したスタイル変換から拝借しています。
なお選択できるサンプラーはDDIM、PNDM、LMSのみとなります。
--vgg16_guidance_scaleオプションにどの程度、VGG16特徴量を反映するかを数値で指定します。試した感じでは100くらいから始めて増減すると良いようです。--guide_image_pathオプションでguideに使用する画像(ファイルまたはフォルダ)を指定してください。
複数枚の画像を一括でimg2img変換し、元画像をガイド画像とする場合、--guide_image_pathと--image_pathに同じ値を指定すればOKです。
コマンドラインの例です。
python gen_img_diffusers.py --ckpt wd-v1-3-full-pruned-half.ckpt
--n_iter 1 --scale 5.5 --steps 60 --outdir ../txt2img
--xformers --sampler ddim --fp16 --W 512 --H 704
--batch_size 1 --images_per_prompt 1
--prompt "picturesque, 1girl, solo, anime face, skirt, beautiful face
--n lowres, bad anatomy, bad hands, error, missing fingers,
cropped, worst quality, low quality, normal quality,
jpeg artifacts, blurry, 3d, bad face, monochrome --d 1"
--strength 0.8 --image_path ..\src_image
--vgg16_guidance_scale 100 --guide_image_path ..\src_image --vgg16_guidance_layerで特徴量取得に使用するVGG16のレイヤー番号を指定できます(デフォルトは20でconv4-2のReLUです)。上の層ほど画風を表現し、下の層ほどコンテンツを表現するといわれています。
使用例
img2imgを元画像をガイド画像とし、strength 0.5/0.8、scale 100、250とした場合の生成例です(最下部はvgg16_guidance_layerを30とした例)。

以下、参考までにtorchvisionのVGG16の構造です。ReLUの層を指定すると良いと思われます。Conv2dを指定する場合はscaleを下げたほうが良いでしょう。

Highres. fix
AUTOMATIC1111氏のWeb UIにある機能の類似機能です(独自実装のためもしかしたらいろいろ異なるかもしれません)。最初に小さめの画像を生成し、その画像を元にimg2imgすることで、画像全体の破綻を防ぎつつ大きな解像度の画像を生成します。
--highres_fix_scaleオプションで、最初に生成する画像のサイズを、倍率で指定します。最終的な生成画像サイズが1024*1024の場合、このオプションで0.5を指定すると、512*512でまず画像を生成します。
--highres_fix_stepsオプションで最初の生成時のステップ数を指定します。
--highres_fix_save_1stオプションを指定すると、最終的な生成画像だけでなく、最初に生成した画像についても保存します。
第二段階のimg2imgでは、--strengthオプションに指定した値が使われますので、そちらも合わせて変更してください。


コマンドラインの例です。
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
--n_iter 1 --scale 7.5 --W 1024 --H 1024 --batch_size 1 --outdir ../txt2img
--steps 80 --sampler ddim --fp16 --opt_channels_last --xformers
--images_per_prompt 1 --interactive
--highres_fix_scale 0.5 --highres_fix_steps 28 --strength 0.7Hypernetworkの利用
Hypernetworkモジュールを定義することで独自に定義したHypernetworkを適用できます。
hypernetwork_moduleオプションでモジュール(ソースファイルから.pyを除いたもの)を、hypernetwork_weightsオプションでモデルの重みファイル(checkpoint)を、hypernetwork_mulで適用率を指定します。
Hypernetworkの自作については次回以降の記事にまとめますが、NovelAI互換のHypernetworkモジュールが以下になります(Web UIの「1,2,1」、LayerNormなし、activationなしに相当するはずです)。
たとえばこちらで提供されているZelda Diffusionを使用すると以下になります。
python gen_img_diffusers.py --ckpt v1-5-pruned-emaonly.ckpt --outdir outputs
--xformers --fp16 --scale 7.5 --sampler k_euler_a --steps 50
--hypernetwork_module hypernetwork_nai
--hypernetwork_weights zeldaBOTW.pt --hypernetwork_mul 0.8 --interactive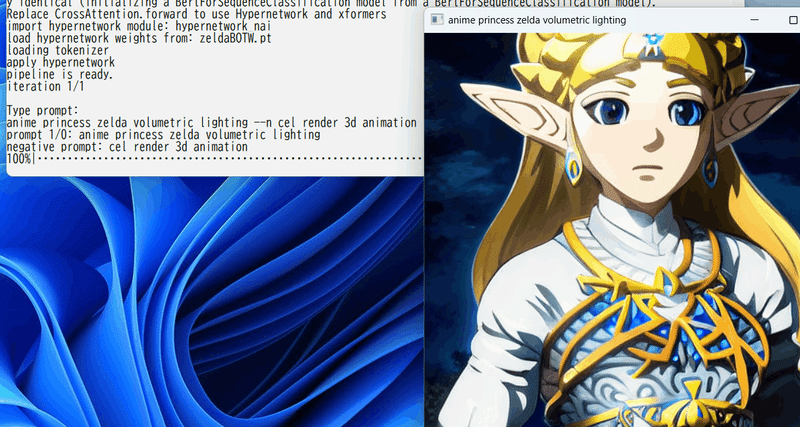
スクリプトを読める方でしたらhypernetwork_nai.pyを参考に任意にレイヤーや適応箇所を定義し、先日のfine_tune.pyで学習できます。
超強力なHypernetworkの例を置いておきます。
その他のオプション
--v2 / --v_parameterization
Stable Diffusion 2.0のモデルで推論します。Hugging Faceのstable-diffusion-2-baseを使う場合は--v2オプションを、stable-diffusion-2または768-v-ema.ckptを使う場合は--v2と--v_parameterizationの両方のオプションを指定してください。
--v_parameterizationの指定を誤ると生成画像がおかしくなりますのでわかると思います。
stable-diffusion-2-base
stable-diffusion-2(baseでないほう)
--no_preview
対話モードで画像表示を行いません。
--n_iter <繰り返し回数>
プロンプト全体をさらに繰り返す回数を指定します。たとえばファイルから読み込む場合、もう一度先頭から同じ処理を行います。
--seed <乱数種>
プロンプトでseedを指定しないとデフォルトではランダムなseedで生成されますが、その一連のseedを決めるためのseedを指定できます。プロンプト全体を同一乱数で複数回生成したい場合にご利用ください。
--diffusers_xformers
スクリプト内のxformers代替機能ではなく、Diffusersのxformers機能を利用します。速度はほぼ同一のようです。Hypernetworkは利用できません。
--opt_channels_last
PyTorchのモデルにmemory_format=torch.channels_lastを指定します。場合によっては高速化されるようです。
--vae <VAEのcheckpointまたはフォルダ>
VAEを別途読み込み、入れ替えます。StableDiffusionのVAEのみのcheckpoint、StableDiffusionのモデルのcheckpoint(checkpoint内のVAEを読み込みます)、DiffusersのVAE(Hugging FaceのモデルIDまたはローカルのモデルフォルダ)、SD1.5形式のVAE(拡張子.bin)に対応しています。
--bf16
bf16形式で推論を行います。bf16で学習したモデルをfp16で推論すると生成画像が真っ黒になることがありますが、このオプションで避けられるようです。
※恐らく指数部が桁あふれしてNaNになっているのではないかと思います。
--use_original_file_name
img2imgで元ファイル名と同じファイル名で出力します(拡張子は.pngとなります)。動画の一連の画像をimg2imgする場合などにお使いください。
--iter_same_seed
各繰り返しですべてのプロンプトに同一のseedを使います(seed自体はランダム)。すこしずつ内容を変えたプロンプトをファイルに用意し、それぞれに同一のseedを適用しつつ、複数回生成してプロンプトを比較する場合などにご利用ください。
おわりに
自前で使っている生成スクリプトの機能の多くをDiffusersベースに書き直したものです。ご利用いただければ幸いです。
過去のバージョン
過去の更新情報
※12/10 (v7):DiffUsers 0.10.2が必要となります(0.10.0以降で動きますが0.10.0には問題があるようですので0.10.2を使ってください)。仮想環境内で「pip install -U diffusers[torch]==0.10.2」として更新してください。Diffusers 0.10に対応しました(すべてのsamplerがv2に対応しました。またdpm_2、dpm_2_a、heun、dpmsingleのsamplerが追加されました。またDiffusersモデルのsafetensors形式に対応しました。img2imgで元のファイル名で出力する--use_original_file_nameオプション、各繰り返し内ですべてのプロンプトに同一のseedを使う--iter_same_seedオプションが追加されました。
※12/5 (v6):スクリプトが2つに分かれたため.zip形式としました。展開してください。.safetensors形式に対応しました(拡張子で自動判定します)。「pip install safetensors」としてsafetensorsをインストールしてください。vaeオプションがDiffusersの単体のVAEのロードに対応していなかったのを修正しました。img2imgのmaskが動かなくなっていたのを修正しました。
※12/1 (v5):VGG16 Guided Stable Diffusionを追加しました。「VGG16 Guided Stable Diffusion」をご覧ください。schedulerの引数にclip_sample=Trueを追加しました。プロンプトのオプションが大文字小文字どちらでも指定可能になりました。
※11/27 (v4):DiffUsersの0.9.0が必要です。仮想環境で「pip install -U diffusers[torch]==0.9.0」としてアップグレードしてください。
Stable Diffusion v2.0に対応しました。--v2オプションを追加してください。stable-diffusion-v2-baseではなく768-v-ema.ckptまたはstable-diffusion-2を使う場合は--v_parameterizationも合わせて追加してください。詳しくはその他のオプションをご覧ください。
対話モードで画像表示しないオプション--no_previewを追加しました。
※11/18 (v3):samplerとしてdpmsolver、dpmsolver+++が使えるようになりました。VAEのみの追加読み込みに対応しました(--vaeオプション)。upscaleに対応しました(img2imgをご覧ください)。bf16での推論に対応しました(--bf16オプション、bf16で学習したモデルで生成画像が真っ黒になることが避けられます)。--hypernetwork_mulが効かない不具合を修正しました。
この記事が気に入ったらサポートをしてみませんか?