AWS GlueでFireDucksを使ってPandasを高速化する

本記事はFireDucksユーザー記事シリーズの第3弾です.本記事はアリス様に執筆して頂きました.
AWS Glueはデータ統合サービスで、データの抽出、変換、ロード(ETL)を簡単に実現します。世界中の企業で人気があります。
一方、Glueのサービスは比較的高価であるため、日々大量のデータを処理する必要がある場合、コストを削減するためにツールのパフォーマンスをチューニングに苦労します。
NEC研究所からFireDucksベータ版が無料公開されています。他の高速化ライブラリと比較して、Pandasとの互換性が最も優れています。
この記事では、FireDucksを使用してGlueでのPandas作業の高速化を行う手法を記載します。
AWS Glueでの使用
Step 1. S3上にデータセットの準備
AWS Glue でデータセットを使用するには、まずデータセットを S3 に配置する必要があります。
今回Demoのため、一般公開な地震に関するデータセットをkaggleからダウンロードします。
Name: Historical earthquakes registered in the world (source :USGS)
Size: 608.1 MB (raw csv)
Source: https://www.kaggle.com/datasets/danielpe/earthquakesこのデータセットは USGS からクロールされた世界中の地震センサーのデータようですね。
ダウンロードしたファイルを解凍し、こちらの CSV `(consolidated_data.csv 608.1MB)` を取得して S3 にアップロードします

Step 2. Glue Jobの準備
AWS Glueの主要なJobには3つの種類があります。 「Visual ETL」は今回のケースには適していないため、ここでは直感的に使用するために、「Script editor」より「Notebook」の方が良いです。
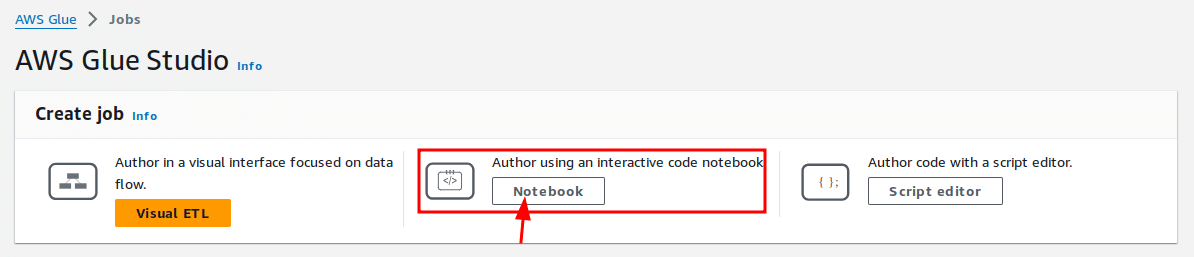
次は簡単な初期設定です。

他の環境で用意されたノートブックの作業領域(ipynb)がある場合は、ここにアップロードして直接使用できます。
今回のDemoには何もないので、Optionsには「Start fresh」を選択します。
ここでは新規でも AWS が簡単な例を示しますが、今回のDemoには必要ありませんので、まず右上隅にあるゴミ箱サインボタンを繰り返しクリックしてすべて削除します。
その後、Glue Job特有のmagics記号を使用して、正式なJobを定義します。
%idle_timeout 30
%glue_version 4.0
%worker_type G.1X
%number_of_workers 2
%additional_python_modules fireducks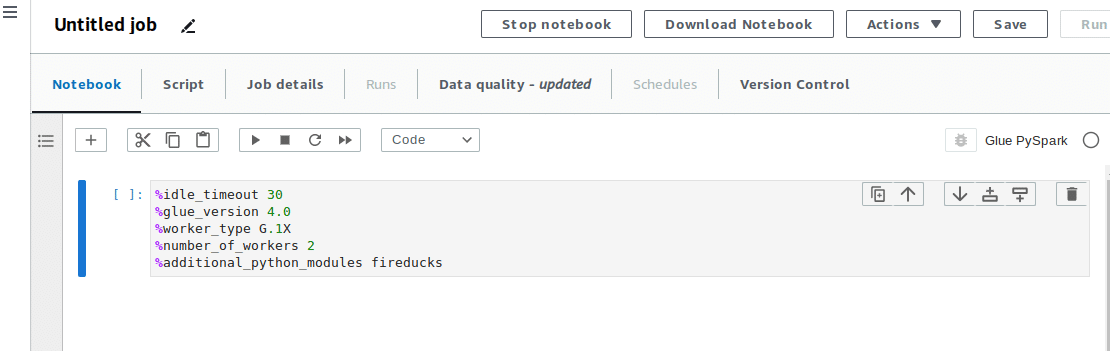
additional_python_modules を使って、Glue環境本来以外の Pythonライブラリを導入できます。```pip install```相当な機能ですね。
(内部的な動きはその通りpipを呼び出して、ライブラリをPyPIからAWS内部のリポジトリミラーから取得します)
%additional_python_modules fireducksglue_version は今回最新版4.0を指定します。
worker_typeとnumber_of_workersには最小限にG.1Xと2に指定しましょう。
idle_timeout は30分に定義します。念の為、不注意で必要のない支出が発生するのを防ぎます。(タイムアウト設定しないとGlueは開けたままでも料金を計算しますよ。ちなみに、デフォルトは2880分、48時間です。一番安いJobタイプG.1Xでも一回の不注意でおよそ 48 * 0.44 * 2 = 42.24ドル = 6262 日本円を台無しになる)
他のmagics記号に関する公式説明はここ (Jupyter Magics) にご参照可能です。
Job定義を再チェックし、問題がなければ、ここに実行ボタンをクリックします。

次に左上のプラスボタンをクリックしで、新しいCellを作ります。
Notebookにおける「セル」(Cell) は、コードやテキストを含む独立したブロックです。Notebookは対話型の環境で、セルごとにコードや説明を入力し、実行することができます。
Cell内で今回使用するライブラリをimportする。
import pandas as pd
import fireducks.pandas as pd2
import timeそして、実行します。
Glueは初めで実行のCell (Job定義用のCell以外) にJob環境を実際の初期化を実施します。
初期化は少々時間かかりますので、以下のコメントが表示されるまでしばらくお待ちください。
Session xxxxxxxx-xxxx-... has been created.
これでJobの準備は完了しました。実行を行うと料金が発生します。
Step 3. FireDucksの利用
同時比較のために、生PandasとFireDucks両方importします。
生Pandasを 「pd」 と名付け、FireDucksを「pd2」と名付けます。
import pandas as pd
import fireducks.pandas as pd2そして、今回の地震データセットの中で、
2010年から2015年までに日本で発生した震度5単位以上、深さ10単位以上のデータを作成してみましょう。
ベンチマークために、計算の前後の時間も保存します。
したがって、生Pandasのコードは次のとおり
# Pandas procedure
_s0 = time.time()
pandas_df = pd.read_csv('s3://test-fireducks/consolidated_data.csv', delimiter=',')
c0 = pandas_df.dropna(subset=['place', 'depth', 'mag'], how='all')
c0["time"] = pd.to_datetime(c0["time"])
c0 = c0[(c0["time"] > pd.to_datetime('2010-01-01', utc=True)) & (c0["time"] < pd.to_datetime('2015-12-31', utc=True))]
pandas_result = c0[(c0["place"].str.contains("Japan")) & (c0['depth'] > 10) & (c0['mag'] > 5)]
_s1 = time.time()
print(_s1 - _s0)
print(pandas_result.shape)FireDucksのコードは次に
# FireDucks procedure
_s0 = time.time()
fireducks_df = pd2.read_csv('s3://test-fireducks/consolidated_data.csv', delimiter=',', nrows = 3272774)
c0 = fireducks_df.dropna(subset=['place', 'depth', 'mag'], how='all')
c0["time"] = pd2.to_datetime(c0["time"])
c0 = c0[(c0["time"] > pd2.to_datetime('2010-01-01', utc=True)) & (c0["time"] < pd2.to_datetime('2015-12-31', utc=True))]
fireducks_result = c0[(c0["place"].str.contains("Japan")) & (c0['depth'] > 10) & (c0['mag'] > 5)]
fireducks_result._evaluate()
_s1 = time.time()
print(_s1 - _s0)
print(fireducks_result.shape)ここに、FireDucksには遅延実行の特性あるので、実際の処理の時間が計測のため、
fireducks_result._evaluate()が必要です。```_evaluate()```に関する詳細公式からの説明はここにFireDucksの_evaluateご参考ください。
※ また、現時点AWS Glueリポジトリ中のFireDucks (0.7.1)はS3に正式な対応はまだないですので、ここにFireDucksのfallback特性を利用しで、read_csvにnrowsを指定するのトリックを使ってS3からデータを取得する。
PyPI からの FireDucks 最新版 (0.9.6)にはこのトリックが必要ないですが、AWS社はまだGlueリポジトリを更新されていないためインストールできないです、しばらく待つしかないですね。
それでは、実行した結果を見てみましょう。

FireDucks は普通Pandas よりも約 10 秒早くなります。

例えば企業様は似ている統計作業を 1 日に 1000 回実行する必要がある場合、
1 か月で AWS Glueのコストを 10 * 1000 * 30 / 60 * 0.44 * 2 = 4400ドル = 653,626 日本円 = 約65万円?!節約できます。
記事を書く現時点、FireDucks公式にはAWS Glueでの正式対応はまだないですので、
これからもっと素晴らしい成績を期待できますね!
※ AWS公式サイトの説明から、デモンストレーションに用いたインスタンスは ```G.1X -> 4 vCPUs, 16 GB of memory``` 。また、仮想CPUコアなので、 パフォーマンスの結果は代表性ないの場合もありますので、ご了承ください。
AWS Sagemakerでの使用
ところで、AWS Sagemaker での FireDuck の使用について話しましょう。
SagemakerはAWSが提供する機械学習(深層学習)のプラットフォームです。
データマイニングツールとしては、AWS Glue よりも自由度が高く制限が少ないです。
AWS Sagemakerでの使用するデータセットはS3から取得必要なく、普通にローカルでアップロードしたり読み取ります。FireDucksにはもっとも相性が良いと思います。
ここで試してみましょう。
Step 1. データセットの準備
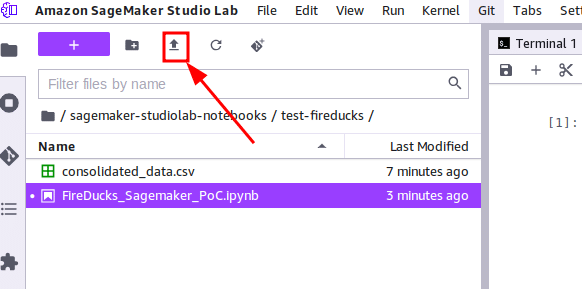
Sagemaker データセットの準備は非常に簡単です。左側のパネルにあるこのボタンをクリックするだけローカルで直接アップロードできます。
Step 2. FireDucksのインストール
Sagemaker環境は完全なLinux環境なので、
NotebookのCellに以下のコマンドを実行すればインストールできます。
!pip install fireducks
また、使用は
import fireducks.pandas as pd2だけです。
Step 3. FireDucksの利用
データセットをローカルから取得できるため、S3 はもう必要ありません(nrowsトリックも必要ないです)。
# Pandas procedure
_s0 = time.time()
pandas_df = pd.read_csv('consolidated_data.csv', delimiter=',')
c0 = pandas_df.dropna(subset=['place', 'depth', 'mag'], how='all')
c0["time"] = pd.to_datetime(c0["time"])
c0 = c0[(c0["time"] > pd.to_datetime('2010-01-01', utc=True)) & (c0["time"] < pd.to_datetime('2015-12-31', utc=True))]
pandas_result = c0[(c0["place"].str.contains("Japan")) & (c0['depth'] > 10) & (c0['mag'] > 5)]
_s1 = time.time()
print(_s1 - _s0)
print(pandas_result.shape)# FireDucks procedure
_s0 = time.time()
fireducks_df = pd2.read_csv('consolidated_data.csv', delimiter=',')
c0 = fireducks_df.dropna(subset=['place', 'depth', 'mag'], how='all')
c0["time"] = pd2.to_datetime(c0["time"])
c0 = c0[(c0["time"] > pd2.to_datetime('2010-01-01', utc=True)) & (c0["time"] < pd2.to_datetime('2015-12-31', utc=True))]
fireducks_result = c0[(c0["place"].str.contains("Japan")) & (c0['depth'] > 10) & (c0['mag'] > 5)]
fireducks_result._evaluate()
_s1 = time.time()
print(_s1 - _s0)
print(fireducks_result.shape)FireDucksのread_csvにfallback発生しないのため、
本来のFireDucksの`read_csv`の速度を出せます。普通のPandasよりも高速化の恩恵がありそうです。
結果を見てみましょう。
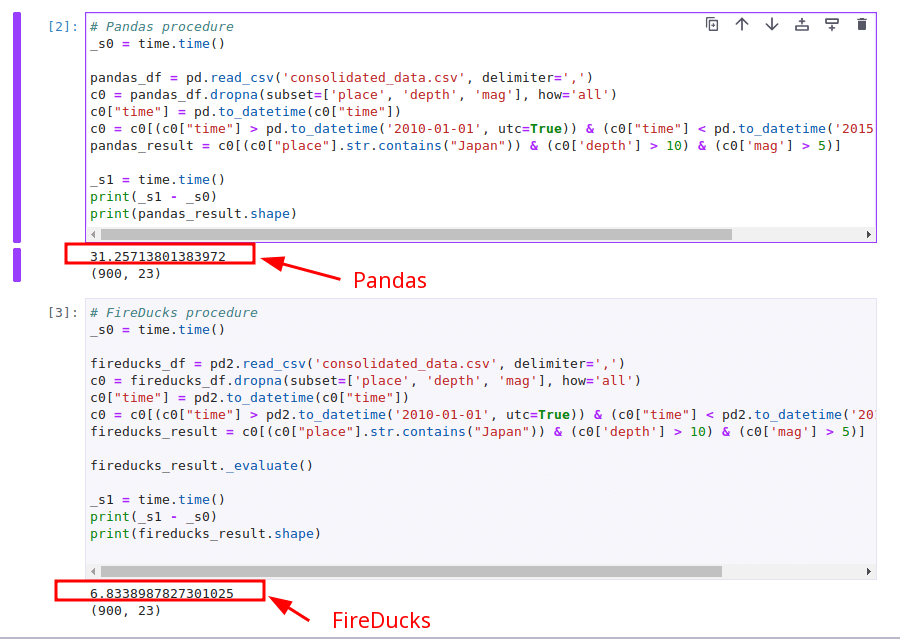
約 25 秒早くなりますね。良い結果ですね!
※ AWS公式サイトの説明から、デモンストレーションに用いたインスタンスは ```t3.xlarge: 4 vCPU, 16.0 G RAM``` 。また、仮想CPUコアなので、 パフォーマンスの結果は代表性ないの場合もありますので、ご了承ください。
この記事が気に入ったらサポートをしてみませんか?