
NVDA 23年第1四半期決算発表

Nvidia Corporation (NASDAQ:NVDA) は、水曜日の午後に直近の四半期決算を報告した。同社の株価は、予想以上の結果を受け、また、非常に強力なガイダンスにより急騰した。
・Q1のNon-GAAP EPSは$1.09で$0.17上回る。
・売上高は$7.19B(前年同期比-13.3%)で$670Mを上回る。
・データセンターの売上が42.8億ドル。
・2024年度第1四半期に、エヌビディアは9900万ドルの現金配当金を株主に還元した。
・エヌビディアは、2023年6月30日に、2023年6月8日の登録株主全員に対して、1株当たり0.04ドルの次の四半期現金配当を支払う予定。
第2四半期の見通し(ガイダンス):
・売上高は、コンセンサスの71億1,000万ドルに対して110億ドル、プラスマイナス2%と予想。
・GAAP基準の売上総利益率は68.6%、非GAAP基準の売上総利益率は70.0%、プラスマイナス0.5%と予想。
・営業費用は、GAAP方式で約27億1,000万ドル、非GAAP方式で約19億ドルと見込み。
・GAAP方式及びNon-GAAP方式のその他の収入及び支出は、非関連投資からの損益を除き、約9,000万ドルの 利益となる見込み。
・GAAP方式および非GAAP方式の税率は、離散的項目を除き、プラスマイナス1%の14.0%となる見込み。
・l 前回と同様に0.04ドル/株の四半期配当を宣言。フォワード配当は0.05%。6月30日支払い、6月8日登録株主、6月7日配当落ち。
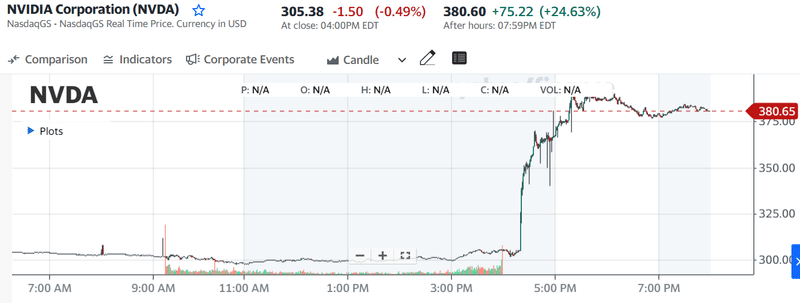
※株価は、リリース後+20%上昇、一時+30%越えまで上昇。カンファレンス・コールを通じて、+25%程度($380程度)で取引されている。
決算発表についてのコメント
Nvidiaの売上高は72億ドルで、予想を10%ほど上回ったことがわかる。同時に、売上高は1年前と比較して2桁の減少となっている。Nvidiaのような成長企業にとって、これは絶対的に強い結果とは言えない。Nvidiaの純利益を1株当たりで見ると、Nvidiaは、同じく予想を20%程度上回ることができた。一株当たり利益は前年同期比で20%減少しており、この期間も苦戦を強いられていたことがわかる。
Nvidiaの次四半期(会計年度第2四半期)に対するガイダンスは素晴らしいものだった。売上高を110億ドル、プラスマイナス2%と予測している。第2四半期の収益ガイダンスは、同四半期の収益コンセンサス予想71億ドルを52%上回っている。110億ドルのガイダンスは、Nvidiaがこれまでに生み出した四半期収益最高額(それは2023年第1四半期、つまり1年前)と比べてもはるかに高いものである。
時間外取引で市場はこの結果に非常にポジティブに反応し、エヌビディアの株価を上昇させた。NVDAは市場後取引で25%上昇しており、これは380ドルの株価に相当する。52週間ぶりの高値となるだけでなく、史上最高値を更新することになる。時間外の値動きは、Nvidiaの時価総額に1,000億ドル以上が追加されたことを意味し、それが正当化されるかどうかは議論があるにせよ、確かに印象的である。
Nvidia(NVDA)について
Nvidiaの目の前にあるAIの機会が巨大であることは疑いようがない。3月23日、ビル・ゲイツは「AIパーソナルアシスタント」を最初に開発した企業は、検索やアマゾン・ドット・コム社(AMZN)を時代遅れにすると発言した。ここでの意味合いは、この「AIアシスタント」が、今の検索やアマゾンと同じくらい多くの人に使われるようになる、ということだ。
先日、Meta Platformsは、NVIDIA A100 GPUを16,000個使用していることを明らかにした。1個1万ドルの価格で、MetaのA100の発注だけで1億6000万ドルもかかっている!
そしてもちろん、マイクロソフト社(MSFT)やグーグルことアルファベット社(GOOG、GOOGL)は、AIについてメタの先を行き、ビジネスプロセスだけでなく、コンテンツ制作にも活用している。グーグルのA100チップの数を正確に数えることはできなかったが、A100のサーバー時間をGoogle Cloudのユーザーに貸し出していることを考えると、その数はかなり多いと思われる。GoogleはMetaよりもはるかに大きなビジネスであり、Metaよりも多くのAIを手がけているので、A100チップの数はおそらくMetaを上回るだろう。
これらのことから、Nvidiaは急成長している業界(半導体ではなく、AIという意味)において、素晴らしい競争力を持っていると主張する傾向があるだろう。
Nvidiaにとっての課題
ただ、1つだけ問題がある。上記のハイパースケーラー企業は、自社でGPUを構築することを望むようになってきている点である。
Metaが16,000個のA100チップを使用しているという話は、表面的には強気に見えるかもしれないが、さらに下を読むと、Metaは実際にこれらのチップの設計を自ら始めようとしていることがわかる。アップル社(AAPL)はすでに自社でチップを設計しており、それらは台湾セミコンダクター・マニュファクチャリング社(TSM)によって製造されている。もし多くの企業がアップルやメタのように独自のAIチップを設計するようになれば、実際のAI勝者はNvidiaではなくTSMになるだろう。したがって、ここでのNVDAの立場は揺るぎないものではない。
また、Nvidiaと競合する他のチップ企業の問題もある。現在、Nvidiaは大手テック企業のサプライヤーとして選ばれているが、競合他社はその差を縮めつつあるという。例えば、Googleは最近、自社のテンソルチップがA100よりも高速に計算することを発表した。具体的には、同社のチップはA100よりも1.7倍高速で、1.9倍電力効率が良いという。この主張が本当なら、GoogleがA100システムを使い続けるとは考えにくい。Nvidiaにとっては、まさに競争上の脅威となる。GoogleはNvidiaからの購入をやめることができるだけでなく、他社にチップを販売するという新しいセグメントを立ち上げることができるかもしれない。そうなれば、Nvidiaのマージンはあっという間になくなってしまうが、Googleのビジネスモデルを考えれば、そんなことはしないだろうと思う。テンソルチップを自社で使うという利点と、そのチップによって得られる利点を維持することを好むだろう。
AMD(AMD)もデータセンター向けチップが好調であると報告している。FPGAに強みを持つザイリンクスを買収したことで、その相乗効果が期待される。
インテル(INTL)も黙ってはいない。最近の決算発表で、次世代データセンター向けチップを発表している。PC市場をほぼ独占してきた企業なので、現在のAIブームは既に補足領域にとらえている。ブロードコム(AVGO)もチップ開発において、データセンター向けで開始している。このように、半導体チップメーカー全体が生成AIに集中している。
それでは何が投資として魅力なのか?コメントとぼやき
生成AIはウォールストリートを巻き込んで、膨大な資金を取り込む注目投資テーマである。
OpenAIはChatGPTで、AI投資ブームを引き起こした。マイクロソフト(MSFT)が年初に、OpenAIへの追加出資を発表したことから、AIブームは始まった。マイクロソフト(MSFT)は明らかに、業界に激震を走らせた。マイクロソフトは、2月には検索エンジン「Bing」にAIを搭載し、さらに「Copilot」を発表し、マイクロシフトの製品全般にAI利用を拡大していくことを発表した。
ChatGPTと生成AIの登場でアルファベット(GOOG、GOOGL)は大きな衝撃を受けた。しかし、アルファベットも巻き返しに躍起になっている。つい最近、「バード;Bard」を発表した。また、最新の大規模言語モデル「PaLM 2」を搭載し、文章や表などを生成できると発表した。先行する米マイクロソフトの「Copilot」に、グーグルの「Duet AI」が挑んでいる。
メタ(META)も生成AIブームに乗っかている。メタの限らず、ほぼすべてのIT企業は生成AIへの投資・開発に躍起になっている。アマゾン(AMZN)、IBM(IBM)やオラクル(ORCL)、セールスフォース(CRM)、アクセンチュア(ACN:エンタープライズAI)、SAP(SAP:エンタープライズAI)といった大手IT企業もブームに乗っている。
上場していないが、様々なAIソフト開発企業が存在している。SPARCを通じたIPOが出てきてもおかしくない状況だ。
主なAI開発企業としては、新興企業も含めて以下のような企業が存在する。
サービスナウ(NOW:エンタープライズAI)、C3AI(NYSE:AI エンタープライズAIソリューション開発)、アドビ(ADBE:ドキュメント・イラストレイター、文章画像生成)、サウンドハウンド(SOUN:音楽・音声生成)、ビッグベアAI(BBAI:エンタープライズAI)、パランティア(PLTR:エンタープライズAI)、サービスナウ(NOW)、オートデスク(ADSK:3D設計ソフト)、ユーアイパス(PATH:オートメーション・ソフト)、Hagging Face (コミュニティ主導のAI開発)、Cohere(自然言語処理)、Anthropic(カスタマイズ可能なコンテンツ作成)、Jasper(マーケティング)、Glean(従業員のユーザーエクスペリエンス)、Synthesis AI(多彩な生成AIのユースケース)、Stability AI(他の生成AIソリューションのための基礎モデル)、Lightricks(個人・クリエイティブ用途)、Inflection AI(未来志向のビジョン)、Synthesia(AI利用ビデオクリエーション)、Mostly.AI(エンタープライズAIソリューション)など。
さらに、AIを利用したヴィデオ生成や画像処理関連では、以下の企業も存在する。
Shutterstock(NYSE:SSTK)、GetIMG、NightCafe、Dall-E2、Deep Dream Generator、Artbreeder、Stablecog、DeepAI、StarryAI、CF Spark、Fotor、Runway ML、WOMBO Dreamなど。
生成AIには、その処理に、GPUが最適とされる
事実上すべての初期の生成AIは、巨大なクラウドベースのデータセンターでしか実行できず、その多くは、入力されたデータを収集している。
現時点では、Nvidia(NVDA)はフロントランナーであることには、変わりない。NVDAに続く、GPUメーカーとしては、インテル(INTL)、AMD(AMD)があげられる。近く、上場が予定されているイギリスのアーム(ARM)も期待できるチップメーカーである。
インテル(INTL)は、ファウンドリー・ビジネスを始めており、ARMのチップ製造を開始する。今後、インテル/ARMの提携が拡がり、連合が成立した場合は、Nvidiaにとって脅威となるのでないだろうか?過去、ビジネス利用において、インテルのx86系統のチップはほぼ独占してきた。互換性を兼ねたチップの導入は、ビジネス利用ユーザーには心強いことになろう。
アーム(ARM)の上場には注目すべきである。世のスーパーコンピューターの心臓部にはアームのチップが使われている。ソフトバンクの収益にも大きく関係してくるので、日本の投資家にも大きな問題である。孫さんのことだから、生成AI向けチップの開発とかを話題に大キャンペーンを張ってくることだろう。
AMDも、買収したザイリンクスとの相乗効果もあり、GPU市場に参入している。AMDはこれまでCPU市場で王者インテルの牙城を高性能・廉価版CPUで切り崩してきた。GPUにおいても同様のことを狙っている。
データセンターにおいて生成AIの計算をする場合に、なにが必要になってくるのかを考えた場合、GPUを搭載したサーバーにも注目する必要がある。
スーパーマイクロ(SMCI)は、最近の決算発表で、次四半期のガイダンスにおいて、コンセンサスを大幅に上回り、株価は高値を更新している。第1四半期には、GPUなどの主要部品が足りなくて、ガイダンスを下回っていた。それだけ、サーバーの需要が大きいということだ。
データセンター向けのサーバーということであれば、これまでサーバー市場を牛耳ってきたデル(DELL)とヒューレットパッカード(HPE)も生成AI向けの対応に追われている。ただし、DELLとHPEはAI特化というわけではなく、PCなど多角化を図っているので、直接恩恵を受けにくい構造ではある(コングロマリット)が、注目はしておいていいだろう。
一方、GPUの内製化が進んでくると、チップの設計ソフトメーカーも注目である。最大手としては、シノプシス(SNPS)と業界2位のケイデンス・デザイン(CDNS)は注目に値する。チップの製造・設計は、より精密化、微細化、多層化が進んでおり、チップ設計は、効率性を向上させるためにも極めて重要な分野である。チップ製造をしたことのない企業は、こうした設計ソフトを使うことになる。
内製化を進めている背景には、台湾セミコンダクター(TSMC:TSM)というファウンドリーの存在を忘れてはいけない。アップルのMチップはTSMで製造されている。TSMの売上25%以上はアップルである。チップメーカー各社は、TSMの製造キャパシティーの奪い合いとなってもおかしくはない。TSMとしては、最も収益率が高く、単一スペックで製造できるチップメーカーを選択することになるであろう。いかにTSMとの関係を構築していけるのかという点もポイントになってくる。正直なところ、うるさすぎる儲からない顧客はどの業界でも嫌がられる。そのような顧客は、ひとしれず、市場に埋もれていくことになる。因みに、アップルが内製化を始めた時、サムソンでも試作したようだが、アップルの要求を満たすことができず、チップ製造はTSMに集中している。
ファウンドリーという点でいえば、GFSやインテル(INTL)も注目される。日本でも半導体製造・投資が話題になっているが、その投資対象は、イメージセンサーとメモリーであり、AIブームの本命であるGPU製造についての話題はほとんど聞かれない。政府主導の大本営発表にようにしか聞こえない。日立グループとかが、いまこそGPUのファウンドリーを始めても面白いのではないか?かつての半導体立国としての日本を知っているものにとっては、悲しいものである。すべては、メモリー中心であったことが間違いであったのではないか?
最近、世界最大の半導体製造装置メーカーであるアプライドマテリアル(AMAT)は、次世代チップ開発センター(EPICセンター)を設立した。内製化の動きに呼応しているということもでき、AMATには注目していきたい。AMATは、次世代露光装置も発表しており、オランダのASML(ASML)がほぼ市場を独占している最先端露光装置の牙城を崩すことができるとしたら、次世代の半導体製造と開発はアメリカにほぼすべて戻って集中する可能性がある。
生成AIは、そのソフト、プログラムが最も肝になる部分ではあるが、計算をするうえでは、データセンター、サーバー、そしてそれを動かすチップはソフト会社すべてが利用するものである。
ここでもう一度、投資の格言を思い出したい。ゴールドラッシュに際に、もっとも儲かったのは、金鉱石を掘る労働者ではなく、金鉱石を掘る道具であるシャベルとピッケルであった、ということを!
参考資料:TSLAとNVDAのPER推移

NVDAがどれだけ割高かを判断する材料として、テスラ(TSLA)のPERとの比較チャートを添付した。NVDAのPER倍率は100倍を超えようとしているが、過去TSLAのPERは、1000倍を超えて取引されていた時期もあった。バブルとはこういうものである。バブルが終わるまでは誰も分からない。
カンファレンスコールで注目すべき内容をまとめてみた。
ジェンセン・フアン(Jensen Huang):共同創業者、CEO、社長からのカンファレンスコール終了時の締めの言葉
コンピュータ業界は、アクセラレーテッド・コンピューティングとジェネレーティブAIという2つの転換期を同時に迎えています。CPUのスケーリングは鈍化していますが、コンピューティングの需要は強く、そして今、ジェネレーティブAIが超高速化しています。NVIDIAが開拓したフルスタック、データセンター規模のアプローチであるアクセラレーテッド・コンピューティングは、最善の道です。世界のデータセンター・インフラには、前時代の汎用コンピューティング方式に基づいて、1兆ドル規模で設置されています。企業は今、生成的なAI時代のための加速コンピューティングを導入するために競争しています。今後10年間で、世界のほとんどのデータセンターがアクセラレーション化されるでしょう。
急増する需要に対応するため、供給量を大幅に増やしています。大規模な言語モデルは、多くの形態で符号化された情報を学習することができます。大規模な言語モデルに導かれ、生成AIモデルは驚くべきコンテンツを生成することができます。微調整、ガードレール、指導原則への整合、事実の根拠となるモデルにより、生成AIは研究所から生まれ、産業応用への道を歩み始めています。
クラウドやインターネットサービスプロバイダとともに規模を拡大しながら、私たちは世界最大の企業向けのプラットフォームも構築しています。ServiceNowやAdobeのような主要なエンタープライズ・プラットフォームであれ、NVIDIA AI Foundationsのようなオーダーメイドであれ、私たちのCSPパートナー内またはDell Helixのオンプレミスであれ、企業がドメインの専門知識とデータを活用して安全かつ確実にジェネレーティブAIを活用できるようにすることができます。
私たちは、H100、GraceとGrace Hopperスーパーチップ、BlueField-3、Spectrum 4ネットワーキング・プラットフォームなど、今後の四半期に新しい製品を立ち上げようとしています。これらはすべて生産が開始されています。これらの製品は、データセンター規模のコンピューティングを実現し、エネルギー効率に優れた持続可能なコンピューティングを提供するのに役立つことでしょう。
来週のCOMPUTEXにご参加いただければ、次の展開をお見せすることができます。
質疑応答
いくつか注目すべきQ&Aをピックアップした。今は、データセンターにおける生成AIが最も注目されているので、あえて、ゲーム用GPUや暗号資産のマイニング向け用途、好調であった自動車向け用途については、取り上げていない。
Q) AIをサポートし加速させるという点で、どのような状況にあるのでしょうか。今後数年間、リードタイムをどのように管理したいのか、需要と供給のベストマッチングをどのように考えているのでしょうか。
A) ChatGPTの瞬間が訪れたとき、私たちはAmpereとHopperの両方をフル生産していたことを思い出してください。そして、大規模な言語モデルの技術から、チャットボットをベースにした製品やサービスへと移行する方法を、皆が結晶化させることができました。強化学習による人間のフィードバック、独自の知識のためのナレッジベクターデータベース、検索への接続など、ガードレールやアライメントシステムの統合は、本当に素晴らしい方法で実現しました。そして、私たちはすでにフル生産を開始していたのです。NVIDIAのサプライチェーンの流れ、私たちのサプライチェーンは、ご存知のように非常に重要です。
私たちはスーパーコンピュータを大量に製造しており、これらは巨大なシステムです。もちろんGPUも含まれますが、GPUを搭載したシステムボードには、その他に3万5,000個の部品があります。ネットワーク、光ファイバー、トランシーバー、NIC、スマートNIC、スイッチなど、データセンターを立ち上げるためには、これらすべてが揃っていなければなりません。そのため、いざというときには、すでにフル稼働していました。下期は調達量を大幅に増やさなければなりません。
さて、もっと大きな視点で話をさせてください。全世界のデータセンターがアクセラレーション・コンピューティングに移行している理由についてです。アクセラレーテッド・コンピューティングはフルスタックの問題であることは以前から知られていましたし、私がその話をするのも聞いていると思います。もし十分に実現できれば、データセンターの主要なアプリケーションのほとんどを高速化することができます。データセンターで消費されるエネルギー量とコストを、1桁減らすことができます。そのためには、ソフトウェアやシステム構築など、あらゆる面でコストがかかりますが、15年間はそれを実現できませんでした。
そして今、私たちは2つの転換期を同時に迎えています。世界の1兆ドル規模のデータセンターは、現在ほぼCPUで占められており、1兆ドル、年間2500億ドル、それはもちろん成長しています。しかし、この4年間で、1兆ドル相当のインフラが導入されたと言えるでしょう。そしてそれはすべて、CPUとダムNIC(ph)に完全に基づいています。基本的に非加速です。今後、世界のほとんどのデータセンターで情報を生成する主要なワークロードがジェネレーティブAIになることは明らかで、アクセラレーション・コンピューティングがエネルギー効率に優れていることから、データセンターの予算はアクセラレーション・コンピューティングに劇的にシフトすることが予想されます。私たちは今、まさにその瞬間を迎えています。世界のデータセンターの設備投資予算は限られていますが、同時に、世界のデータセンターの再編成を求めるすごい注文が来ています。
つまり、世界のデータセンターを基本的にリサイクルまたは再生し、アクセラレーテッド・コンピューティングとして構築するという、10年単位の移行が始まっていると言えるでしょう。データセンターは、従来のコンピューティングから、スマートNICやスマートスイッチ、もちろんGPUを搭載したアクセラレーテッド・コンピューティングへと劇的に変化し、そのワークロードは主にジェネレーティブAIになると思われます。
Q) 競争環境はどうなるのでしょうか?また、他のGPUソリューションや他の種類のソリューションの競争も激化するのでしょうか?今後2~3年の間に、競争環境はどのように変化していくとお考えでしょうか?
A) 競争についてですが、私たちはあらゆる方向から競争を受けています。スタートアップは、本当に資金力のある革新的なスタートアップで、世界中に数え切れないほどあります。また、既存の半導体メーカーとの競争もあります。社内プロジェクトを持つCSPとの競争もあります。これらのほとんどは、皆さんもご存知の通りです。このように、私たちは常に競争を意識していますし、常に競争を受けています。しかし、NVIDIAの価値提案の核心は、「最も低コストなソリューションである」ということです。その理由は、アクセラレーテッド・コンピューティングは、私がよく話している2つのことです。また、エンジニアリングや分散コンピューティング、基礎的なコンピュータサイエンスの仕事は、実に並大抵のものではありません。私たちが知る限り、最も困難なコンピューティングです。
そのため、第一に、フルスタックでの挑戦となり、全体にわたって最適化しなければなりませんし、驚くほど多くのスタックにわたって最適化しなければなりません。私たちには400ものアクセラレーション・ライブラリがあります。ご存知のように、私たちがアクセラレーションを行うライブラリやフレームワークの量は、かなり気の遠くなるような量です。これは、コンピュータがデータセンターであるとか、データセンターがコンピュータであるとか、チップではなくデータセンターであるとかいう考え方で、これまでこのようなことはありませんでした。この特殊な環境では、ネットワーク・オペレーティング・システム、分散コンピューティング・エンジン、ネットワーク機器、スイッチ、コンピューティング・システム、コンピューティング・ファブリックのアーキテクチャに対する理解、システム全体がコンピュータであり、それを運用しようとしています。最高のパフォーマンスを得るためには、フルスタックを理解し、データセンターの規模を理解する必要がありますし、それがアクセラレーション・コンピューティングです。
2つ目は、利用率です。これは、高速化できるアプリケーションの種類と、当社のアーキテクチャの多様性によって、利用率が高く保たれることを意味します。もし、1つのことしかできず、信じられないほど高速に処理できるのであれば、データセンターはほとんど利用されておらず、その規模を拡大することは困難です。つまり、ユニバーサルGPUは多くのスタックを高速化するため、利用率が非常に高くなります。そのため、1つ目はスループットで、これはソフトウェア--ソフトウェア集約型の問題であり、データセンターのアーキテクチャの問題です。2つ目は利用効率の問題で、3つ目はデータセンターに関する専門知識です。私たちは、自社で5つのデータセンターを建設し、世界中の企業のデータセンター建設を支援してきました。また、私たちのアーキテクチャを世界中のクラウドに統合しています。
製品の納品から導入時の立ち上げまで、データセンターの運用にかかる時間は、下手すると数ヶ月かかることもあります。スーパーコンピュータの場合、世界最大級のスーパーコンピュータが1年半前に設置され、現在オンラインになりつつあります。私たちの場合、運用開始までの期間は数週間単位です。また、データセンターとスーパーコンピュータを製品化しましたが、その際のチームの専門知識は素晴らしいものでした。ですから、私たちの価値提案は、最終的には、これらの技術をすべてインフラに反映させ、可能な限り低いコストで最高のスループットを実現することです。ですから、私たちの市場は、もちろん非常に競争が激しく、規模も大きいです。しかし、その挑戦は本当に素晴らしいものです。
Q) ソフトウェアのマネタイズ効果についてどのように考えるべきでしょうか?AIエンタープライズソフトウェアスイートやその他のソフトウェアのみの収益のドライバーについて、そのアプローチについて、私たちはどのような状況にあるとお考えでしょうか。
A) 生成AIとCSPは、モデルのトレーニング、モデルの改良、モデルの展開のいずれにおいても、リアルタイムでその成長を確認することができます。推論がアクセラレーション・コンピューティングの主要な推進力となっています。新しいソフトウェアのスタックを必要とするセグメントは2つあり、エンタープライズとインダストリーの2つです。エンタープライズでは、新しいソフトウェアのスタックが必要です。なぜなら、多くの企業は、大規模な言語モデルであれ、これまで述べてきたようなすべての機能、適応能力、独自のユースケースや独自のデータに対して、独自の原則や運用ドメインに合わせる能力を持つ必要があるからです。それをハイパフォーマンス・コンピューティングのサンドボックスで行えるようにするのが、私たちDGX Cloudであり、モデルを作成します。そして、チャットボットやAIをどのクラウドにも導入したいとか、複数のクラウドベンダーと契約し、アプリケーションによっては、さまざまなクラウドに導入することができるからです。
企業向けには、カスタムモデルの作成を支援するNVIDIA AI FoundationとNVIDIA AI Enterpriseがあります。NVIDIA AI Enterpriseは、世界で唯一のアクセラレーションスタック、GPUアクセラレーションスタックで、エンタープライズセーフで、エンタープライズサポートされています。常にパッチを当てる必要があり、NVIDIA AI Enterpriseを構築する4,000種類のパッケージがあり、AIワークフロー全体のオペレーティングエンジン、エンドツーエンドのオペレーティングエンジンに相当します。データの取り込みからデータ処理まで、この種のものとしては唯一のものです。明らかに、AIモデルを訓練するためには、大量のデータを処理し、パッケージ化し、キュレーションし、整列させる必要があります。このようなデータ量は、計算時間の40%、50%、60%を消費することもあり、データ処理は非常に大きな問題です。
そして、2つ目の側面は、モデルのトレーニング、モデルの改良、3つ目は、推論のためのモデルのデプロイメントです。NVIDIA AI Enterpriseは、これら4,000のソフトウェアパッケージのすべてをサポートし、パッチやセキュリティパッチを継続的に適用しています。エンジンを導入したい企業にとって、Red Hat Linuxを導入したいのと同じように、これは非常に複雑なソフトウェアで、あらゆるクラウドやオンプレミスに導入するためには、安全であること、サポートされていることが必要になります。
3つ目は「Omniverse」です。AIを倫理に合わせる必要があることに人々が気づき始めたように、ロボット工学も同じで、AIを物理に合わせる必要があります。そして、AIを倫理に合わせるというのは、強化学習ヒューマンフィードバックという技術があります。産業応用やロボティクスの場合は、強化学習Omniverseのフィードバックです。そして、Omniverseはロボットアプリケーションや産業におけるソフトウェア定義に欠かせないエンジンです。そのため、Omniverseはクラウドサービスプラットフォームである必要があります。
私たちのソフトウェアスタック、AI Foundation、AI Enterprise、Omniverseの3つのソフトウェアスタックは、DGX Cloudとパートナーシップを結んでいる世界中のすべてのクラウドで動作します。
Azureとは、AIとOmniverseの両方でパートナーシップを結んでいます。GTPとオラクルとは、DGX CloudでAIに関する素晴らしいパートナーシップを結んでおり、AI Enterpriseはこれら3社すべてに統合されています。クラウドを超えて、世界の企業や産業界にAIの範囲を広げるためには、2種類の新しいソフトウェア・スタックが必要です。
Q) InfiniBandとEthernetの比較についてですが、その議論と今後の展開についてお聞かせください。
A) InfiniBandとEthernetは、データセンターでの用途が異なるということですね。両者にはそれぞれ適材適所があります。InfiniBandは記録的な四半期でした。今年も記録的な大台に乗せるでしょう。NVIDIAのQuantum InfiniBandは、非常に優れたロードマップを持っています。本当にすごいことになりそうです。しかし、この2つのネットワークは非常に異なっています。InfiniBandは、言ってみればAI工場向けに設計されています。そのデータセンターが、特定のユースケースで数人分のアプリケーションを実行し、それを継続的に行っていて、そのインフラに5億ドルというコストがかかるとします。
InfiniBandとEthernetの差は、全体のスループットで15%から20%になる可能性があります。もし、5億ドルをインフラに費やして、その差が10~20%で、それが1億ドルであれば、InfiniBandは基本的に無料になります。それが、人々が使う理由です。InfiniBandは実質的に無料なのです。データセンターのスループットの差は、無視できないほど大きく、その1つのアプリケーションのために使っているわけです。データセンターは小さなジョブの集まりで、何百万人もの人々が共有しています。
そうなると、イーサネットは本当に答えられるのでしょうか?クラウドが生成AIクラウドになりつつあり、そのど真ん中に新しいセグメントとして存在しています。それ自体はAI工場だけではありません。しかし、マルチテナントクラウドであることに変わりはなく、生成AIワークロードを実行することを望んでいます。この新しいセグメントは素晴らしい機会であり、前回のGTCで言及しました。COMPUTEXでは、このセグメントのための主要な製品ラインを発表する予定です。それは、Ethernetにフォーカスした生成的なAIアプリケーションタイプのクラウドです。
しかし、InfiniBandは素晴らしく好調で、前四半期比では前年同期比で記録的な数字を出しています。
Q) 推論にフォーカスしているという点で、クラウドのお客様は、クエリーあたりのコストを非常に大きく削減しようとしていることも話題になっています。クエリーあたりのコストを下げるために、どのようにお客様をサポートするつもりなのでしょうか?
A) 大規模な言語モデルを構築することから始め、その大規模な言語モデルを使って、中、小、極小のサイズに絞り込むことができます。小さなサイズのものは、携帯電話やPCなどに入れることができ、どれも良いものです。しかし、ゼロショットや大きな言語モデルの一般化への可能性は、明らかに大きなもののほうが汎用性が高く、もっとすごいことができます。そして、大きな言語モデルは、小さな言語モデルに良いAIになる方法を教えることができます。ですから、まずは非常に大きなものを作ることから始めます。そして、小型のAIを大量に訓練する必要があります。
これが、推論にさまざまな大きさのものを用意した理由です。L4、L40、H100 NBL、H100 HGX、そしてNVLinkを搭載したH100マルチノードを発表しましたが、このように、好きな種類のモデルサイズを用意することができます。
もう1つ重要なのは、これらはモデルですが、最終的にはアプリケーションに接続されているということです。アプリケーションは、画像入力、ビデオ出力、ビデオ入力、テキスト出力、画像入力、タンパク質出力、テキスト入力、3D出力、ビデオ入力、将来的には3Dグラフィックス出力などが考えられます。
つまり、入力と出力には、多くの前処理と後処理が必要です。前処理と後処理を無視することはできません。これは、特化型チップの議論が破綻する原因の1つで、モデル自体の長さが、推論処理全体のデータの25%程度に過ぎないからです。残りの部分は、前処理や後処理、セキュリティ、デコードなど、あらゆる種類の処理に関わるものです。
ですから、推論のマルチモダリティ、推論のマルチダイバーシティは、オンプレミスのクラウドで行われることになると思います。マルチクラウドで行われるでしょう。それが、私たちがAIエンタープライズをすべてのクラウドで展開している理由です。
先日発表したDellとの素晴らしいパートナーシップ「project Helix」は、サードパーティーのサービスに統合される予定です。また、ServiceNowやAdobeとも素晴らしいパートナーシップを結んでおり、彼らは生成的なAI機能を大量に生み出す予定です。このように、ジェネレーティブAIの領域は非常に広いので、その全領域に対応するためには、今説明したような非常に基本的な能力が必要になってきます。
Q) InfiniBandやEthernetソリューション、加速されたコンピュート・プラットフォームが非常に高い評価を得ていることを考えると、ネットワーキングのランレートはコンピュートと同じように上がっているのでしょうか。また、コンピュートの複雑性やデータセット、低レイテンシーやトラフィックの予測可能性などの要件の大幅な増加に対応するため、今後さらにネットワーク帯域を確保するために、チームはどのような取り組みを行っていますか?
A) AIについて考える人はほとんど皆、アクセラレータ・チップのことを考えますが、実は、それはほとんど完全に的外れなことです。アクセラレーション・コンピューティングとは、スタック、ソフトウェア、ネットワーキングのことで、私たちはDOCAというネットワーキング・スタックを非常に早くから発表し、マグナムIOというアクセラレーション・ライブラリーを提供しています。この2つのソフトウェアは、当社の至宝のようなものです。理解しにくいので誰も話題にしませんが、このソフトウェアのおかげで、10台、1000台のGPUを接続することが可能になりました。
インフラであるデータセンターのオペレーティング・システムが非常に優れていなければ、どうやって1万個ものGPUを接続することができるのでしょうか。それが、私たちが社内でネットワークにこだわる理由です。
NVLinkは、超低レイテンシーのコンピューティング・ファブリックで、ネットワーク・パッケージではなく、メモリ参照を使って通信を行うものです。そして、NVLinkを複数のGPUの内部で接続し、GPUを超えると説明しました。これについては、数日後のCOMPUTEXでもっと詳しくお話しします。そして、NIC、SmartNIC BlueField-3、スイッチ、エンドツーエンドで最適化されたすべての光ファイバーを含むInfiniBandに接続されます。これらの製品は、信じられないほどのラインレートで動作しています。
さらにその先、スマートなAI工場をコンピューティング・ファブリックに接続したい場合、COMPUTEXで発表する全く新しいタイプのEthernetがあります。世界中のデータセンターにコンポーネントとして販売し、彼らが好きなスタイルやアーキテクチャに統合しても、私たちのソフトウェアスタックを動かすことができるようにしています。しかし、そのおかげで、NVIDIAのコンピューティング・アーキテクチャは、クラウドからオンプレミス、エッジから5Gまで、世界中のあらゆるデータセンターに統合することが可能になりました。
Q) データセンターにおける今後の大きなアップサイドは、DGX Cloudをサポートする可能性のあるシステムで、そのビジネスの可能性について、立ち上げてからわかったことについて、少し話していただけますか。
A) 理想的なシナリオは、10%のNVIDIA DGX Cloudと90%のCSPのクラウドのようなものです。その理由は、当社のDGX Cloudは、純粋なNVIDIAスタックだからです。私たちが好むように設計されており、可能な限り最高のパフォーマンスを実現します。そのため、CSPと深く連携し、最高性能のインフラを構築することができます。
例えば、私たちはAzureと提携し、世界の産業にOmniverseクラウドを提供することができます。このようなコンピューティング・スタックのシステムは、世界には存在しません。ジェネレーティブAI、3D、物理演算、大規模なデータベース、高速ネットワーク、低遅延ネットワーク、このようなバーチャルな産業用仮想世界は、これまで存在したことがありません。そこで、私たちはマイクロソフトと提携し、Azureクラウドの中にOmniverseクラウドを作りました。
これにより、2つ目の利点として、新しいアプリケーションを一緒に作り、新しい市場を一緒に開拓することができるようになりました。そして、私たちは1つのチームとしてマーケティングを行い、私たちのコンピューティング・プラットフォームをお客様に使っていただくことで、お客様は私たちをクラウドに置くことで利益を得ます。また、AzureやGCP、OCIが持つデータ量やサービス、セキュリティサービスなど、あらゆる素晴らしいものをOmniverse cloudを通じて瞬時に利用できるようになります。これは非常に大きなメリットです。
お客様にとっても、NVIDIAのクラウドが初期のアプリケーションに対応することで、どこでもできるようになります。NVIDIAのAIエンタープライズ、NVIDIA AIファウンデーションは、すべてのクラウドで1つの標準スタックが動作するため、お客様が自社のソフトウェアをCSPのクラウド上で動作させ、自社で管理したいと思われるなら、私たちはそれを歓迎します。また、長期的には、少し時間がかかりますが、NVIDIA OmniverseがCSPのクラウドで稼働することになります。
私たちの目標は、新しい市場や新しいアプリケーションを創造するために深く提携し、オンプレミスを含むあらゆる場所で実行できる柔軟性をお客様に提供することで、アーキテクチャを推進することでした。現在DGX Cloudを導入している3つのCSPとのパートナーシップは、その営業力、マーケティングチーム、リーダーシップチームが実に見事なものです。とてもうまくいっています。
以上
※当資料は、投資環境に関する参考情報の提供を目的として翻訳、作成した資料です。投資勧誘を目的としたものではありません。翻訳の正確性、完全性を保証するものではありません。投資に関する決定は、ご自身で判断なさるようお願いいたします。
#NVDA #NVIDIA #生成AI #GPU #データセンター
#生成AI用チップ #NVDA決算 #次世代データセンター
この記事が気に入ったらサポートをしてみませんか?