Stable Diffusion学習のVRAM使用量を調査する

調査するぞ調査すると徹底的に調査するぞ!!!
基本設定
調査に使う学習コードは疑似的に作成したものになります。画像データ等は使わず、ランダムなテンソルをネットワークに入力します。VAEは使いません。共通設定を以下のようにします。
モデル:Stable-Diffusion-v1.5
バッチサイズ:[1, 2, 3, 4, 6, 8, 10, 12, 14, 16]
画像サイズ:768×768
xformers:あり
optimizer:AdamW
AMP:torch.bfloat16
Pytorch==2.0.1, diffusers==0.19.3
テキストエンコーダは学習しない
GPUはぺぱすぺのA100
これを基本設定として、ある項目を変えて比較するというのを繰り返します。VRAM使用量は20ステップのループの各ステップごとにsubprocessでnvidia-smiを呼び出し、最大値を記録します。
詳細は以下を確認してください。
https://github.com/laksjdjf/sd-trainer/blob/main/vram_test.py
結果(ファインチューニング編)
グラフはVRAM使用量が縦軸で単位はGiB、バッチサイズが横軸です。
基本設定そのまま

一次関数的に伸びていますね。バッチサイズ1から2であまり変わらないのはよく分かりませんが、バッチサイズ1だと最適化の効果が小さいのかもしれません。
VAEとテキストエンコーダのオフロード
VAEとテキストエンコーダはデータ拡張等を行わない場合、事前計算が可能なので、CPUに持たせておくことができます、その場合モデルサイズ分VRAM使用量が減ります。
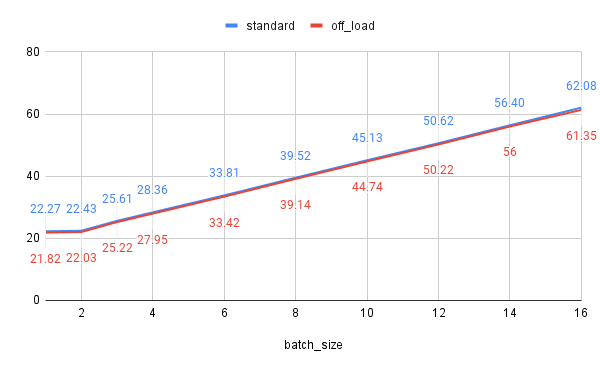
bfloat16の場合二つのモデル合わせて約0.4GBなので、ほとんどあってそうですが、なぜかバッチサイズ16のときはちょっと違いますね。ちょびっとしか変わらないですが、SDXLではもうちょっと効果あります。
AdamW8bit
AdamWは過去の勾配の指数平均と、二乗勾配の指数平均の二つをキャッシュします。つまりモデルサイズの2倍分VRAM使用量があがります。それを8bitにするのがAdamW8bitです。
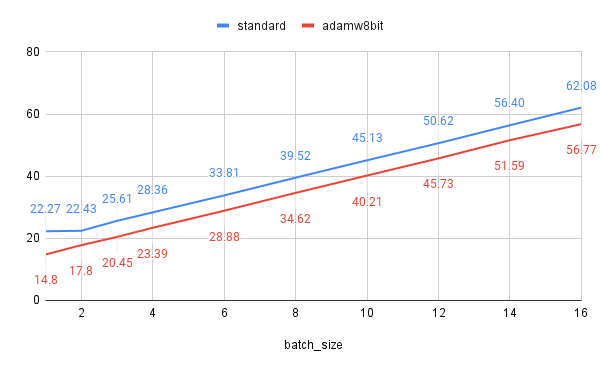
理論的には、UNetのサイズが3.23GiBなので、3.23*2-3.23*2/4=4.845GiB分減らせるはずですが、だいたい数字通りになってますね。バッチサイズ1のときどうしてこうなるかはよく分かりませんが。
AMP(Auto mixed precision)
AMPとはfloat32でモデルや勾配を保持しつつ、途中の計算をfloat16で計算、保存することで計算時間やVRAM使用量を削減します。例の訓練コードにはfull_fp16というモデルや勾配までfloat16で計算するオプションがあります。またbfloat16というfloat16と比べあんだーふろぉやおーばーふろぉが起こりにくい型を使用する場合があるというかこっちの方が安定感あるので実験ではこっちを使います(VRAM使用量には影響しないはずですが)。

AMPを使う場合、float32とfloat16の両方のモデルを持っておく必要があるため、バッチサイズによってはAMPを使う方がVRAM使用量が大きくなるということもあり得るそうですが、今回は起きてないですね。
full_bf16のVRAM削減効果は想像していたより強力ですね。モデルや勾配の型が変わるだけだったらバッチサイズに依存しない減少量になるのかなと思ったのですが、それだけではないみたいですね。
Gradient Checkpointing
Gradient Checkpointingは逆伝搬に必要な順伝搬時の情報を全てキャッシュするのではなく、一部のチェックポイントのみキャッシュしておき、逆伝搬時はチェックポイントから計算しなおすことで、学習速度を犠牲にしつつVRAM使用量を削減する方法です。
↓神記事

理論的にはバッチサイズに対して$${y=\sqrt{x}}$$のペースで増えていくみたいですが、ほとんど平らに見えますね。増えるどころか減ったりすることもあって何だこりゃという感じです。
※diffusers==0.19.3ではUNetのmid blockにgradient checkpointingが適用されませんが、この実験では適用しています。
画像サイズ
シンプルに画像サイズを変えた時の比較をします。

傾きが変わるだけですね。黄線のバッチサイズ4と赤線のバッチサイズ16を比較してみると、ほとんど同じであることが分かります。画像サイズが4倍になるのと、バッチサイズが4倍になるのとでほとんど意味は同じということですね(画像サイズに依存しない層もありますけど)。
xformers vs sdpa
xformersとpytorch>=2.0で標準搭載されたsdpaを比較してみます。
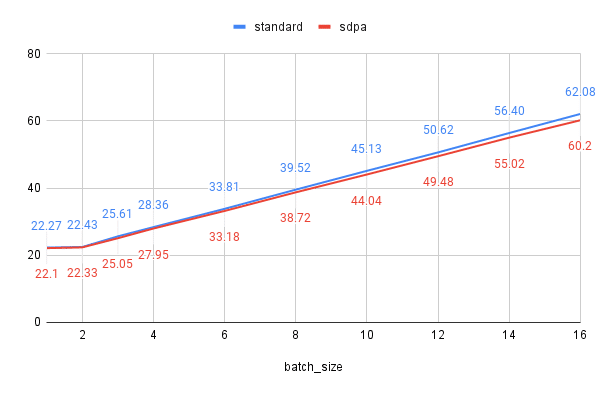
ちょっとsdpaの方がVRAM使用量が少ないです。ただし学習時間はxformersの方が早い感じです。
結果(LoRA編)
ほとんどの方はLoRAしかやらないだろうし、こっちの方が重要なのかも
通常のファインチューニングとの比較

削減量はほぼ定数で、バッチサイズにはほとんど依存しないようですね。モデルそのもの、モデルの勾配、Optimizerのキャッシュと全部でモデルサイズの4倍分のVRAM使用量がLoRAサイズの4倍まで削減されるので、約12GiBくらい削減されているようです。
これからはloraのrank=16を基本設定として比較していきます。
LoRAのサイズ

LoRAをLoConにしたり、rankをあげたりすると順当にVRAM使用量があがるみたいですね。数字が重なっててよく見えませんがまあいいや。ちなみにLoHAもやりましたが、ちょっと増えるくらいでした。
LoRA-FA
LoRAのdown層をランダムなまま凍結する方法です。バッチサイズや画像サイズが大きくなったときのVRAM増加量が抑えられます。

とりあえず適当に実装してみましたが、確かに効果はあるようですね。でもこんなことするよりgradient checkpointing使った方がいいんじゃ。。。
Gradient Checkpointing
というわけでgradient checkpointing

LoRAでもやはり強力ですね。もちろん計算時間が増えるというデメリットはありますが。
AdamW8bit
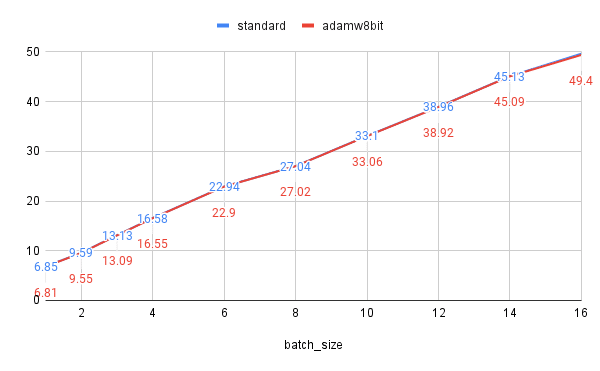
見て分かる通りほとんど効果ないです。これはAdamW8bitの効果が学習対象のモデルサイズに依存するからです。rank=16のLoRAのサイズは大したものではないです。
AMP

通常のファインチューニングと傾向は同じですね。やる意味あったのかな。
まとめ
だいたい3つに分けられそうですね。
定数で抑える$${y=ax+b-b'}$$:
モデルのオフロードやAdamW8bit、LoRAがそうです。
傾きを抑える$${y=(a-a')x-b}$$:
AMPやLoRA-FAのことです。
計算量オーダーを抑える$${y=f(ax)+b}$$
Gradient checkpointingのことです。
低バッチサイズでは1番目が、高バッチサイズでは2, 3番目が有効という感じですね。
