LECOがやっていることを解説する

LECOとはモデルから特定の概念を取り除いたり、付与することができるLoRA学習法です。特徴は教師画像が必要ないことで、欠点はモデルがすでに覚えている概念しか扱えないことです。
実装
元論文
ESD:概念を除去する
"Elon Musk"という概念を除去することを考えます。ESDでは"Elon Musk"というプロンプトで生成した結果を反転させるように学習します。ただ反転させるといっても、0を中心に反転させたら色が逆になるだけで意味がありません。そこで空文による生成結果を基準にして反転させます。

このとき反転させたベクトルの大きさをguidance_scaleという数値で調整することができます。guidance_scaleは大きくすると除去効果も大きくなりますが、生成画像が崩壊しやすくなるっぽいです。基本的には1にするのが無難そうですね。
学習後のモデルは、プロンプトに"Elon Musk"と入力すると、逆に"Elon Musk"とは離れた画像を生成するようになります。
ESDの応用:概念を付与する
ESDの応用として、プロンプトに別のプロンプトの意味を付与するような学習ができます。たとえば"Elon Musk"に"API制限をしない"という概念を付与したいときは以下のように学習します。
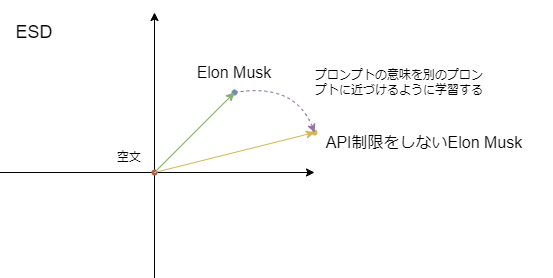
これもguidance_scaleを設定できますが、付与するときはとくに1より大きい設定をすると生成画像に悪影響を与えやすいです。ちなみに付与と除去はguidance_scaleのプラスマイナスを変えるのと同じ意味になります。
ESDのLoRAへの拡張
元のESDでは学習時に学習前のモデルと学習後のモデルを持っておかなければいけないため、VRAM使用量が大きいです。LECOではLoRAの学習に置き換えることで、学習前のモデルとLoRAのみを持っておけばよくなり8GBのクソザコGPUでも学習できるらしいです。
(ちょっと発展的話題)
Stable-Diffusionのモデルには画像そのものを解析するSelf-Attention層と、画像とプロンプトとの関係を解析するCross-Attention層があります。ESDの論文ではえっっっtな画像などプロンプトを明示せずとも除去したい場合はSelf-Attention層を、芸術家の名前等プロンプトを明示するときに除去したい場合はCross-Attention層を学習させるとよいと書いてありますが、LECOでは特に区別なく両方とも学習します。
学習データの自動生成

Stable-Diffusionの学習ではほとんどの手法で学習データが必要ですが、LECOでは必要ありません。といっても使っていないわけではなくて、学習ステップごとに自動生成しています。ただ学習時に必要なのはノイズを中途半端に除去した画像だけなので、最後までノイズ除去しません。LECOの学習に時間がかかるのはこの部分が原因になります。
ネガティブプロンプトで生成した画像を学習させるネガティブTIに近いです。ただしLECOではネガティブTIと違って学習中に画像を生成していくので、より学習後のモデルが生成する画像に近い画像で学習することができます。

私は自分の実装でこの部分を改良してみました。元の実装では1ステップごとに生成を行いますが、私の実装ではノイズ除去ループ中の途中結果も学習に利用することで、数ステップに一回の生成で学習できるようにしています。精度は下がりそうですが学習時間を結構短縮できます。
(発展的話題)
元の実装では(0,sampling steps)からランダムに1つ選んでそのstep分ノイズ除去ループを回します。計算時間の期待値は全ステップの生成時間比で$${\frac{1}{2}}$$であり、$${k}$$ステップ分の学習で計算量は$${\frac{1}{2}k}$$になります。私の実装では(0,step)からランダムにk個選んで最大値までのループを行ってk個分の結果を取り出します。このとき最大値の期待値は$${\frac{k}{k+1}}$$らしいです。kステップ分の学習が最大値までのノイズ除去ループだけで済むので、計算量は同様に$${\frac{k}{k+1}}$$であり、計算量の短縮割合は$${\frac{2}{k+1}}$$になります。LECOでは学習時間の大部分が生成の計算になっているので、結構な短縮ができるはずです。
上記でtimestepをランダムに選んでいますが、sampling stepsを少ない値にした場合、学習対象のtimestepがとびとびになってしまいます。そこで私の実装では(0,1000/sampling steps)からランダムな値を選んでtimestepに足すことで、全timestepで学習できるようにしていますが、この辺の処理にあんまり自信がありません。
cfg_scale=1で生成できるようにする?

Stable-Diffusionでは生成時にプロンプトによる生成とネガティブプロンプトによる生成の2つを計算する必要があります。そこで私はLECOを使ってプロンプトによる生成だけで実際の生成で使われるベクトルを出力できるようなLoRAを作ってみました。ネガティブプロンプト側の計算を省略することで、計算量を半分にすることができます。まあ高品質な画像は作れなさそうなんですが、それなりの画像は作れるっぽいです。
LECOのメリット
手法から分かる通り、元のモデルが覚えている(プロンプトを指定すればその通り生成できる)概念のみを扱えます。じゃあLECOなんか作らずプロンプトやネガティブプロンプトを使えばいいじゃないかと言われると結構多くの場合そうだと思います。例えば元論文ではえっっな画像を生成できないようにすれば安心して公開できるねと主張していますが、この記事を見ている君たちはむしろそんなのやめてくれよ・・・って感じだと思います。それではメリットを考えていきましょう。
教師画像が必要ない
まあメリットといえばメリットなんですが、教師画像が必要ない(自動生成した画像を使う)というのはつまりそのモデルが元々持っている概念しか学習できないという意味なのでプロンプトを変えればいいじゃんに対する反論にはなりません。
プロンプトを省略できる
プロンプトに色々な概念を詰め込むことで、プロンプトを省略することができそうです。また他のプロンプトに影響を及ぼしてしまう色のプロンプトを省略することで、色移りを防ぐみたいな効果もあるのかな?
また上で紹介したcfg_scale=1で生成する方法では、ネガティブプロンプトが使えないので概念除去LECOは非常に役立ちます。
LoRAのweightで調整できる
LoRAのweightで学習させた概念の強弱を変えることができます。プロンプトの()[]とかでもできそうですが、LoRAの方がより直感的に調整できそう。またマイナス適用することで今までできなかったことができそうです。
LECOの発展(妄想)
別のモデルの概念を移植する
学習対象(きれいなElon Musk等)のノイズ予測を同一モデルではなく別のモデルで行うことで、別のモデルが持つ概念を移植することができるのではなどと考えました。SD1系とSD2系はVAEやスケジューラが同一なので、両モデル間の移植もできるんじゃないかと思っていますが、どうなのか分かりません。試したいけど何から何を移植すればいいか何も思いつきません。
Textual Inversionの学習につかう
単にLoRAではなくTIの学習で同じ手法を使うというだけですが、ネガティブTI等がより簡単で精度よく作れそうな気がします。ただ私はTIの実装が全く分かりませんのでする気ないです(というかembeddingの使い方すらわからない^^)。
DreamBoothの学習につかう
突然ですが、1girlの意味を1girlに近づけようとするLECOを考えてみます。このLECO自体は全く効果がないものなんですが、実はDreamBoothでは近いことをやっています。DreamBoothでは学習前モデルで1girlなどの一般的ワードによって生成した正則化画像を学習させることで、1girlの意味が変わらないよう制限しています。LECOの方法で学習後モデルの1girlによる生成を学習前モデルに近づけるよう学習させれば、正則化画像不要のDreamBoothができるっちゃできます。まあでもめんどくさいし学習時間も長くなりそうだし微妙かも。
おわりに
Elon Muskのことは別に嫌いではないです。好きでもないけど。