
[論文紹介]Transformerがうまくいっているのはなぜなのか? [ICML23]

Transformerがうまくいっているのはなぜなのか?
結論:入力に依存し,重要な単語(トークン)を選択し,意味のある情報を取捨選択できるため
本研究は東大の鈴木大慈先生の下で行われている研究であり、数学を用いてTransformerの根幹を理解することを目的としているようです.
さて,論文の詳細は以下になります.
タイトル:Approximation and Estimation Ability of Transformers for Sequence-to-Sequence Functions with Infinite Dimensional Input
著者:Shokichi Takakura, Taiji Suzuki
機関:Department of Mathematical Informatics, the University of Tokyo, Center for Advanced Intelligence Project, RIKEN.
会議:ICML23
arXivのリンクは以下になります.
本記事では,上記論文を初見で読みながら内容をまとめていくスタイルをとっています.このため,論文を精読してまとめたというよりは流し読みしながらメモ程度にまとめた記事になっています.このため,より詳細を知りたい方は他のブログを漁ってみるか,ご自身で論文をご確認いただければと思います.
早速論文のタイトルから見ていきましょう.日本語で直訳すると次のようなります.
「シーケンス・トゥ・シーケンス関数の無限次元入力に対するトランスフォーマーの近似と推定能力」
ChatGPTやBERTなどの大規模言語モデル(LLM)では,長い文章を入れたとしてもその文の意図を汲み取って質疑応答や固有表現抽出など,様々なタスクに対応可能であることが知られています.ここで,LLMはどのようにして文章を理解し,出力へ繋げているのであろうかという疑問が生じます.このようなLLMの不思議な挙動を実験的に報告する論文はいくつか報告されている一方で,その背後にある理論的なところを説明する論文はごくわずかです.そこで本論文では,数学を用いてtransformerを近似し,なるべくシンプルな数式でその挙動を理論解析することに挑んでいます.
次にアブストラクトを見ていきましょう.
Transformerネットワークは、自然言語処理やコンピュータビジョンなどの様々な応用において大きな成功を収めているにもかかわらず、その理論的側面はよく理解されていない。本論文では、無限次元入力を持つ配列間関数としてのTransformerの近似と推定能力を研究する。入力も出力も無限次元であるが、対象関数が異方的な滑らかさを持つ場合、Transformerはその特徴抽出能力とパラメータ共有特性により、次元の呪いを回避できることを示す。さらに、入力によって滑らかさが変化する場合でも、Transformerは入力ごとに特徴量の重要度を推定し、重要な特徴量を動的に抽出できることを示す。そして、Transformersは平滑度を固定した場合と同様の収束率を達成することを証明した。我々の理論結果は、高次元データに対するTransformersの実用的な成功を裏付けている。
本アブストより,本研究のポイントは,「無限次元入力を持つ配列間関数としてのTransformerの近似と推定能力」の理解であることが分かります.さらに読み進めると,「入力も出力も無限次元であるが、対象関数が異方的な滑らかさを持つ場合、Transformerはその特徴抽出能力とパラメータ共有特性により、次元の呪いを回避できることを示す。」と書いてあります.ここで出てくる次元の呪いというのは,データ次元が増えた場合,データの空間がスパース(疎,スカスカ)になる現象を指します.具体的には,高次元のデータ空間では,データ点同士の距離が互いに遠くなり,同時に次元の増加に伴い必要なデータ量が指数関数的に増加するため,モデルの学習や推論が困難になる傾向があります.視覚化すると次のようなイメージです.
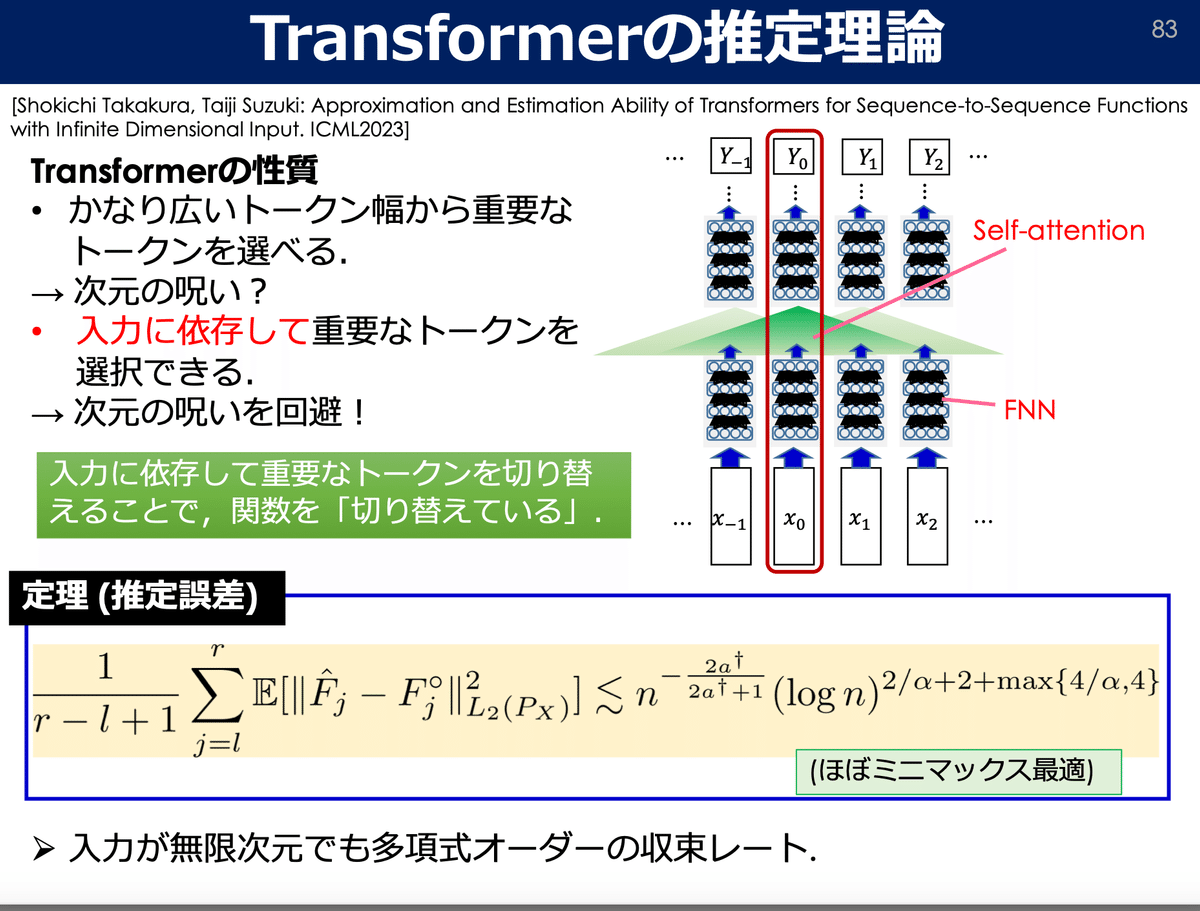
さらに,「入力によって滑らかさが変化する場合でも、Transformerは入力ごとに特徴量の重要度を推定し、重要な特徴量を動的に抽出できることを示す。」と書いてあることから,入力の長さや内容が変化した場合でも(例えば短文長文でも,ニュース記事でも論文でも),transformerは入力ごとにどの単語(トークン)が重要かを見極めて意味を動的に捉えることができると述べられていることが分かります.筆者は上記transformerの柔軟な挙動を理論的に示せていることを主張している点に本論文の面白さを感じました.
さらに,イントロダクションにまとめられている本研究の貢献を見ていきましょう.
・我々は、混合または非等方的な滑らかさを持つシフト不変関数の近似および推定誤差の収束速度を導出します。我々は、これらの誤差が目標関数の滑らかさにのみ依存し、入力および出力次元には依存しないことを示します。つまり、次元が無限であっても、Transformersは次元の呪いを回避できることを意味します。
・各座標の滑らかさ、つまり各特徴の重要性が入力によって変化する状況を考えます。そして、固定された滑らかさの場合と同様の収束速度を導出します。
本研究の貢献は2つに分かれており,1つ目に,推定誤差の収束速度の導出により,これらの誤差が目標関数の滑らかさのみに依存している点を明らかにしたこと=transformerは次元の呪いを回避できる.2つ目に,滑らかさ(平滑度)が固定の場合から,各特徴の重要性が入力によって変化する場合に拡張できたことが書かれています.この部分より,本論文のコアは,「誤差が目標関数の滑らかさのみに依存する」ことを示したことだと分かります.
ちょっと時間がなくなってきたので,最後に鈴木先生ご作成のスライドより転載した画像を貼って一旦説明を終了したいと思います.
この記事が気に入ったらサポートをしてみませんか?