
[論文紹介]NeRFのPositional Encidingをトモグラフィーに応用[ICCV21]

本日は,医療の現場で用いられるcomputed tomography(CT)技術に関する論文を紹介させていただこうと思います.
紹介する論文は,CT におけるill-posed inverse problemsを解消するための提案であり,NeRFのpositional encodingを取り入れていることが大きな特徴となります.
今日紹介する論文の詳細は以下になります.
タイトル:IntraTomo: Self-supervised Learning-based Tomography via Sinogram Synthesis and Prediction
機関:KAUST
著者:Guangming Zang, Ramzi Idoughi, Rui Li, Peter Wonka, Wolfgang Heidrich
会議:ICCV21
論文のリンク:https://openaccess.thecvf.com/content/ICCV2021/papers/Zang_IntraTomo_Self-Supervised_Learning-Based_Tomography_via_Sinogram_Synthesis_and_Prediction_ICCV_2021_paper.pdf
本記事では,上記論文を初見で読みながら内容をまとめていくスタイルをとっています.このため,論文を精読してまとめたというよりは流し読みしながらメモ程度にまとめた記事になっています.このため,より詳細を知りたい方は他のブログを漁ってみるか,ご自身で論文をご確認いただければと思います.
はじめに
CTは人体を輪切りにしてその断面を観察できる撮影技術のことです.肺の断面を撮影し感染症の診断を行ったりするなど体の中の状態を可視化することができます.
さてCTの撮影では,被写体の周囲をカメラ(センサ)で360度回転させながら撮影を行いますが,限られた角度からしか撮影できない場合,撮影の回数が少なくなってしまう場合などに,再構成後の画像のクオリティに悪影響を及ぼす可能性があります.論文ではこの問題を不良設定の逆問題(ill-posed inverse problems)と呼んでいます.
タイトル
早速論文のタイトルから見ていきましょう.日本語で直訳すると次のようなります.
サイノグラム合成と予測による自己教師付き学習ベースのトモグラフィ
貢献点
メインの貢献は次の3点になります.
・自己教師ありトモグラフィ再構成を提案し,学習ベースとモデルベースのアプローチのメリットを両立させた
・トモグラフィにおける不良設定問題(ill-posed problems)に関するいくつかの実験設定において,SoTAの性能を示した
・提案フレームワークをいくつかの逆問題(sinogram extrapolation, inpainting, super-resolution, and denoising)で実演
関連研究
関連研究として挙げられているのは,トモグラフィ再構成(tomographic reconstruction)に関する文献であり,これは,1970年以前に発明され,医療や材料・地球科学,工業応用,セキュリティへの応用が進められた事例の紹介から始まっています.また,computed tomographyはいくつかのアプローチが提案されていて,Filtered Back-Projection(FBR)ではラドン変換を用いて逆問題を解く高速処理が売りのアプローチをとっている一方で,撮影の回数が少ない悪い設定の場合,再構成の質が低下してしまう問題が指摘されています.また,2つ目のグループとして,Algebraic Reconstruction Technique(ART)やSimultaneous Algebraic Reconstruction Technique(SART)があり,これらは離散的定式化により解いています.これらのアプローチは,正則化項を組み合わせた最適化問題として考えることができ,ill-posed tomographic problemsのsparse viewsやlimited anglesやsuperresolution tomographyやdynamic tomographyの問題に適用されています.近年ではAIの発達により,深層学習ベースのアプローチをcomputed tomography分野に組み合わせる手法が提案されてきています.使われ方としては,(1) 再構成における不良設定問題を解くため,(2) 再構成されたオブジェクトの質を向上させるため,(3) 微分可能なforward modelがネットワークに含まれている場合の学習を行うため,の3つに使われていることがある.深層学習ベースの大きな欠点としては,学習を行うために巨大なデータベースが必要であることが挙げられます.さらに,特定の一つのアプリケーションに特化させて学習されたネットワークが他のドメインに移しにくいという点が挙げられる.このため,本研究では,教師なし学習アプローチ(self-supervised learning-based, SSL)を採用しました.
また,座標に基づく再構成(coordinate-based representations)に関する文献もまとめられています.伝統的なcomputer vision tasksでは,画像やボリュームは,pixel(2D)かvoxels(3D)で表現されています.この革新的なパラダイムとしてcoordinate-based representation(CBR)が提案され,CBRは画像やボリュームの中の関心のある(重要そうな)信号をmultiple-layer perceptron(MLP)を用いて座標で表現する.そして,CBRは3D再構成,3Dシーンモデリング,セグメンテーションやピクセル合成に用いられている.Mildenhall et al. はcontinuous implicit representationに基づくneural radiance fields(NeRF)をビュー合成タスクのために提案されました.ここでは,Positional encodingとre-direction conditioningによるテコ入れを行い,高周波情報でシーンを再構成することに成功しました.Tancik et al.はpositional encodingのアイディアをより一般的なフーリエ特徴に落とし込みました.
概要
さて本研究の概要から見ていきましょう.論文のFigure 2を転載します.
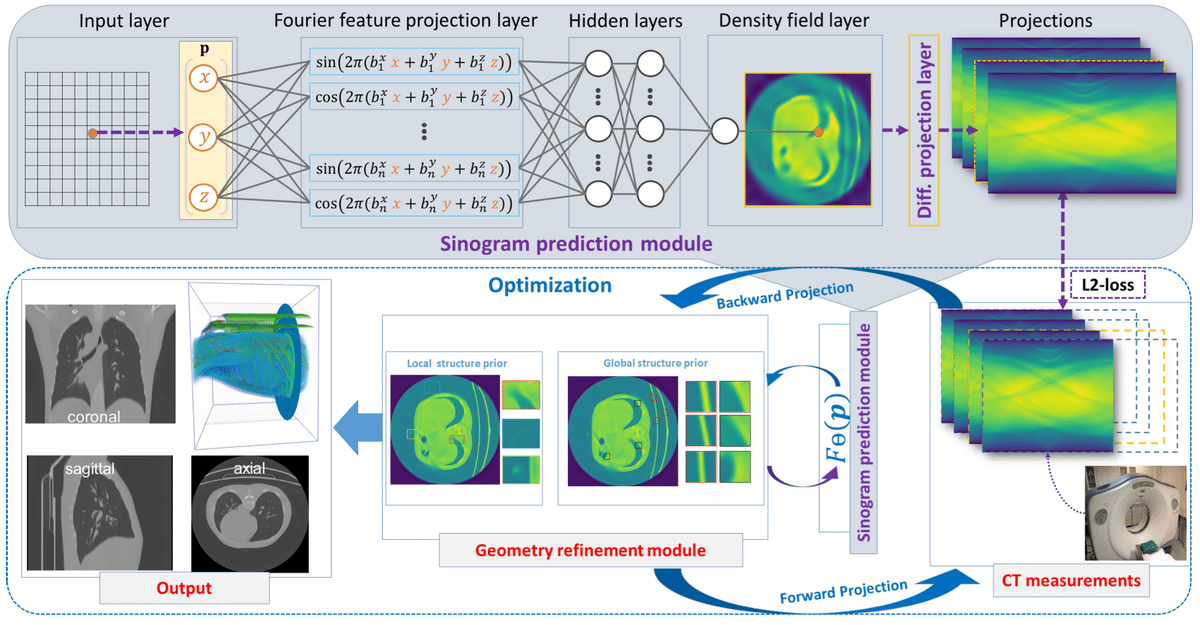
提案のフレームワークは論文中でIntraTomoと呼ばれており,これは2つのモジュール,sinogram prediction moduleとgeometry refinement stageで上図でいう青グレーで囲われた範囲がsinogram prediction moduleで,outputひとつ手前がgeometry refinement stageになっています.
一旦ここで中断します
この記事が気に入ったらサポートをしてみませんか?