
AUTOMATIC1111+ControlNetのつかいかた4・img2img+lineart

1ヶ月以上AI触る余裕がなくて、ControlNet1.1がリリースされたのを横目に見てました。今更ふつうの覚書書いてもあれだろうと思い、img2imgでのControlNetの使い方について書きます。
1.1で変わったとこ
線画着色モデルなどが追加
ついに絵描きにストレートに役立つ機能が実装された?その他様々なモデルが追加してますが、今回はこれについて語ります。openposeが顔の表情+手ポーズに対応
すっげわかりやすい進化です。今回は触れません。既存のcannyなどの精度が向上
以前やったときはまともに塗れなかった線画が、結構できるようになった…かもしれない。プリプロセッサ画像だけ作れるようになった
デプスマップやノーマルマップだけ作って保存できるから、
PBRテクスチャを作るのにいいかも。2kサイズまで作れるようです
lineart_animeで線画着色
新たに追加されたこのモデルで、かなりまともに線画着色ができます。
AIが理解できてない形状もとりあえず無難に塗ってくれる、顔もcanny・scribbleよりは書き換えられなさげです。

しかし、色指定ができないのは相変わらずです。前よりはいう事聞いてくれる気はするのですが、仮にできたとしても、オリキャラの場合全身のデザインを文字にするのはかなり面倒です。
キャラをLoRa学習させる以外の解決策として、img2imgでのControlNetを使ってみます。
img2imgでControlNetを使う
img2imgでControlNetを使う場合のちがいは、
・完璧な色指定ができる
・txt2imgよりは塗りの質が落ちる
このBlenderで作ったオリキャラ3Dモデル・烏天狗ちゃんのレンダリング画像を使って、2D作画を作ってみます。

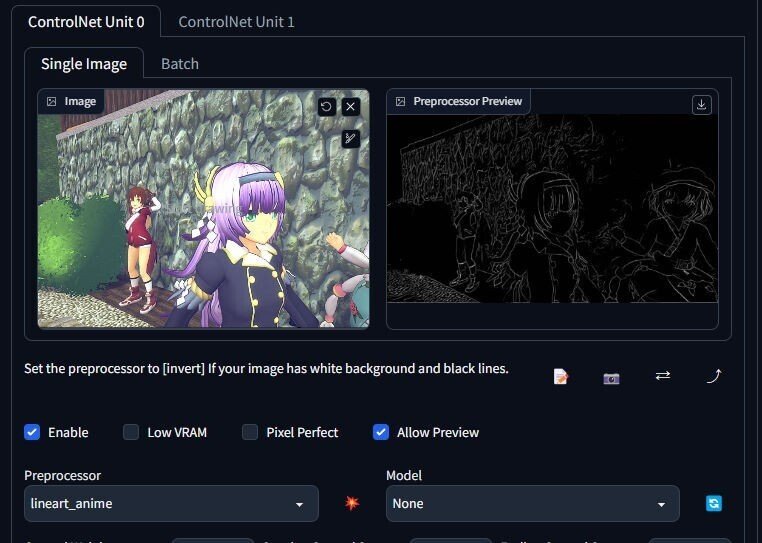
まずプリプロセッサlineartに元画像を入れて、線画を抽出します。

クリスタなどで潰れてる細部や顔を加筆します。誤認識しそうなキャラの周りの背景の線画は消します。(これはキャラ以外全部消しちゃったけど)

白黒反転させて作画して大丈夫です
なお、書き出した線画は微妙に元画像と縦横のピクセル数が違ってました。多分64の倍数pxとかにトリミングされてるんじゃないかと思います。
その場合は元画像を線画に合わせてトリミングする必要があります。
※私が絵を描くよりモデリングしたほうがマシに作れる人間だからこんなワークフローになってますが、2D絵師の場合は、普通に線画を描き、線画にベタ塗りで色つけて、それを元画像とすればいいのかな。(デフォルメしすぎない/下手すぎない絵柄に限ります。)もちろん素体や普通な服装ならscribbleやopenposeで作って時短もできるかも
元画像と線画と1girl jumping kick in japanese forrest,masterpiece, best quality…といった呪文でimg2img+CN(lineart_anime)すると、こうです↓

もとの画像の通りの色指定で作られました。
controlNetでも呪文で色指定することなく色塗りが忠実にできたわけですが、正直、大して変化してません。
そこで、この画像をさらにimg2imgにかけます。
Denoisingを増やす、control weightを減らす、start/ending stepを増減する、controlNetを使わず通常のimg2img、と設定を変えて数種類ほど作ります。

これらをどうするかというと、クリスタに読み込んで、使えるとこだけレタッチして1枚の画像にまとめます。
img2imgは、Denoisingを上げれば塗りはリッチになるけど形状がかけ離れる可能性が上がります。controlNet+lineartを使えば大まかな形状は乖離せず、各生成画像のズレが殆どできないので、この安直な技法の有効性は大きく上がりました。消しゴムツールだけでほぼ事足りました。
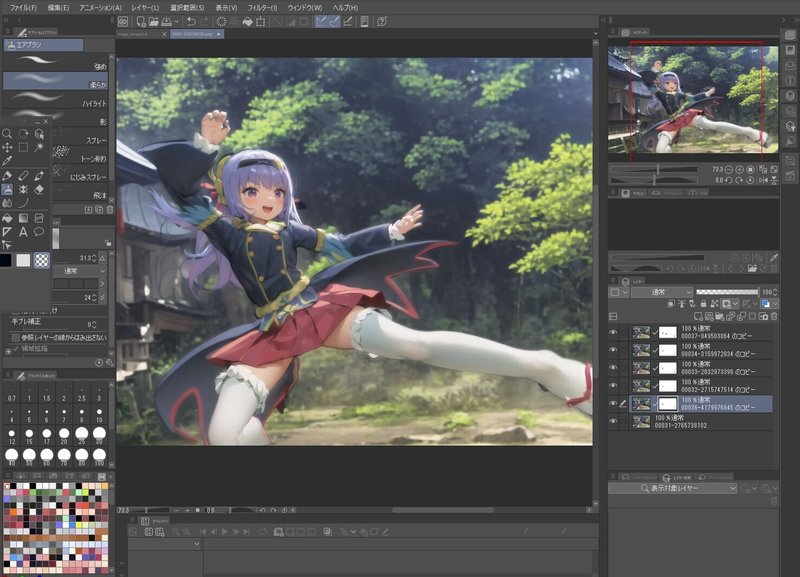
可逆加工をしてます。
いい感じに2D作画になった顔と髪, 最も描き込まれた服の塗り、崩れてない装飾品、などを抽出してくと、こうなります。

3DCG+トゥーンレンダでは作るのに高コストを要するディテールと2次元の嘘を付与した絵がつくれました。
マルチcontrolNetで精度をあげられないかと思ったけど、img2imgでは奇形率を上げるばかりで使えなさそうでした。
なので、エラーのないパーフェクト画像を引き当てるガチャは当てにせず、使えるとこだけ拾うのが現実的かなと思いました。異なるモデルで生成した画像だって混ぜられるしね。

しかしtxt2img+lineart_animeで作ると、もっとキレのある絵が作られます。

img2imgで作ったものとぱっと見の派手さが違う、塗りが盛り盛りで、頼んでないのに装飾とエフェクト盛られとう。色指定の効かなさがクソ残念。
これも使えるとこあるなら使ったらいい。
大まかな位置は同じだから、img2imgと同様の手段が使えるはずです。
線画+下塗りを作る工程でキャラ切り抜きマスクも作ってあれば、楽に合成できましょう。
全体の色味も背景もランダムなぶん、混ぜる難易度は高くなります。センスの見せ所。

img2imgで作った盛り不足の絵に手動で足してくことで、運任せのT2i一発出しより意図したものが作れてやり過ぎも回避できる。
TiledVaeも併用するといい
拡張機能Tiled Diffusionに含まれるTiledVaeというのがあって、
これを有効化するとメモリ節約できるようになるとかで、画像生成+ControlNetの複数がけがより高解像度でできるようになります。アップスケーラーと合わせたら4k画像の生成も実用の範囲かも
lineart_anime超強い!
lineart_animeが使い物になるのがわかりました。
今回あげた方法は、AIはあくまで補助で人間が描いたものと言って納得されるラインを目標にしています。
生成できる解像度も上がったことで、クリエイター性を保ちながらアイデア出し、レイアウト、ラフ、清書、塗り、仕上げのうち半分以上の工程をAutomatic1111+ControlNetでまかなえれると感じました。AIが全部書いたほうがいいよってなるかはアーチスト個人の問題として。
ただし注意
仕様だけ聞くと無敵に思えるcontrolnetですが、学習されてないモチーフ、Loraの併用、複数人の複雑な絡みなどで途端にクリーチャー量産機になるのは相変わらずです。いかにアウトを回避して複雑な絵を作れるかが次の課題になります。
凡庸な立ち絵が生成できたぐらいで浮かれて恥をさらさないようにしたいです。ゲームセット(呆)
この記事が気に入ったらサポートをしてみませんか?