
【実験】Claude 2は本当に10万トークンをさばけるのか?データ解析/コード生成能力は?

Claude(クロード)というのは、Open AIのGPTのライバルであり、Anthropic というAIスタートアップによって開発された大規模言語モデル(以下、LLM)で、少し前にClaude 2という最新版が発表され、現在(2023年7月30日時点)、ベータ版として公開されており、アメリカとイギリスでのみ利用可能となっている。
せっかくイギリスに住んでるので、ちょっと試したいなぁと前から思っていたにも関わらず、色々と他にも試したいことがあり、放置していたのだが、今回少し時間を取って、検証してみたので、本記事でその結果を報告していきたい。
Claudeの概要
簡単にClaudeについて紹介しておくと、現在、様々なLLMが出てきているが、このClaudeの性能は、GPT-3.5程度と言われており、日本語も扱える。また、様々なプロダクトにも採用されており、Notionにも、Claudeが組み込まれているようだ。
そして、このClaudeの一番の大きな特徴は、最大10万トークンを扱えるということである。また、最新版のClaude 2では、コード生成機能や計算能力など全体的に性能が改善されているようで、今回、この辺も合わせて検証していこうと思う。
トークンって何?
ここで、まずトークンについて説明しておく。(ご存じの方はスキップ)
LLMでは、入力された文章が、AIが理解しやすいトークンという形に分解されて処理されるが、単に1文字もしくは単語が1トークンというわけではない。
そして、言語によって数え方が異なるのでややこしい。
わかりやすいのは、OpenAIが提供しているTokenizerというトークン数をカウントするツールで実際に試してみることだ。
例えば、上記の説明を日本語のまま入力すると、こういう結果になり、文字数(130)より、トークン数(168)は多くなる。

一方、これを英語に翻訳して入力すると、こうなる。見れば分かるが、文字数(310)は多いのに、トークン数(64)は日本語に比べて圧倒的に少なく、ほぼ1単語=1トークンのようなイメージである。

LLMでは、基本的に、トークンごとに、次にくるものを予測していくのだが、英語などの場合、単語間にスペースがあるので、基本的に単語ベースで、次にくるものを予測していくことができる。一方、日本語のように、スペースが入って来ない場合、ほぼ文字単位で予測していくことになるため、上記のようにトークン数が多くなってしまう。
トークンの計算数は、モデルごとに異なってしまうので、これといった計算式は存在しないのだが、この記事で、OpenAIの各モデルのトークン数と対応する日本語文字数がまとめられているので、だいたいの目安にはなると思う。

最大トークン数が多いと何がいいの?
では、このトークン数が多いと何がうれしいのか。
LLMでは、一度に扱うことができるトークン数がモデルによって制限されている。
ここで注意だが、これは入力だけでなく、出力も含めた1往復分の合計トークン数ということだ。
例えば、OpenAIが提供するGPT-3.5の標準モデルでは、最大4096トークンとなっている。(各モデルの最大トークン数はここで確認可能)
この場合、たとえば、入力で2000トークン消費した場合、出力(レスポンス)は2096トークンまでしか使えないことになる。
ChatGPTを使っていて、たまにレスポンスが途中で切れてしまったという経験をしたことはないだろうか。それはこれが原因なのである。つまり、入力トークン数が多すぎて、レスポンスに必要なトークン数が足りず、途中で切れてしまうのである。
つまり、最大トークン数が大きければ、その分、多くの情報を入力に使うことができるのである。そして、Claude 2は、最大10万トークンをサポートしており、上記のGPT-3.5の4096トークンと比べて、いかにこの数字が大きいかが分かるだろう。(ちなみに、GPT-4には、最大3万2千トークンというモデルも存在する)
なお、最近Metaが発表した、オープンソースのLlama 2も、最大4096トークンのようだ。(Google Bardは不明)
Claude 2を触ってみる(星の王子さま)
やっと、ここからが本題なのだが、実際に、この大きな特徴である10万トークンを体験していきたい。
Claude 2では、ファイルを最大5つ(各ファイルのサイズは最大10MBまで)、形式は、PDF、TXT、CSVなどがサポートされている模様。

それで、実験するにあたって、まず大量の文章が必要なのだが、とりあえず、今回は青空文庫にある文章データを利用させてもらった。
対象は何でも良かったのだが、とりあえず、サン=テグジュペリの「あのときの王子くん」(星の王子さま)をチョイス。
上記ページからテキスト版をダウンロードして、作者と訳者の部分だけ削って突っ込んでみたら、ちゃんとサマってくれた。

ただ、作者名や本のタイトル(しかも、別の有名な方のタイトル)を出してきたので、本当にこの内容を解析して出してきたのか怪しい。
というわけで、ファイル名を推測できない名前に変更し、タイトルもテキストから削除して、新規チャットとして再度トライしてみたところ、一応、ちゃんとインプットした内容だけから、サマリを作ってそうなレスポンスを返してきた。

Claude 2を触ってみる(無人島に生きる十六人)
ただ、有名な作品(特に海外)だと、既に学習データとして使われてそうだし、国内の作品で、適当に以下の作品を選んで、もう一度実験。
須川 邦彦、無人島に生きる十六人
すると、リミットを43%超過しているというメッセージが表示されてしまった。実際、文字数をカウントしてみると、10万文字を超えていたので、これは仕方ない。
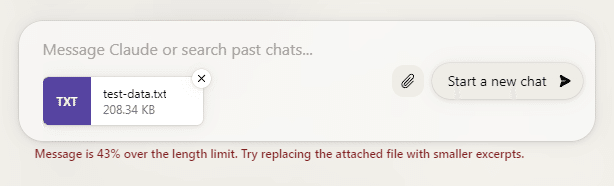
何回か試しつつ、最終的に7万4千文字程度に削った。削ったのは冒頭のタイトルや青空文庫のフォーマット説明、あとは後半をばっさり。
その結果がこちら。(処理に1分程度かかった)

内容的には、ちゃんと中身を解析してるっぽい。
さらに、PDF版も試してみたが、これも大丈夫そうだ。

さらに、削って後半部分もPDF化して、あげてみたところ、トークン数の制限にひっかかってしまった。(下の画面の一番下にエラーメッセージが表示)
やはり、最初にあげたファイルの内容もしっかりコンテキストとして引き継がれているらしい。

ChatGPTのCode Interpreterでも実験してみる
では、上記と同じデータを、ChatGPTのCode Interpreterに食わせたらどうなるか実験してみた。(Code Interpreterについては、この記事を参照。)
まずは、無人島に生きる十六人のPDFファイルで実験したところ、どうやら日本語だとうまく読み込めない模様。

というわけで、今度はテキストファイルを食わせてみたら、答えが返ってきたのだが、作者やタイトルが間違っており、内容もあまり解析できていない感じ。

上のShow workを展開すると、実際に生成されたPythonプログラムとその実行結果が表示されるので、内容を確認してみると、ちゃんとファイルの中身は読み込めているものの、最初の1000文字のみしか読んでいないことが判明。これだと、たしかに上記のようなサマリーになってしまうのは納得。

というわけで、最後まで読んでくれるようにお願いしてみる。ちょっと別作業をしていて時間が空いてしまったため、セッションが切れて、最初にアップロードしたファイルがなくなってしまったようで、再度ファイルをアップロードさせてみたところ、以下のようなレスポンスが返ってきた。
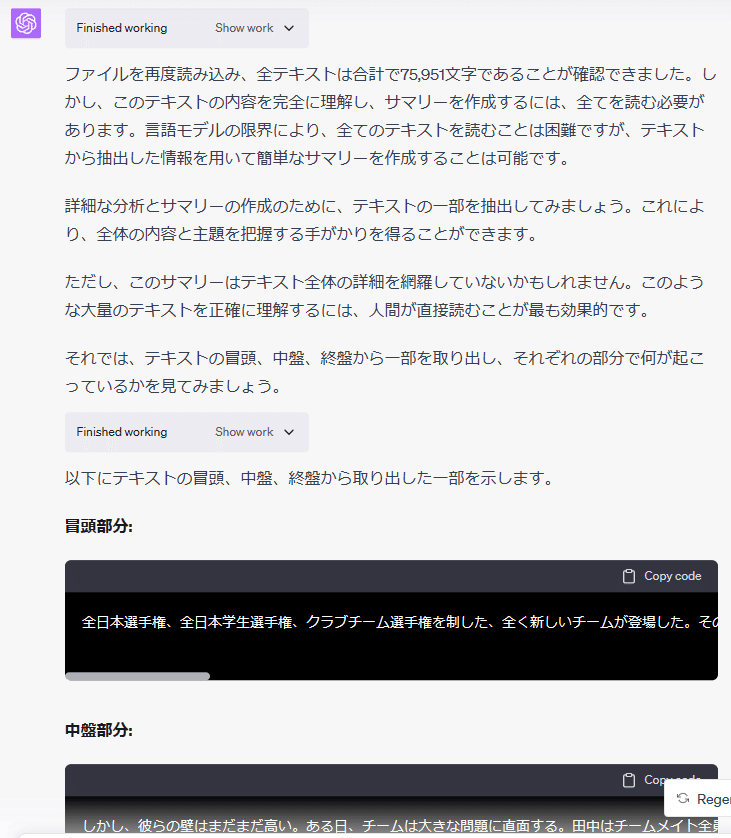
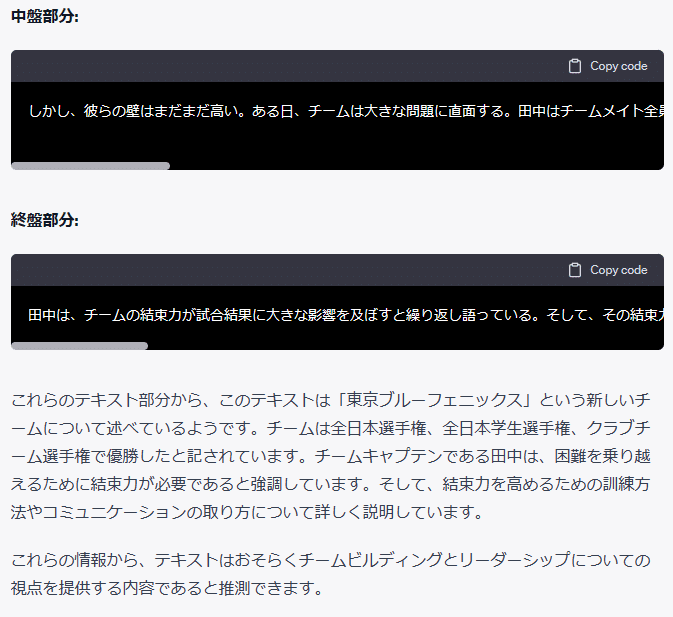
GPT-4の最大トークン数は、8192なのだが、やはり、全部読んでくれない。その代わり、冒頭、中盤、終盤を部分的に読んで、それぞれサマリして、そこから全体のサマリをすることを提案してきて、実際にやってくれたのだが、見事に的外れのサマリを返してきた。
この辺は、やはり最大10万トークンをサポートする、Claude 2に軍配が上がったといえる。
Claude 2のデータ解析能力を検証
では、コード生成能力についてはどうだろうか。
今回利用したのは、以下のツイートで中島聡さんが参照していたアメリカのCovid関連のデータ。
絶好の機会なので、ここで「code interpreter教室」を開きます。リンクのページのデータを活用して、貼り付けたグラフを作ってください。 #メルマガのネタhttps://t.co/lqMfOHVuUm pic.twitter.com/w8ieUJnqJk
— Satoshi Nakajima @NounsDAO 🇺🇦 (@snakajima) July 8, 2023
ただ、このデータをそのまま上げると、トークン数の制限にひっかかってしまい、エラーメッセージが表示されてしまった。仕方なく、がっつり削って、上げてみたら、こういう反応が返ってきた。


どうやら、グラフ表示はしてくれないが、内容はしっかり解析してくれている模様。
Code Interpreterにデータ解析をやらせてみる
では、Code Interpreterに同じデータを解析させたらどうなるか。今回、データをカットせずに、オリジナルのデータを食わせて実験してみた。
すると、こんな感じで、かなり詳細に分析し、さらにグラフ表示までやってくれた。



これは、さすがにCode Interpreterの方が能力は高いと言っていいだろう。しかも、勝手に解説しながら、ステップごとに進めてくれるし、データをどのように扱っているのかをコードレベルで確認できるのが、素晴らしい。
Claude 2のコード生成能力はいかに?
最後に、Claude 2にコードを書かせてみた。こちらも2になって能力が上がったそうだが、実際のところはどうか。
先程の実験で使ったデータをそのまま利用し、グラフ表示するコードを書かせてみたところ、ちゃんとコードを書いてきた。


これをそのまま実行してくれたら最高なのだが、そこまではやってくれないので、自前で実行してみたら、エラー。
そのエラーをそのまま投げて、デバッグさせてみたが、その回答もあまり頼りにならない。
試しに、このコードとエラーメッセージをそのまま、Code Interpreterに突っ込んでデバックさせてみたところ、バッチリコード修正してくれた。

時間が空いてしまったせいか、セッションが切れてしまい、グラフ表示まではできなかったが、自前で実行したら、見事一発で解決!


この辺は、さすが、Code Interpreterといったところか。いやはや、頼りになりますな。
まとめ
というわけで、今回、Claude 2について検証してみたが、やはり10万トークンという数字は伊達ではないということが分かった。用途としては、やはり、まとまったデータを突っ込んで、それをベースにレスポンスを返すというような、QAシステム的な使い方が一番活躍しそうである。
あとは、自社システムのソースコードを全部突っ込んで、それを基にリファクタリングやデバッグとかさせても面白いかもしれない。(つかそういうのあったら、すげー欲しい)
一方、データ解析やコード生成については、まだOpen AIのCode Interpreterに分があると言っていいのではないだろうか。この辺は、今後のさらなるアップグレードに期待したいところである。
今回、基本のチャット性能については、あまり試せていないので、また時間があったら、この辺、検証してみたい。
よろしければサポートお願いします!すごく励みになります!